CleanPatrick
收藏arXiv2025-05-16 更新2025-05-20 收录
下载链接:
https://huggingface.co/datasets/Digital-Dermatology/CleanPatrick
下载链接
链接失效反馈官方服务:
资源简介:
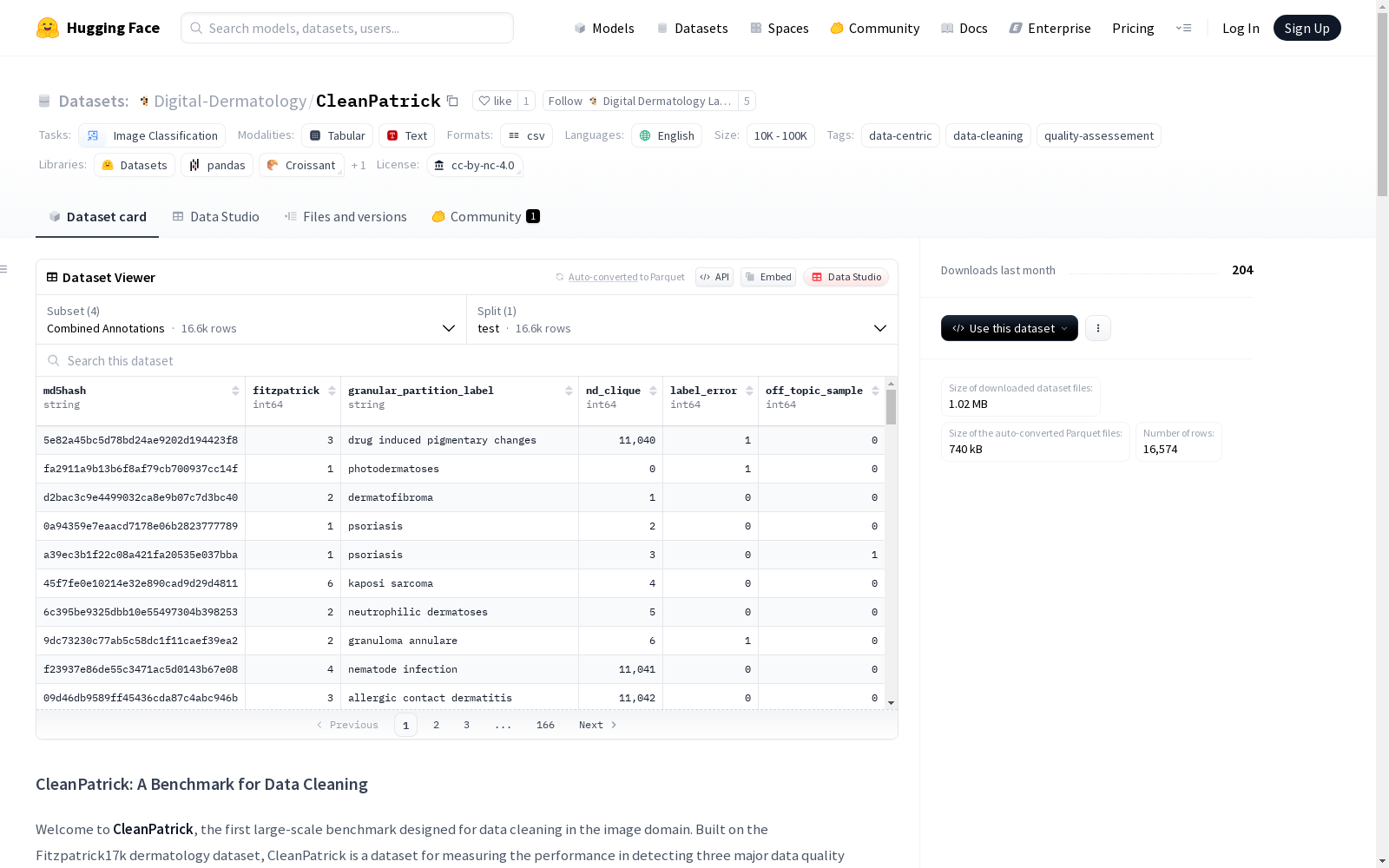
CleanPatrick是一个大型图像数据清洗基准,基于公开可用的Fitzpatrick17k皮肤病数据集构建。它收集了933名医疗众包工作者的496,377个二元标注,识别了离题样本、近似重复样本和标签错误,并采用了一种受项目反应理论启发的聚合模型,随后进行专家审查,以获得高质量的地面真实数据。CleanPatrick将问题检测正式化为排序任务,并采用典型的排序指标,以反映实际的审计工作流程。通过发布数据集和评估框架,CleanPatrick使图像清洗策略的系统比较成为可能,并为更可靠的数据为中心的人工智能铺平了道路。
提供机构:
巴塞尔大学, 卢塞恩应用科学与艺术大学, 巴塞尔大学医院, 西北大学, 东北皮肤病学会, 维也纳医科大学, 班纳医疗
创建时间:
2025-05-16
搜集汇总
数据集介绍
构建方式
CleanPatrick数据集的构建基于公开可用的Fitzpatrick17k皮肤病学数据集,通过医学众包工作者收集了496,377个二元标注,识别了离题样本(4%)、近重复样本(21%)和标签错误(22%)。标注过程采用基于项目反应理论的聚合模型,并经过专家评审以确保高质量的真实标注。数据集将问题检测形式化为排序任务,并采用典型的排序指标以反映实际审计工作流程。
特点
CleanPatrick数据集的特点在于其大规模、高质量的标注,涵盖了三种主要的数据质量问题:离题样本、近重复样本和标签错误。数据集基于真实的医学图像,具有细粒度和长尾分布的标签,反映了医学领域的特殊性。通过专家验证和众包标注的结合,数据集提供了可靠的基准,用于系统比较图像清理策略。
使用方法
CleanPatrick数据集的使用方法包括将数据质量问题检测形式化为排序任务,采用标准的排序指标(如AUROC、AP、P@k、R@k)进行评估。用户可以通过提供的评估框架,比较不同清理策略在离题样本、近重复样本和标签错误检测上的性能。数据集和评估框架的发布为数据中心化人工智能的可靠性研究提供了系统化的工具。
背景与挑战
背景概述
CleanPatrick数据集由Fabian Gröger等研究人员于2025年提出,是首个针对图像数据清洗领域的大规模基准测试。该数据集基于公开的皮肤病学数据集Fitzpatrick17k构建,通过933名医学众包工作者收集了496,377条二元标注,系统识别了离题样本(4%)、近重复图像(21%)和标签错误(22%)三类数据质量问题。研究团队创新性地采用项目反应理论构建标注聚合模型,并经过专家复核形成高质量基准。作为数据中心化人工智能的重要基础设施,CleanPatrick填补了图像领域缺乏真实世界数据清洗评估基准的空白,为医疗影像等专业领域的模型可靠性研究提供了标准化测试平台。
当前挑战
CleanPatrick数据集面临的核心挑战体现在:1) 领域问题层面,医疗影像的细粒度分类特性使得标签错误检测成为开放难题,现有方法在22%的错误率基准上仅达到随机猜测水平;2) 构建过程中,近重复检测需处理O(N²)量级的图像对标注,研究团队设计基于DINO嵌入的快速清洗算法将复杂度降至O(NlogK)。同时,医疗标注的专业性要求催生了创新的众包-专家协同验证机制,通过IRT模型量化标注者能力与样本难度,最终在专家复核中实现离题样本96%、近重复96%、标签错误67%的验证一致率。
常用场景
经典使用场景
CleanPatrick数据集作为首个专注于图像数据清洗的大规模基准,其经典使用场景主要围绕评估和比较不同数据清洗策略在医学图像领域的表现。该数据集基于Fitzpatrick17k皮肤病学数据集构建,通过大规模的医学众包标注(496,377条二元标注)识别了离题样本(4%)、近重复图像(21%)和标签错误(22%)。研究者可利用该数据集验证算法在真实噪声环境下的鲁棒性,尤其是在处理细粒度医学分类任务时,例如通过自监督表征检测近重复图像,或利用经典异常检测方法在有限审核预算下筛选离题样本。
解决学术问题
CleanPatrick系统性地解决了图像数据清洗领域缺乏标准化评估的学术难题。传统方法依赖合成噪声或狭窄的人工研究,难以反映真实场景的复杂性。该数据集通过医学专家验证的标注,为三类数据质量问题(离题样本、近重复、标签错误)提供了高质量基准真值,并采用受项目反应理论启发的聚合模型处理标注噪声。其意义在于首次实现了清洗策略在真实医学图像场景下的可量化比较,揭示了自监督表征在近重复检测中的优势,以及标签错误检测这一细粒度医学分类中的开放挑战。
衍生相关工作
该数据集推动了多项数据清洗创新研究,包括:1)基于自监督表征的SelfClean方法在近重复检测中实现AUROC 0.92的性能突破;2)经典异常检测器(如Isolation Forest)在离题样本识别中验证了成本效益优势;3)暴露了Confident Learning等标签纠错方法在医学细粒度分类中的局限性(AP仅0.21)。相关衍生工作还涉及医疗数据去标识化技术、众包标注质量控制系统,以及基于项目反应理论的标注聚合算法优化。
以上内容由遇见数据集搜集并总结生成


