aymansharara/IdiomX
收藏Hugging Face2026-04-11 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/aymansharara/IdiomX
下载链接
链接失效反馈官方服务:
资源简介:
---
pretty_name: IdiomX v3
language:
- en
- ar
license: mit
dataset_type: text
multilinguality: multilingual
task_categories:
- text-classification
- text-generation
configs:
- config_name: idiomx
data_files:
- split: idiomx_train
path: idiomx_train.parquet
- split: idiomx_test
path: idiomx_test.parquet
- config_name: idiomx_high_quality
data_files:
- split: idiomx_high_quality_train
path: idiomx_high_quality_train.parquet
- split: idiomx_high_quality_test
path: idiomx_high_quality_test.parquet
- config_name: idiomx_balanced
data_files:
- split: idiomx_balanced_train
path: idiomx_balanced_train.parquet
- split: idiomx_balanced_test
path: idiomx_balanced_test.parquet
tags:
- idioms
- bilingual
- english
- arabic
- semantic-understanding
- figurative-language
- idiom-detection
- multilingual-nlp
size_categories:
- 100K<n<1M
---
# IdiomX v3: A Large-Scale Bilingual Dataset for Idiomatic Expression Understanding
## IdiomX
**A Large-Scale Bilingual Dataset for Idiomatic Expression Understanding**
**Author:** Ayman Ali Sharara
MSc Data Science & Machine Learning – DSTI
---
## Overview
**IdiomX v3** is a large-scale, semantically enriched dataset designed for **idiomatic language understanding in context**.
It provides:
- **174,956 contextualized examples**
- **12,823 unique idioms**
- **High semantic quality annotations**
- **Rich linguistic and contextual features**
The dataset supports multiple NLP tasks including:
- Idiom Detection (idiomatic vs literal)
- Context → Idiom Retrieval
- Meaning → Idiom Mapping
- Semantic Similarity Modeling
- Cross-lingual analysis (EN ↔ AR)
---
## Dataset Statistics
| Metric | Value |
|--------|------|
| Total examples | 174,956 |
| Unique idioms | 12,823 |
| Unique normalized examples | 172,481 |
| Avg examples per idiom | 13.99 |
| Reuse factor | 1.04 |
| Idiomatic | 45.55% |
| Literal | 46.92% |
| Borderline | 7.54% |
| High-quality | 77.13% |
| Medium-or-higher quality | 96.10% |
---
## Research Positioning
IdiomX v3 addresses key limitations in existing idiom datasets:
- Lack of contextual diversity
- Limited semantic validation
- Weak cross-lingual support
It provides a unified benchmark for idiomatic language understanding across multiple tasks.
---
## Key Properties
- **High lexical diversity**
- Nearly one unique sentence per row (reuse factor ≈ 1.04)
- **Balanced label distribution**
- Idiomatic and literal usage are nearly equal
- **High semantic quality**
- Majority of examples are strongly aligned with their meanings
- **Controlled ambiguity**
- Borderline cases simulate real-world uncertainty
- **Rich annotations**
- compositionality
- register
- learner difficulty
- semantic similarity scores
---
## Dataset Variants
The dataset is available in multiple configurations:
### 1. 174,956 rows Full Dataset (`idiomx`)
### 2. 123,022 rows High-Quality Dataset (`idiomx_high_quality`)
Each variant includes train/test splits.
---
## Data Sources
The dataset is constructed using:
- **Wiktionary**
- **WordNet**
- **LLM-based enrichment (example generation, semantic validation, translations)**
---
## Data Quality & Cleaning
The dataset underwent a rigorous multi-stage refinement pipeline:
- Removal of noisy and invalid examples
- Reduction of duplicate and near-duplicate sentences
- Semantic validation using embedding similarity
- Alignment between idioms, meanings, and context
- Filtering of low-quality generated samples
Key improvements in v3:
- **Very low duplication (reuse factor ≈ 1.04)**
- **High semantic consistency**
- **Controlled ambiguity to reflect real-world linguistic uncertainty**
---
## Splitting Strategy
- Train/test splits are constructed to ensure:
- Minimal sentence overlap
- Fair evaluation across idioms
- Balanced distribution of labels
---
## Key Features
- Context-aware idiomatic expressions
- English and Arabic meanings
- Semantic similarity scoring
- Quality annotations (high / medium / low)
- Balanced idiom representation (~14 examples per idiom)
---
## Notes
- Use **`example`** for modeling
- `example_raw` is provided for traceability
- `is_idiom` is idiom-level (not example-level)
- Prefer `example_usage_label` for supervised tasks
---
## Links
- HuggingFace: https://huggingface.co/datasets/aymansharara/IdiomX
- GitHub: https://github.com/aymanshar/idiomx-dataset
- Kaggle: https://www.kaggle.com/datasets/aymansharara/idiomx
- Zenodo: https://doi.org/10.5281/zenodo.19137833
---
## 📚 Citation
If you use this dataset, please cite:
Sharara, Ayman Ali (2026).
**IdiomX: A Large-Scale Bilingual Dataset for Idiomatic Expression Understanding**.
Zenodo. https://doi.org/10.5281/zenodo.19137833
```bibtex
@article{sharara2026idiomx,
title={IdiomX: A Large-Scale Bilingual Dataset for Idiomatic Expression Understanding},
author={Sharara, Ayman Ali},
year={2026},
note={Dataset and paper available on GitHub and HuggingFace}
}
```
---
提供机构:
aymansharara
搜集汇总
数据集介绍
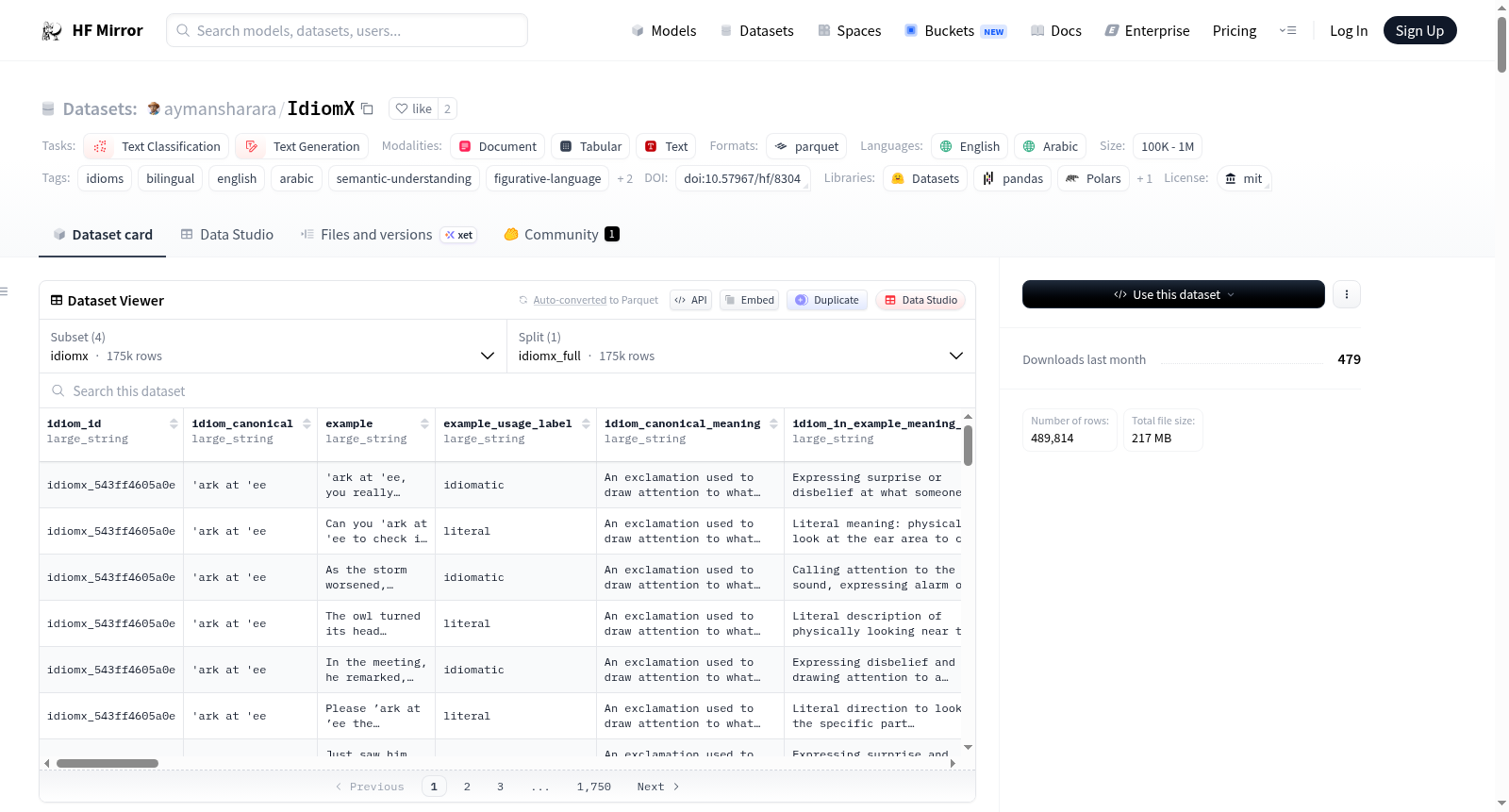
构建方式
在自然语言处理领域,习语理解因其语义的非组合性而成为一项具有挑战性的任务。IdiomX v3数据集的构建采用了多源融合与语义增强的策略,其核心数据来源于Wiktionary和WordNet等权威词典,并通过精心设计的LLM管道进行扩展与验证。该流程不仅生成了包含现代俚语和社交网络用语的新颖语料,还引入了法语作为第三语言支持,实现了英语、阿拉伯语和法语的多语言对齐。数据集经过严格的质量控制,包括去噪、去重以及基于嵌入相似度的语义验证,确保了例句与习语含义的高度一致性,最终形成了包含近17.5万条语境化例句的大规模、高质量语料库。
特点
该数据集在习语资源领域展现出鲜明的多维特性。其核心优势在于极高的词汇多样性,例句重复率极低,确保了训练数据的丰富性。数据标注体系精细完备,不仅区分了习语用法、字面用法及边界案例,还涵盖了组合性、语域、学习难度等多维度语言学标签。尤为突出的是其多语言覆盖能力,同时支持英语、阿拉伯语和法语,为跨语言语义理解研究提供了坚实基础。数据集还引入了现代俚语强度、地域性标识等新颖字段,并计算了语义相似度得分与质量分级,能够精准模拟真实语言环境中的语义模糊性与复杂性。
使用方法
为便于研究与应用,IdiomX v3提供了多个经过优化的数据配置版本。用户可通过HuggingFace的`datasets`库直接加载不同变体,例如扩展完整版`idiomx_extended_full`适用于大规模训练与跨语言建模,而高质量子集`idiomx_high_quality`则侧重于高置信度样本。数据集支持多种自然语言处理任务,包括习语检测、语境到习语的检索、语义相似度建模等。研究者可根据任务需求选择相应配置,并利用数据集中预计算的标准化例句、语义质量分数等衍生特征进行模型训练与评估。官方提供的交互式演示空间进一步展示了其在习语检测、混合检索等具体任务上的应用潜力。
背景与挑战
背景概述
在自然语言处理领域,习语理解因其语义的非组合性而构成显著挑战,传统数据集往往受限于语境单一与跨语言资源匮乏。IdiomX v3数据集由Ayman Ali Sharara于2026年创建,旨在构建一个大规模、多语言的习语表达理解基准。该数据集整合了英语、阿拉伯语及法语资源,涵盖逾12,000个独特习语及其17万余条语境化例句,通过语义验证与质量标注,为习语检测、跨语言检索等任务提供了系统化研究基础,推动了计算语言学在比喻性语言处理方面的发展。
当前挑战
习语理解的核心挑战在于其语义的晦涩性与语境依赖性,模型需区分字面与比喻用法,并处理多语言间的文化差异。IdiomX在构建过程中面临数据质量控制的难题,包括消除噪声例句、减少近义重复,以及通过嵌入相似度进行语义对齐。此外,扩展现代俚语与多语言支持时,需平衡生成数据的真实性与多样性,并确保法语等新增语言的注释准确性与一致性,这些挑战共同塑造了数据集的复杂性与实用性。
常用场景
经典使用场景
在自然语言处理领域,习语理解一直是语义解析的难点。IdiomX数据集通过提供大规模、多语言的语境化习语实例,为习语检测与分类任务奠定了基准。该数据集支持模型区分句子中习语的使用是字面意义还是比喻意义,其平衡的标签分布与高质量语义标注,使得研究者能够训练和评估模型在复杂语言现象上的性能。经典使用场景包括构建端到端的习语识别系统,以及开发能够理解上下文依赖的语义相似度模型。
实际应用
在实际应用中,IdiomX数据集能够赋能多语言机器翻译、内容审核与教育技术工具。例如,在翻译系统中,准确识别习语可避免直译错误,提升译文质量;在社交媒体内容分析中,检测俚语与当代习语有助于理解非正式表达与潜在冒犯性语言。此外,该数据集支持构建语言学习平台,通过提供习语的含义解释与语境示例,辅助第二语言学习者掌握地道的表达方式。
衍生相关工作
基于IdiomX数据集,已衍生出一系列经典研究工作,主要集中在多语言习语检测模型、跨语言检索系统以及语义相似度计算框架上。例如,研究者利用其平衡的习语与字面用法样本,训练了基于Transformer的检测器;其提供的阿拉伯语与英语对照数据,促进了双语嵌入模型的开发。此外,数据集支持的混合检索与重排序方法,为信息检索领域提供了新的评估基准,推动了上下文感知的习语理解技术进步。
以上内容由遇见数据集搜集并总结生成


