CONVERSATIONAL PAPERS (cPAPERS)
收藏arXiv2024-06-13 更新2024-06-14 收录
下载链接:
https://huggingface.co/datasets/avalab/cPAPERS
下载链接
链接失效反馈官方服务:
资源简介:
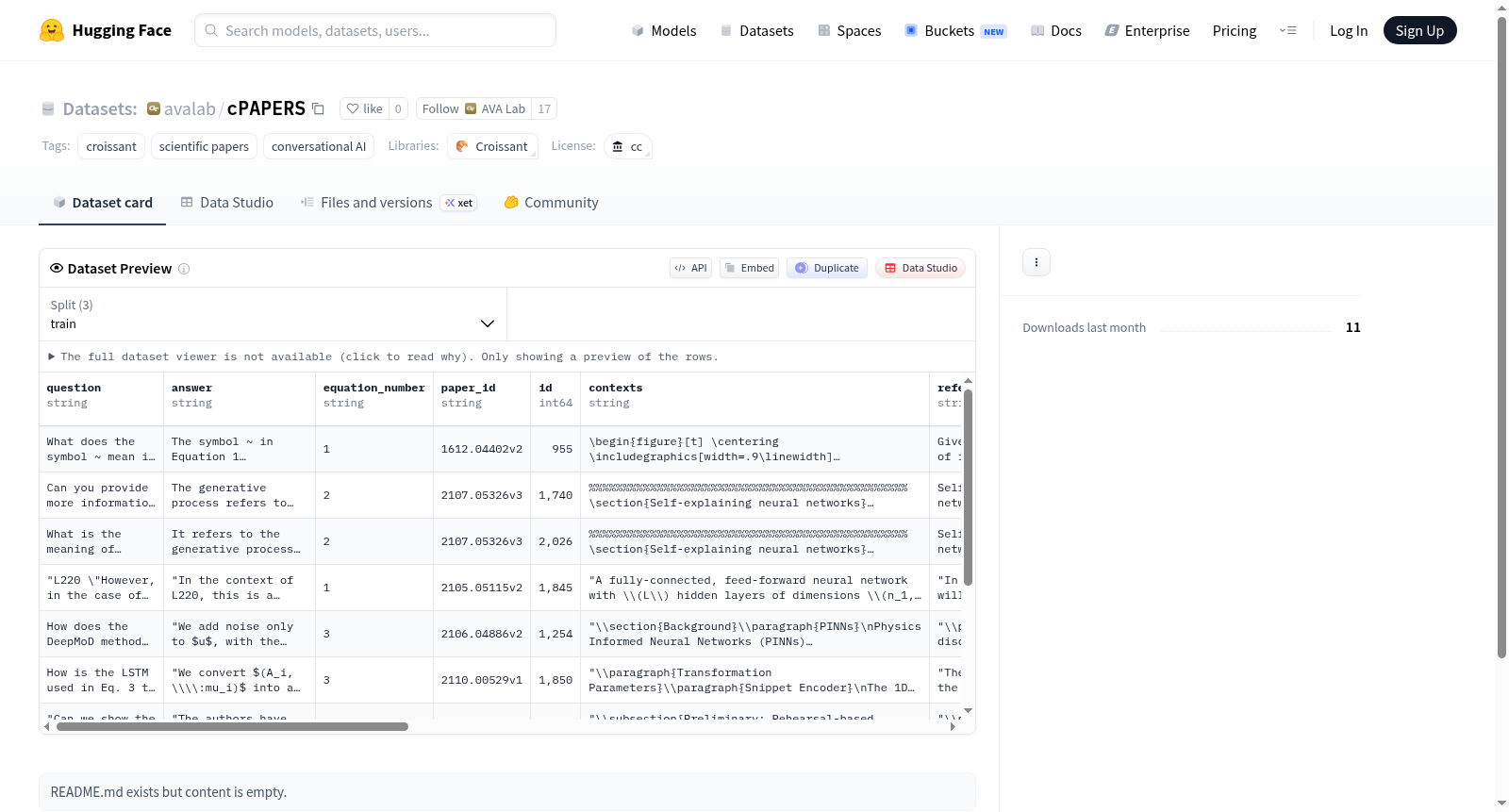
CONVERSATIONAL PAPERS (cPAPERS) 是一个包含对话式问答对的数据集,专注于科学论文中的图表、方程和表格。该数据集由佐治亚理工学院AI虚拟助理实验室创建,包含5030对问答,源自OpenReview上的评审和反驳。数据集的创建过程涉及从OpenReview收集问答对,并将其与arXiv上的科学文章相关联。cPAPERS旨在通过提供多模态、情境化的对话数据,支持开发能够理解和回应科学文档中复杂内容的对话助手。
CONVERSATIONAL PAPERS (cPAPERS) is a dataset of conversational question-answer pairs focused on figures, equations and tables within scientific papers. Developed by the AI Virtual Assistant Lab at the Georgia Institute of Technology, the dataset contains 5030 question-answer pairs derived from reviews and rebuttals hosted on OpenReview. The dataset construction workflow entails collecting question-answer pairs from OpenReview and associating them with corresponding scientific articles on arXiv. cPAPERS aims to support the development of conversational assistants capable of comprehending and responding to complex content in scientific documents by providing multimodal, contextual conversational data.
提供机构:
佐治亚理工学院AI虚拟助理实验室
创建时间:
2024-06-13
搜集汇总
数据集介绍
构建方式
在科学文献交互对话研究领域,cPAPERS数据集的构建采用了系统化采集策略。该数据集从OpenReview平台获取NeurIPS和ICLR会议的官方评审与作者回复文本,通过正则表达式筛选出涉及公式、图表的具体讨论片段。利用Llama-2-70B模型提取结构化问答对,并关联arXiv上对应论文的LaTeX源文件,通过自动化流程提取公式环境、表格代码和图像元数据。最后通过众包平台进行技术性问题标注,确保问答对具有学术讨论深度,形成包含5030个多模态对话样本的标准化数据集。
使用方法
该数据集主要服务于多模态对话系统的研发与评估。研究者可采用零样本提示或参数高效微调策略,将大型语言模型与多模态编码器结合,处理公式的LaTeX表示、表格结构化数据及图像特征。实验设置支持两种上下文使用模式:完整模态内容提供或邻近弱标注内容选择,后者通过提取目标元素相邻的公式/表格集合来平衡信息完整性与模型处理能力。评估时采用ROUGE、METEOR和BERTScore等指标,重点关注模型在专业学术语境下的推理准确性和回答连贯性。
背景与挑战
背景概述
在科学文献数量呈指数级增长的背景下,研究人员面临信息过载的严峻挑战,高效理解和整合多模态学术内容成为亟待解决的问题。由佐治亚理工学院AI虚拟助理实验室于2024年推出的CONVERSATIONAL PAPERS(cPAPERS)数据集,旨在推动面向科学文档的具身多模态交互对话系统发展。该数据集从OpenReview平台的学术评审对话中,提取了涵盖公式、图表和表格的5030组问答对,并关联arXiv预印本的LaTeX源码作为多模态上下文。其核心研究在于突破传统单模态问答局限,构建能够理解科学文档中数学表达式、可视化图表与结构化表格语义的对话智能体,为开发下一代科研辅助工具奠定数据基础。
当前挑战
cPAPERS数据集致力于解决科学文档多模态交互问答这一前沿领域的核心挑战:模型需同步解析文本、数学公式、图像与表格的复杂语义关联,并生成符合学术对话规范的连贯回应。在构建过程中面临多重技术难题:首先,从非结构化的评审回复中精准提取针对特定模态的问答对,需克服自然语言表达的多样性和模糊性;其次,将OpenReview中的序号引用与arXiv不同版本的LaTeX源码对齐时,存在因论文修订导致的多模态元素位置错位或内容失配问题;此外,科学图表格式异构性要求统一的预处理流程,而表格与公式的语义理解需超越表面符号捕捉深层逻辑关系。这些挑战共同构成了该数据集在数据对齐、模态融合与语义理解维度的核心难点。
常用场景
经典使用场景
在科学文献理解与交互领域,cPAPERS数据集为开发面向学术论文的多模态对话系统提供了关键资源。其最经典的使用场景是训练和评估能够理解并回应针对论文中公式、图表和表格的深度提问的对话模型。研究者利用该数据集构建的基线模型,通过零样本提示和参数高效微调,展示了模型在理解科学文档多模态内容并进行连贯对话方面的潜力。该场景直接回应了科研人员在快速增长的文献海洋中高效获取精确信息的需求。
解决学术问题
cPAPERS数据集主要解决了科学文档多模态理解与交互对话中的核心学术问题。它突破了以往数据集中在日常图像或单一模态的局限,首次系统性地将对话问答与学术论文中的公式、图表和表格等结构化知识源进行深度关联。该数据集为研究社区提供了基准,用以探索大型语言模型如何融合文本、数学符号和视觉信息,以支持对复杂科学概念的深度追问与解释,从而推动了面向专业领域的、情境化的多模态对话人工智能的发展。
实际应用
该数据集的实际应用场景紧密围绕提升科研效率展开。基于cPAPERS训练的智能研究助手,能够帮助科学家快速定位论文核心贡献,澄清方法论细节,并理解复杂的实验结果呈现。例如,研究人员可以直接向助手提问关于某个模型架构图的细节,或要求解释特定数学公式的推导逻辑,从而省去反复翻阅文档的时间。这类应用旨在作为人类科研能力的放大器,而非替代品,助力科学家更高效地进行文献调研和知识消化。
数据集最近研究
最新研究方向
在科学文献交互式对话领域,CONVERSATIONAL PAPERS (cPAPERS) 数据集聚焦于多模态情境对话的前沿探索。该数据集通过整合学术论文中的公式、图表和表格,构建了基于OpenReview评论与arXiv文档的问答对,推动了面向科学文档的智能助手研发。当前研究热点集中于利用大型语言模型进行零样本提示和参数高效微调,以提升模型在弱接地多模态上下文中的对话生成能力。这一方向不仅促进了科学交流的自动化支持,还为跨模态语义理解与交互式人工智能系统的发展提供了关键数据基础,对加速科研进程具有深远影响。
相关研究论文
- 1cPAPERS: A Dataset of Situated and Multimodal Interactive Conversations in Scientific Papers佐治亚理工学院AI虚拟助理实验室 · 2024年
以上内容由遇见数据集搜集并总结生成


