MMDuetIT
收藏Hugging Face2024-11-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/wangyueqian/MMDuetIT
下载链接
链接失效反馈官方服务:
资源简介:
MMDuetIT数据集用于训练MMDuet模型,并包含用于评估MMDuet的基准。数据集包括密集字幕、时间视频定位和多答案视频问答三个部分。密集字幕部分包含来自Shot2Story和COIN的示例,时间视频定位部分包含来自HiREST、DiDeMo和QueryD的示例,多答案视频问答部分包含自建的Shot2Story-MAGQA-39k数据集。
创建时间:
2024-11-20
原始信息汇总
MMDuetIT
数据集描述
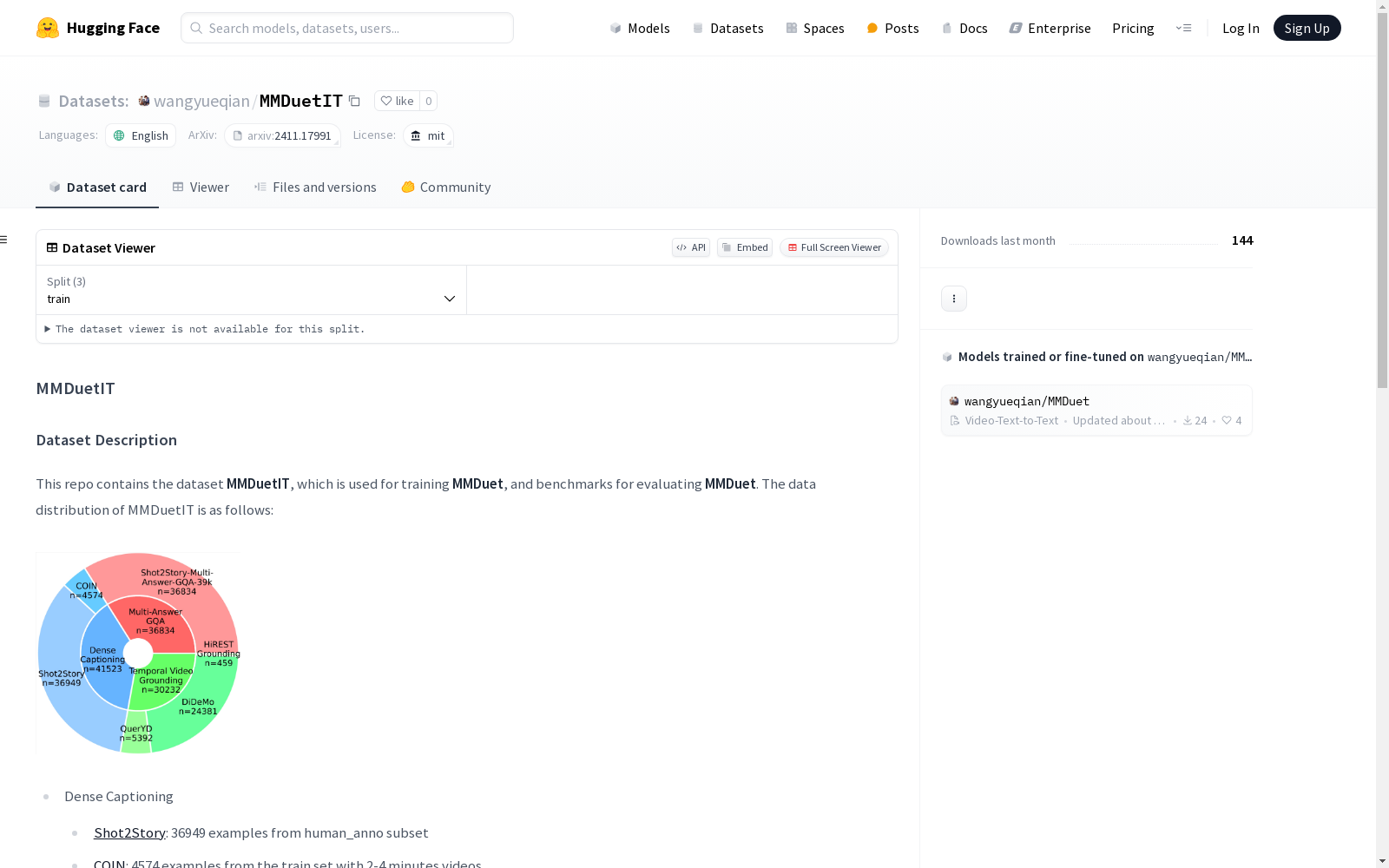
MMDuetIT 数据集用于训练 MMDuet 模型,并包含用于评估 MMDuet 的基准数据。数据集的分布如下:
- Dense Captioning
- Shot2Story: 36949 个样本来自 human_anno 子集
- COIN: 4574 个样本来自训练集,视频时长为 2-4 分钟
- Temporal Video Grounding
- HiREST: 459 个样本
- DiDeMo: 24381 个样本
- QueryD: 5392 个样本
- Multi-Answer Grounded Video Question Answering (MAGQA)
- Shot2Story-MAGQA-39k: 包含在数据集中,训练集为
shot2story/annotations/magqa_train-0.25_0.5-earlier.json,测试集为shot2story/annotations/magqa_test.json。问题和答案由 Shot2Story 的人工标注字幕通过 GPT-4o 转换而来。
- Shot2Story-MAGQA-39k: 包含在数据集中,训练集为
相关资源
- 论文: VideoLLM Knows When to Speak: Enhancing Time-Sensitive Video Comprehension with Video-Text Duet Interaction Format
- Github: MMDuet
- 视频演示: YouTube 和 Bilibili
- 模型: MMDuet
引用
如果此工作对你的研究有帮助,请考虑引用:
bibtex @misc{wang2024mmduet, title={VideoLLM Knows When to Speak: Enhancing Time-Sensitive Video Comprehension with Video-Text Duet Interaction Format}, author={Yueqian Wang and Xiaojun Meng and Yuxuan Wang and Jianxin Liang and Jiansheng Wei and Huishuai Zhang and Dongyan Zhao}, year={2024}, eprint={2411.17991}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2411.17991}, }
搜集汇总
数据集介绍
构建方式
MMDuetIT数据集的构建过程整合了多个公开数据集,涵盖了密集描述、时序视频定位以及多答案视频问答等多个任务。具体而言,密集描述部分采用了Shot2Story和COIN数据集,分别包含36949个和4574个样本;时序视频定位部分则整合了HiREST、DiDeMo和QueryD数据集,样本数量分别为459、24381和5392个。此外,针对多答案视频问答任务,该数据集引入了Shot2Story-MAGQA-39k,其训练集和测试集分别基于Shot2Story的标注数据,并通过GPT-4o生成问题和答案。
特点
MMDuetIT数据集的特点在于其多任务性和高质量标注。它不仅涵盖了视频理解领域的多个核心任务,还通过整合多个公开数据集确保了数据的多样性和广泛性。特别是Shot2Story-MAGQA-39k子集,通过GPT-4o生成的问答对,为多答案视频问答任务提供了高质量的标注数据。此外,数据集的分布清晰,涵盖了不同时长和类型的视频,为模型训练和评估提供了丰富的场景支持。
使用方法
MMDuetIT数据集的使用方法主要围绕其多任务特性展开。用户可以根据具体任务选择相应的子集进行训练和评估。例如,密集描述任务可使用Shot2Story和COIN子集,时序视频定位任务则可使用HiREST、DiDeMo和QueryD子集。对于多答案视频问答任务,Shot2Story-MAGQA-39k子集提供了专门的训练和测试数据。用户可通过访问GitHub仓库获取详细的使用指南和代码示例,并结合相关论文和模型进行深入研究。
背景与挑战
背景概述
MMDuetIT数据集于2024年由Yueqian Wang等研究人员发布,旨在支持多模态视频理解任务,特别是时间敏感的视频理解。该数据集整合了多个子数据集,包括Shot2Story、COIN、HiREST、DiDeMo和QueryD,涵盖了密集描述、时间视频定位以及多答案视频问答等任务。MMDuetIT的核心研究问题在于如何通过视频与文本的交互格式,提升模型对视频内容的时间敏感性理解。该数据集的发布为视频理解领域提供了新的基准,推动了多模态模型在复杂视频任务中的应用。
当前挑战
MMDuetIT数据集在解决视频理解任务时面临多重挑战。首先,视频数据的多样性和复杂性使得模型难以准确捕捉时间敏感信息,尤其是在多答案视频问答任务中,模型需要同时处理多个可能的正确答案。其次,数据集的构建过程中,研究人员需要整合来自不同来源的子数据集,确保数据的一致性和标注质量,这对数据清洗和标注标准化提出了较高要求。此外,如何利用GPT-4等先进技术生成高质量的问答对,同时保持数据的真实性和多样性,也是构建过程中的一大挑战。
常用场景
经典使用场景
MMDuetIT数据集在视频理解领域具有广泛的应用,特别是在密集字幕生成、时间视频定位和多答案视频问答等任务中。通过整合多个子数据集,如Shot2Story、COIN、HiREST、DiDeMo和QueryD,该数据集为研究者提供了一个全面的基准,用于评估和训练视频理解模型。其经典使用场景包括视频内容的多模态理解和时间敏感信息的提取,这些任务在视频分析和自动化字幕生成中尤为重要。
实际应用
在实际应用中,MMDuetIT数据集被广泛用于视频内容分析和自动化字幕生成。例如,在视频编辑和制作中,该数据集可以帮助自动生成视频的字幕,提高工作效率。在教育和培训领域,该数据集可以用于开发智能视频教学系统,自动提取视频中的关键信息并生成相应的教学内容。此外,该数据集还在视频监控和安防领域具有潜在应用,能够自动识别视频中的关键事件并生成相应的报告。
衍生相关工作
MMDuetIT数据集衍生了一系列相关研究工作,特别是在视频理解和多模态学习领域。基于该数据集,研究者开发了多种先进的视频理解模型,如MMDuet,这些模型在密集字幕生成、时间视频定位和多答案视频问答等任务中表现出色。此外,该数据集还推动了多模态数据融合和时间敏感信息处理的研究,为视频理解领域的发展提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


