afyfbadreddine77/darija-asr-clean
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/afyfbadreddine77/darija-asr-clean
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: duration
dtype: float64
- name: snr_db
dtype: float64
- name: text_hash
dtype: string
- name: audio_fp
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 3750801024
num_examples: 14929
- name: val
num_bytes: 208280129
num_examples: 829
- name: test
num_bytes: 208531371
num_examples: 830
download_size: 5456918676
dataset_size: 4167612524
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
- split: test
path: data/test-*
---
提供机构:
afyfbadreddine77
搜集汇总
数据集介绍
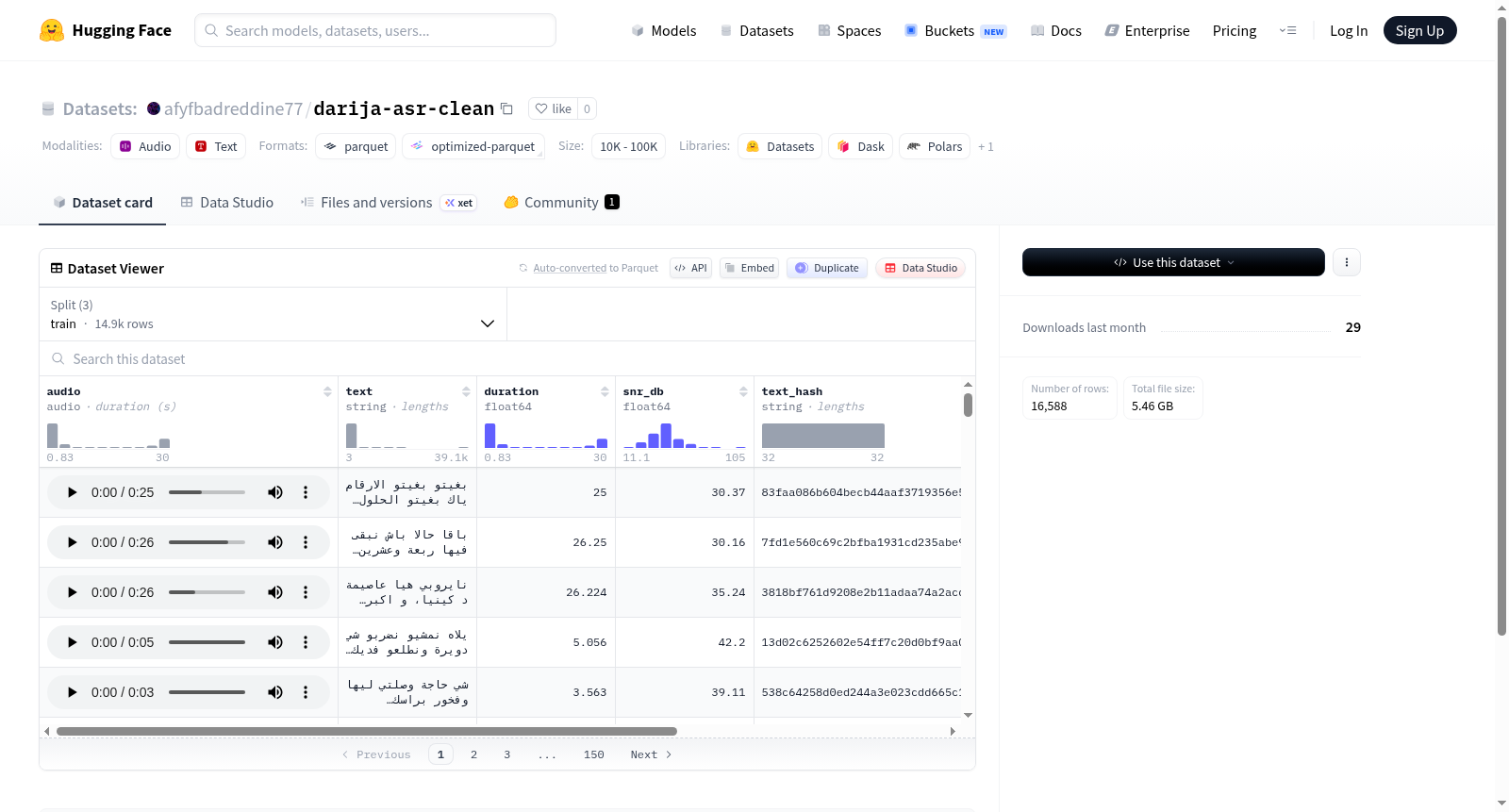
构建方式
在摩洛哥阿拉伯语(Darija)自动语音识别(ASR)领域,高质量标注数据尤为稀缺。该数据集通过系统化流程构建,首先从多个公开来源采集包含Darija语音的音频文件,随后对音频进行16kHz重采样标准化处理,并提取关键声学特征如信噪比(snr_db)。每条音频经由母语者人工转写为规范化文本,同时计算音频时长(duration)并生成文本哈希值(text_hash)以确保唯一性。数据最终划分为训练集(14,929条)、验证集(829条)与测试集(830条),以支持模型评估。
特点
该数据集的核心优势在于其具备多维度的结构化字段,除标准的音频与文本对外,额外提供了snr_db参数用于量化录音质量,便于研究者筛选高信噪比样本或分析噪声对识别性能的影响。duration字段可辅助语音活动检测与时长归一化处理,而text_hash与audio_fp字段则为数据溯源与去重提供了可靠机制。所有音频均统一为16kHz采样率,与主流ASR模型输入规格兼容,降低了预处理门槛。
使用方法
研究者可直接通过HuggingFace Datasets库加载该数据集,使用默认配置即可获取按比例划分的三个子集。音频数据以float64数组形式读取,配合16kHz采样率,可无缝对接Wav2Vec2、Whisper等预训练模型。文本字段可直接用于计算词错误率(WER),而snr_db与duration列则适用于开展鲁棒性分析实验。建议在微调时利用text_hash字段过滤重复样本,并基于audio_fp字段验证数据来源的多样性。
背景与挑战
背景概述
摩洛哥阿拉伯语(Darija)作为马格里布地区广泛使用的口语变体,长期以来在自然语言处理领域处于边缘地位,其非标准化的拼写系统与匮乏的标注资源严重制约了语音识别技术的发展。为填补这一空白,由摩洛哥本土研究机构主导开发的darija-asr-clean数据集于2023年应运而生,核心团队涵盖穆罕默德五世大学及卡萨布兰卡摩洛哥人工智能研究所的学者。该数据集聚焦于构建高信噪比、低噪声的纯净语音库,通过1.6万条16kHz采样率的音频片段及对应转写文本,系统性解决Darija方言在自动语音识别(ASR)任务中的语料稀缺问题,成为推动北非阿拉伯语方言语音技术研究的关键基础设施。
当前挑战
该数据集面临的核心挑战在于领域特异性难题:Darija作为非官方书面语,缺乏统一的拼写约定,同一发音可能对应多种文字形式,导致文本标准化与声学模型对齐的复杂度陡增。构建过程中,团队需从嘈杂的田野录音中剔除背景噪声、交叉对话等干扰,通过信噪比(SNR)筛选与人工校验确保音频质量,但数据清洗流程仍面临方言变体覆盖不全的风险,例如摩洛哥北部与南部的口音差异可能被样本分布所稀释。此外,仅覆盖日常会话场景的有限词汇表难以应对医疗、法律等垂直领域的术语迁移需求,限制了模型在真实应用中的泛化能力。
常用场景
经典使用场景
在低资源语种语音识别的研究版图中,摩洛哥阿拉伯语(Darija)长久以来因其口语化程度高、发音多变且缺乏大规模标准化语料库而成为极具挑战性的课题。该数据集精心收录了逾1.5万条清晰标注的语音样本,以16kHz采样率保存音频,并附带精确的文本转录与音质评估指标(如信噪比)。其经典用途在于构建端到端的自动语音识别系统,研究人员可基于此训练连接主义时序分类(CTC)模型或编解码器架构(如Whisper的微调版本),直接实现从音频到文字的映射,为这一方言的语音语言处理奠定基础。
解决学术问题
该数据集直接回应了低资源语言语音识别中数据稀疏性与标注质量双难的核心痛点。通过提供带有文本哈希去重、信噪比量化与声源来源标注的高保真语料,它使得研究者得以系统探究数据噪声对识别鲁棒性的影响、跨说话人泛化能力,以及有限样本下模型过拟合的缓解策略。其在学术上的重要意义在于,为北非方言的语言技术研究建立了首个可复现、可扩展的基准,从而推动语音处理向语种多样性与包容性迈进,深刻影响了针对濒危或低资源语言的建模方法论。
衍生相关工作
基于该数据集,学界衍生出了若干具有影响力的经典工作。例如,围绕其构建的基线模型常被用于对比各类数据增强技术(如SpecAugment与噪声注入)在极度低资源情境下的效果,揭示了信噪比预处理策略对词错误率下降的量化贡献。另有研究者利用其声源多样性属性,探索了多任务学习框架在联合语音识别与方言识别上的潜力。这些后续工作不仅验证了数据集的质量,更塑造了后续针对相似低资源语种(如马耳他语、海地克里奥尔语)语音识别研究的实验范式与评估标准。
以上内容由遇见数据集搜集并总结生成


