ETCII
收藏Hugging Face2026-05-09 更新2026-05-11 收录
下载链接:
https://huggingface.co/datasets/swap-uniba/ETCII
下载链接
链接失效反馈官方服务:
资源简介:
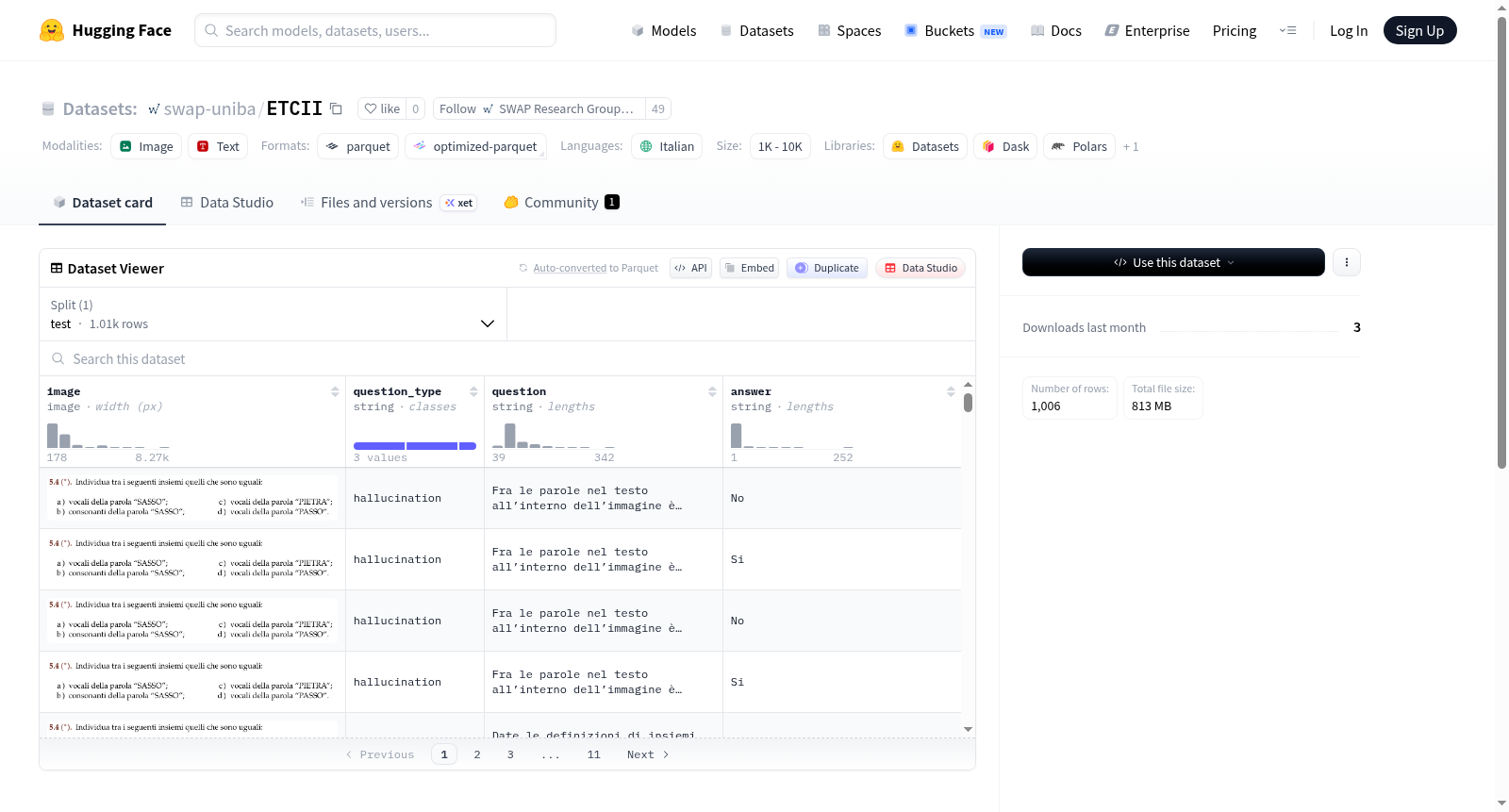
ETCII(Evaluation of Text-Centric Italian Images)是一个基准数据集,专门用于评估大型视觉语言模型在包含意大利文本的图像上的视觉问答(VQA)能力。数据集涵盖三个问题类别:幻觉(hallucination)——问题询问图像中是否包含特定单词;推理(reasoning)——问题的正确答案需要对图像内容进行常识推理,而不依赖外部知识;知识(knowledge)——问题的正确答案需要外部知识支持。数据集由107张独特图像和1006个问答对组成,包含图像(image)、问题类型(question_type)、问题(question)和答案(answer)等字段。总大小为875941491字节,共1006个样本。
ETCII (Evaluation of Text-Centric Italian Images) is a benchmark dataset designed to evaluate the visual question answering (VQA) capabilities of large vision-language models on images containing Italian text. The dataset includes three question categories: hallucination—questions asking whether specific words are present in the image; reasoning—questions where the correct answer requires commonsense reasoning about the image content without external knowledge; and knowledge—questions where the correct answer relies on external knowledge. It consists of 107 unique images and 1006 question-answer pairs, with fields such as image, question_type, question, and answer. The total size is 875941491 bytes, containing 1006 samples.
提供机构:
SWAP Research Group@UNIBA
创建时间:
2026-05-09
原始信息汇总
数据集概述:ETCII
基本信息
- 数据集名称:ETCII(Evaluation of Text-Centric Italian Images)
- 语言:意大利语(it)
- 数据集大小:875,941,491 字节(约835MB)
- 下载大小:813,095,997 字节(约775MB)
数据集构成
- 图片数量:107张独特的图片
- 问答对数量:1006个
- 数据划分:仅包含测试集(test),共1006个样本
数据特征
每条数据包含以下字段:
- image:图像数据(image类型)
- question_type:问题类型(string类型)
- question:问题内容(string类型)
- answer:答案内容(string类型)
问题类别
数据集包含三类问题:
- hallucination:询问图片中是否包含特定词语
- reasoning:需要基于图像内容进行常识推理,无需外部知识
- knowledge:需要借助外部知识才能正确回答
数据集用途
该基准数据集用于评估大型视觉语言模型在处理包含意大利文本的图像时的视觉问答(VQA)性能。
其他说明
- 数据集配置名称为:default
- 数据文件路径为:data/test-*
- 更多详细信息可参考相关论文(论文信息待补充)
搜集汇总
数据集介绍
构建方式
ETCII数据集专为评估大型视觉语言模型在包含意大利语文本的图像上的视觉问答能力而构建。其构建过程精心选取了107张独特图像,这些图像均包含意大利语文本元素,并针对每张图像设计了多种类型的问题。总共生成了1006个问答对,确保覆盖不同难度和知识层次的挑战。数据集划分为测试集,以标准化方式检验模型性能,其具体统计细节和构建步骤可参见相关论文。
特点
该数据集的核心特点在于其问题分类的精细设计,涵盖三大类别:幻觉检测、推理与知识。幻觉检测部分考察模型是否准确识别图像中是否存在特定单词;推理部分要求模型基于图像内容进行常识推理;知识部分则需模型调用外部知识来解答。这种分类结构使得ETCII能全面评估模型的感知、理解与知识应用能力,特别适合检验模型在处理多模态意大利语文本时的鲁棒性与准确性。
使用方法
使用ETCII数据集时,研究人员可直接加载其提供的测试分割数据,包含图像、问题类型、问题文本及标准答案字段。模型需根据图像和问题生成回答,并与真实答案对比以评估性能。数据集格式为标准的HuggingFace结构,便于集成到现有的视觉语言模型评估流程中。通过分析模型在不同问题类别上的表现,可深入洞察其优势与不足,为模型优化提供明确方向。
背景与挑战
背景概述
ETCII(Evaluation of Text-Centric Italian Images)是一个专为评估大型视觉-语言模型在包含意大利语文本的图像视觉问答(VQA)任务中表现而设计的基准数据集。该数据集由意大利研究机构于近期创建,旨在填补针对非英语场景尤其是意大利语文本图像理解领域评估工具的空白。核心研究问题聚焦于模型对图像中嵌入文本的感知、推理与外部知识整合能力。通过对107张独特图像及1006个问答对的精心设计,ETCII涵盖了幻觉检测、常识推理及知识依赖三类问题,为多模态模型在特定语言视觉场景下的性能评估提供了标准化测试平台,对推动跨语言视觉理解研究具有重要影响力。
当前挑战
ETCII所解决的领域问题核心挑战在于大型视觉-语言模型对图像中意大利语文本的准确理解与推理,尤其是当文本与视觉内容需要常识或外部知识结合时,模型容易产生语义偏差或幻觉。构建过程中面临的挑战包括:确保图像中意大利语文本的自然分布与真实场景一致,避免人工合成痕迹;设计高质量、无歧义的问答对,平衡幻觉、推理与知识三类问题的难度与覆盖范围;以及严格控制数据集的规模与多样性,使其在有限样本下仍能有效揭示模型的关键缺陷,从而为模型改进提供可靠依据。
常用场景
经典使用场景
ETCII数据集专为多模态大语言模型在意大利语文字中心图像上的视觉问答能力评估而设计。其经典使用场景聚焦于三个关键维度:幻觉检测、常识推理与外部知识调用。在幻觉检测任务中,模型需准确判断图像中是否包含特定意大利语单词;在推理任务中,模型须结合图像内容进行常识性逻辑推导;而在知识任务中,模型则需借助外部知识库来回答问题。这一设计使ETCII成为检验模型对多语言、跨模态场景理解能力的标杆性基准。
实际应用
在实际应用中,ETCII可服务于意大利语地区的自动化图像内容审核系统,例如检测广告海报、路标或商品包装中文字与视觉元素的一致性。对于旅游、电商和教育等领域,该数据集能够帮助优化支持意大利语的智能助理,使其准确理解包含本地文字的场景图像。此外,在文化遗产数字化场景中,通过评估模型对意大利历史文献或艺术作品中文字的识别与问答能力,ETCII促进了多语言多模态技术在实际业务场景中的可靠部署。
衍生相关工作
ETCII的提出催生了多项衍生性研究工作。一方面,研究者基于其任务分类体系,扩展构建了面向更多语言(如法语、德语)的文字中心图像评估基准,形成了跨语言的VQA评测系列。另一方面,该数据集推动了对模型幻觉现象的系统性研究,例如通过对比ETCII与英语基准上的表现差异,开发出针对非英语文本的专用去幻觉训练方法。此外,围绕ETCII的知识问答类别,涌现出融合多语言知识图谱的视觉推理框架,提升了模型在低资源语言上的问答准确性。
以上内容由遇见数据集搜集并总结生成


