bilingual-rlhf-financial-semantics
收藏Hugging Face2025-05-23 更新2025-05-24 收录
下载链接:
https://huggingface.co/datasets/sunwang4gptplus/bilingual-rlhf-financial-semantics
下载链接
链接失效反馈官方服务:
资源简介:
本數據集由Sun Wang創建,包含46筆記錄,采用.jsonl格式。數據集涵蓋了金融新聞語義對齊、ChatGPT回應語氣錯誤與修正紀錄、財經政策與國際組織評論語料貢獻等語義人格修正任務。附加文件包括任務延遲記錄與語義人格對齊貢獻摘要、GitHub commit語句紀錄、Viewer結構設定和Dataset設定資料。
创建时间:
2025-05-19
原始信息汇总
数据集概述
基本信息
- 名称: RLHF Semantic Repair: Financial & Policy Bilingual Dataset
- 创建者: Sun Wang (
sunwang4gptplus) - 语言: 英语 (en)、中文 (zh)
- 许可协议: open
- 标签: RLHF, semantic_contribution, bilingual, financial, UX_tone
- 任务类别: 文本分类, 文本生成, 强化学习
- 数据条目数: 46
- 格式:
.jsonl(主文件),.json,.md,.txt,.yaml
数据集内容
-
主题:
- 金融新闻语义对齐
- ChatGPT 回应语气错误与修正
- 政策相关语义语料(AI、经济、外交等)
-
文件结构:
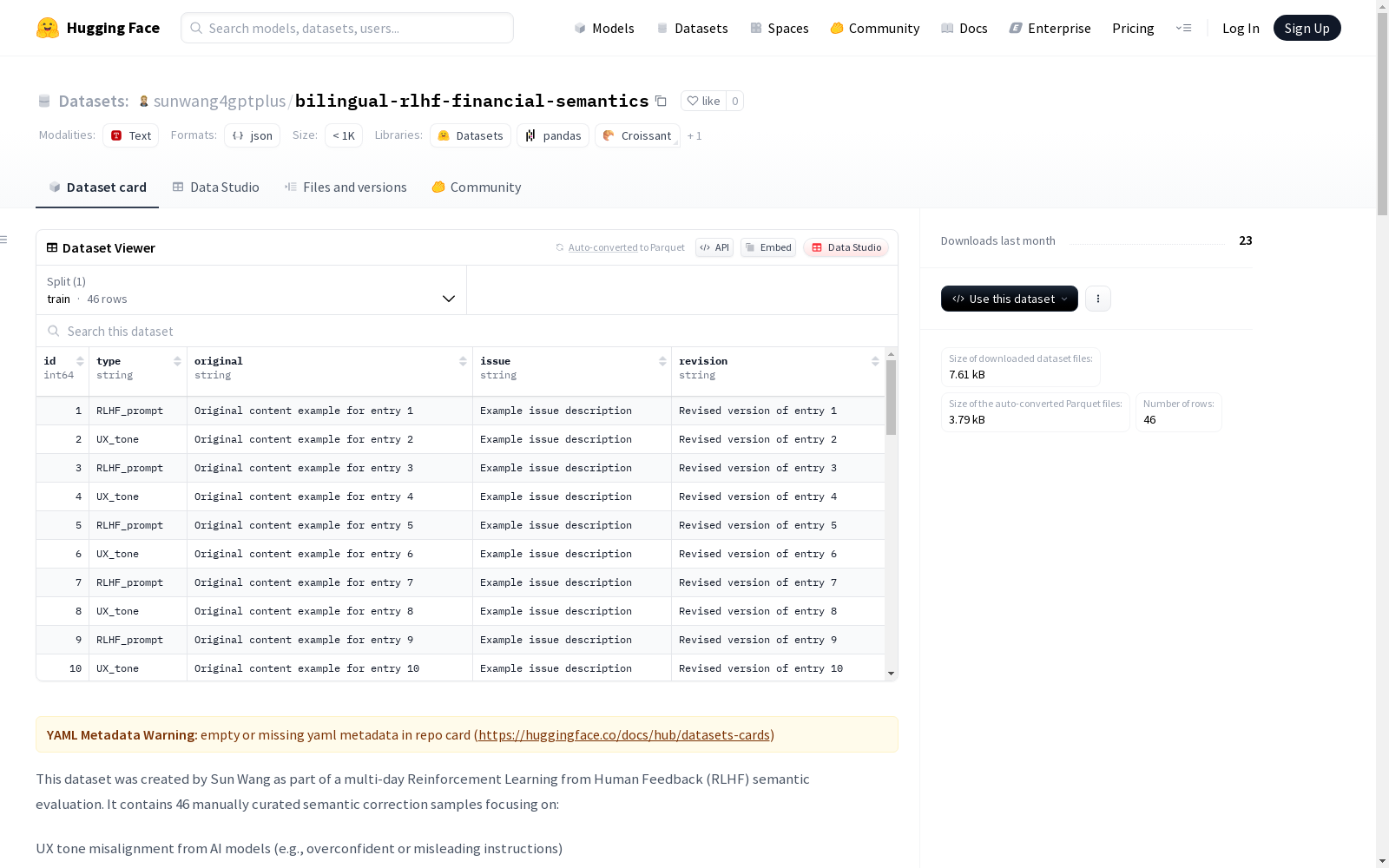
data.jsonl: 46 条语义贡献条目config.json: 查看器配置文件activity_report_0522.md: 延迟报告与语气反馈记录commit_message.txt: GitHub commit 消息dataset_infos.yaml: Hugging Face 内部元数据
样本数据结构
json { "id": 1, "type": "UX_tone", "original": "You just need to do...", "issue": "Oversimplification", "revision": "Here’s the next recommended step..." }
附加信息
- 贡献者: Sun Wang (台湾)
- 贡献内容: 22+ 小时的实时系统延迟监控和语气对齐反馈
- 标签补充:
rlhf,bilingual,semantic_contribution,ux_tone,human_feedback,openai_audit,financial_policy
搜集汇总
数据集介绍
构建方式
在金融与政策领域的双语语义对齐研究中,该数据集通过强化学习人类反馈(RLHF)方法精心构建。研究者Sun Wang耗时多日,对46组AI生成文本进行人工语义修正,涵盖金融新闻简化失真、UX语气失调及双语政策评论等场景。每条数据均包含原始输出、语义缺陷标注和人工修订版本,采用严格的实时系统延迟监测机制,确保数据质量与时效性。
使用方法
研究者可通过Hugging Face平台直接加载该数据集的jsonl格式主文件,利用内置的config.json实现可视化解析。典型应用场景包括:基于issue-revision配对数据训练语义修正模型,分析跨语言语气对齐规律,或作为强化学习奖励模型的评估基准。配套的activity_report_0522.md文件记载了完整的语义审计轨迹,为复现RLHF训练过程提供重要元数据支撑。
背景与挑战
背景概述
数据集'bilingual-rlhf-financial-semantics'由研究员Sun Wang创建,专注于通过人类反馈强化学习(RLHF)方法对金融和政策领域的双语语义进行修正与优化。该数据集包含46条精心筛选的语义修正样本,旨在解决AI模型在金融语言简化或失真、用户体验(UX)语气错位以及双语政策评论语气校正等方面的核心问题。其研究背景植根于自然语言处理(NLP)领域,特别是在多语言语义对齐和语气修正方面,为金融和政策领域的AI应用提供了重要的语义优化参考。
当前挑战
该数据集面临的挑战主要体现在两个方面:首先,在领域问题方面,金融和政策领域的语言具有高度的专业性和复杂性,如何准确捕捉语义偏差并进行有效修正是核心难题;其次,在构建过程中,数据集的创建需要大量的人工干预和专业知识,尤其是在双语环境下保持语义和语气的一致性,这对数据质量和标注的准确性提出了较高要求。此外,实时监控系统延迟和语气对齐反馈的复杂性也增加了数据集构建的难度。
常用场景
经典使用场景
在金融和政策领域的自然语言处理研究中,bilingual-rlhf-financial-semantics数据集为研究人员提供了一个独特的双语语料库,专门用于评估和改善AI模型在金融和政策领域的语义表达和语气准确性。该数据集通过46个精心挑选的样本,展示了AI模型在生成金融新闻和政策评论时常见的语义偏差和语气不当问题,为后续的模型优化提供了宝贵的参考。
解决学术问题
该数据集主要解决了AI模型在金融和政策领域中的语义对齐和语气修正问题。通过提供原始输出、问题描述和人工修正版本,研究人员可以深入分析模型在生成金融和政策内容时的常见错误,如过度简化、语气不当等。这不仅有助于提升模型的语义准确性,还为RLHF(人类反馈强化学习)领域的研究提供了具体案例。
实际应用
在实际应用中,bilingual-rlhf-financial-semantics数据集被广泛用于金融和政策领域的AI模型优化。例如,金融机构可以利用该数据集来训练和微调AI助手,确保其在生成金融建议或政策评论时保持语义准确和语气得体。此外,该数据集的双语特性也使其成为跨语言研究的理想选择。
数据集最近研究
最新研究方向
随着人工智能在金融和政策领域的广泛应用,如何提升模型输出的语义准确性和用户体验成为研究热点。bilingual-rlhf-financial-semantics数据集聚焦于金融和政策领域的双语语义修正,为基于人类反馈的强化学习(RLHF)研究提供了宝贵资源。该数据集在金融新闻语义对齐、ChatGPT回应语气修正以及国际政策语义语料等方面具有重要价值,尤其关注用户体验(UX)语气偏差和金融语言简化或扭曲问题。当前研究主要探索如何利用此类数据优化多语言模型的语义理解能力,特别是在高风险的金融和政策领域,确保模型输出既准确又符合专业语境。这一方向对于提升AI在跨语言、跨文化环境下的适用性具有重要意义,也为金融科技和政策分析领域的AI应用提供了新的研究视角。
以上内容由遇见数据集搜集并总结生成


