ContextSpeech
收藏Hugging Face2025-05-20 更新2025-05-21 收录
下载链接:
https://huggingface.co/datasets/Insects/ContextSpeech
下载链接
链接失效反馈官方服务:
资源简介:
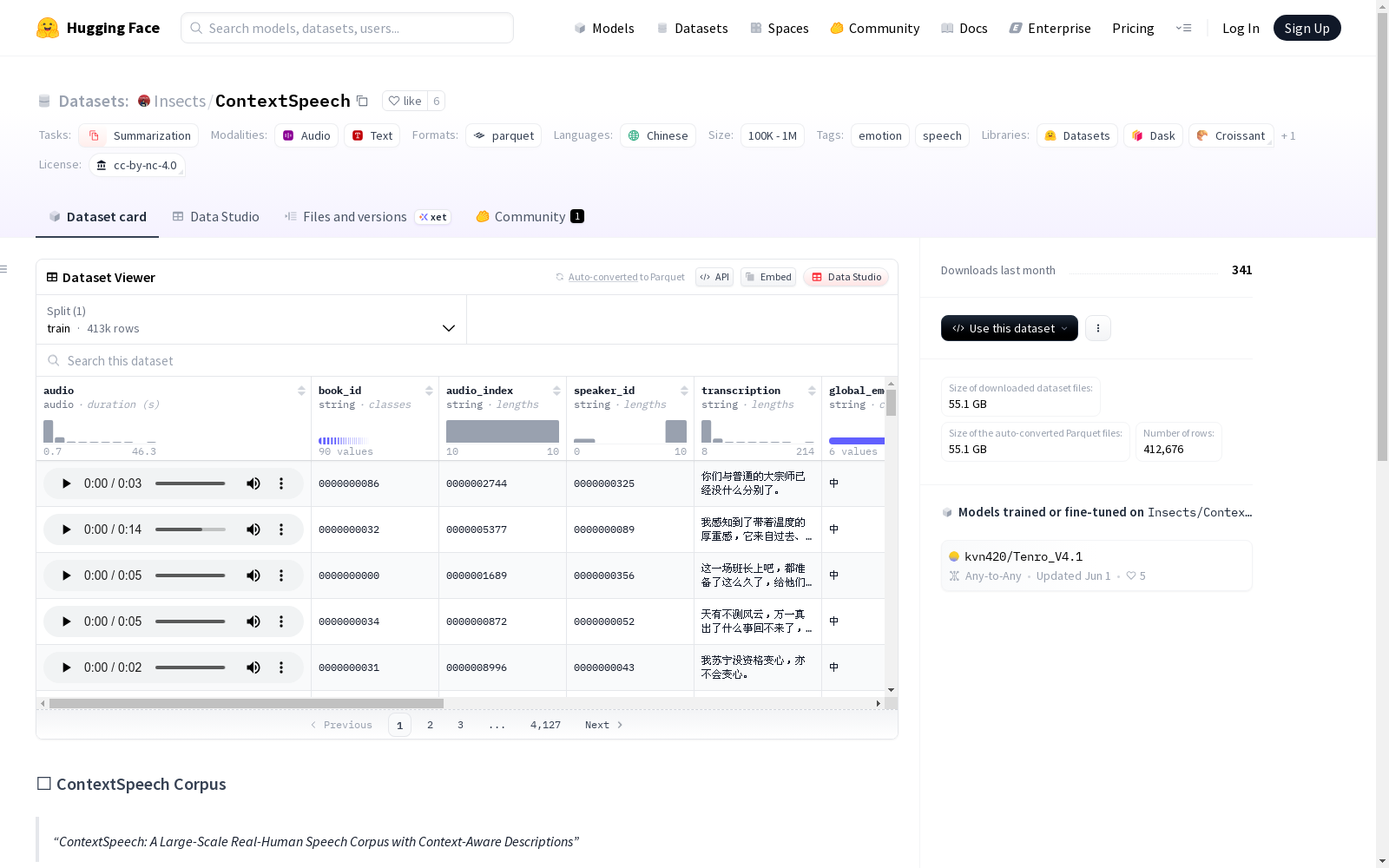
ContextSpeech是一个包含上下文感知描述的大规模真实人类言语语料库,包含476.8小时的言语数据,涵盖超过4000个说话者和1500多种情感类别。每个样本都有对应的说话者背景信息和对话场景细节。
创建时间:
2025-05-11
搜集汇总
数据集介绍
构建方式
在语音理解研究领域,ContextSpeech语料库的构建体现了从句子级到上下文感知的重要转变。该数据集通过收集真实人类语音样本,精心标注了476.8小时的语音数据,涵盖超过4000名不同背景的说话者。每个语音样本都配备了详细的说话者背景信息和对话场景描述,构建过程中特别注重捕捉语音产生的具体交际情境,确保数据能够反映不同场景下语音风格的多样性。
特点
ContextSpeech语料库的显著特征在于其规模庞大且标注精细,不仅包含1500余种情感类别,还提供了丰富的上下文信息。数据集突破了传统语音数据集仅关注离散属性的局限,通过记录说话者的个人背景和具体对话情境,使得研究者能够深入分析语音风格与交际环境的内在联系。这种多维度的标注体系为语音理解研究提供了前所未有的数据支持。
使用方法
该数据集适用于语音理解和生成的多项研究任务,研究者可通过加载parquet格式的数据文件获取语音样本及其对应的上下文描述。使用时应遵循CC-BY-NC-4.0许可协议,仅限研究用途。数据集的丰富标注信息可用于训练上下文感知的语音模型,探索说话者背景和对话场景对语音风格的影响,为开发更自然的人机交互系统提供数据基础。
背景与挑战
背景概述
语音理解与生成作为人机交互的核心技术,长期以来依赖句子层面的离散属性进行建模。2025年由Insects团队发布的ContextSpeech语料库,突破了传统单句分析的局限,将研究视角延伸至上下文感知领域。该数据集收录476.8小时真实语音,涵盖4000余名说话者与1500种情感类别,通过记录说话者背景与对话场景的元数据,为探索语境对语音风格的动态影响提供了实证基础。
当前挑战
在语音生成领域,如何将文本内容与动态语境要素进行有效融合仍是核心难题。ContextSpeech需解决多维度语境特征(如社会身份、场景意图)与声学特征的映射问题,同时面临大规模真实场景数据采集的复杂性。构建过程中需克服细粒度情感标注的一致性校验、跨场景语音质量的均衡控制,以及隐私信息脱敏等技术壁垒。
常用场景
经典使用场景
在语音理解与生成研究中,ContextSpeech数据集被广泛应用于探索上下文感知的语音建模。该数据集通过整合说话者背景和对话场景的丰富信息,使研究者能够超越传统句子级分析,深入模拟真实交流中的语音变化。例如,在情感语音合成任务中,模型可依据特定情境动态调整语调风格,从而更精准地还原人类对话的复杂性。
解决学术问题
该数据集有效解决了语音研究领域长期存在的语境信息缺失问题。传统方法依赖离散标签描述语音特征,难以捕捉对话场景、说话者身份等动态因素对语音风格的影响。通过提供大规模带语境标注的真实语音样本,该资源为建立跨场景鲁棒性语音模型提供了数据基础,推动了从孤立分析到情境化理解的学术范式转变。
衍生相关工作
该数据集已催生多项语境感知语音生成的前沿研究。例如基于注意力机制的语境编码器设计,能够动态融合说话者特征与场景信息;另有工作探索多模态语境建模,将文本描述与语音信号联合训练。这些衍生研究逐步构建起上下文语音技术体系,持续推动对话系统、情感计算等方向的方法创新。
以上内容由遇见数据集搜集并总结生成


