HumanCaption-10M
收藏Hugging Face2024-09-13 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/OpenFace-CQUPT/HumanCaption-10M
下载链接
链接失效反馈官方服务:
资源简介:
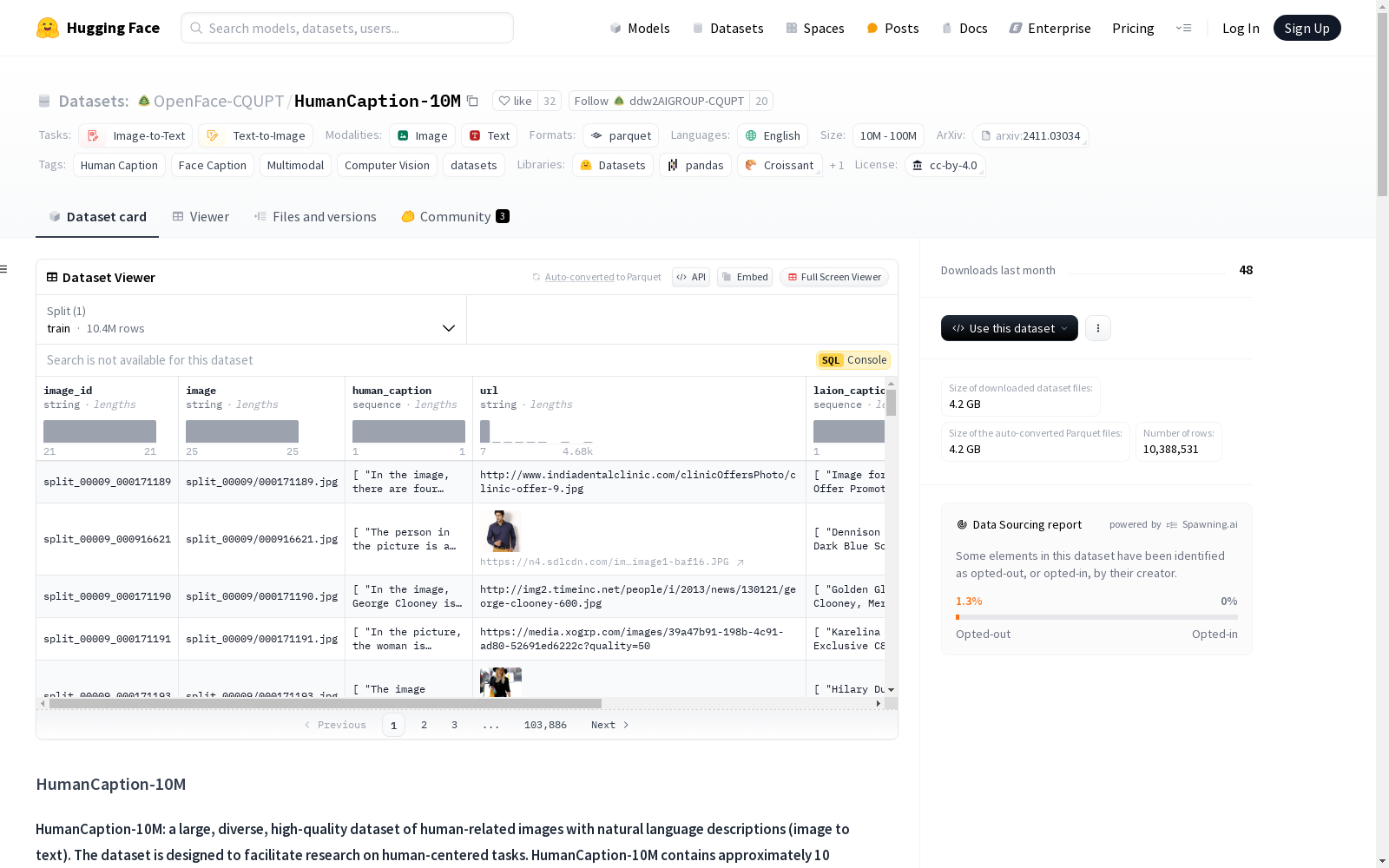
HumanCaption-10M是一个大规模、多样化、高质量的人类相关图像数据集,包含约1000万张人类相关图像及其对应的自然语言描述。该数据集旨在促进以人为中心任务的研究,是FaceCaption-15M的第二代版本。数据集主要用于图像到文本和文本到图像的任务,适用于计算机视觉和人类描述的研究。数据集由OpenFaceCQUPT发布,仅供研究和教育目的使用,并遵循CC-BY 4.0许可证。
HumanCaption-10M is a large-scale, diverse, and high-quality human-centric image dataset containing approximately 10 million human-related images paired with their corresponding natural language descriptions. As the second-generation iteration of FaceCaption-15M, this dataset is designed to advance research on human-centric tasks. It is primarily utilized for image-to-text and text-to-image tasks, and is suitable for research in computer vision and studies related to human description. Released by OpenFaceCQUPT, this dataset is intended solely for research and educational purposes and is licensed under CC-BY 4.0.
创建时间:
2024-09-12
原始信息汇总
HumanCaption-10M
概述
HumanCaption-10M 是一个大规模、多样化、高质量的人类相关图像数据集,包含自然语言描述(图像到文本)。该数据集旨在促进以人为中心任务的研究。HumanCaption-10M 包含约 1000 万张人类相关图像及其对应的自然语言描述,是 FaceCaption-15M 的第二代版本。
任务类别
- 图像到文本
- 文本到图像
标签
- 计算机视觉
- 人类描述
- 数据集
使用方法
python from datasets import load_dataset
ds = load_dataset("ponytail/HumanCaption-10M")
许可证信息
HumanCaption-10M 数据集由 OpenFaceCQUPT 发布,仅用于研究和教育目的。该数据集基于 Creative Commons Attribution 4.0 International License (CC-BY 4.0) 许可。
联系信息
- 邮箱: S230201133@stu.cqupt.edu.cn
- 邮箱: dw_dai@163.com
搜集汇总
数据集介绍
构建方式
HumanCaption-10M数据集的构建过程基于FaceCaption-15M的生成方法,通过多模态数据处理技术,整合了约1000万张与人类相关的图像及其自然语言描述。该数据集特别注重面部特征的描述,采用了先进的图像处理和自然语言生成模型,确保了数据的高质量和多样性。构建过程中,研究人员还特别关注了数据的隐私和伦理问题,确保所有数据均符合研究使用的标准。
特点
HumanCaption-10M数据集以其大规模、高质量和多样性著称,特别适合用于人像相关的研究任务。数据集中的每张图像都配有详细的自然语言描述,这些描述不仅涵盖了面部特征,还包括了场景和情感等丰富信息。此外,该数据集的多模态特性使其成为研究图像到文本转换、文本到图像生成等任务的理想选择。
使用方法
使用HumanCaption-10M数据集时,研究人员可以通过简单的代码调用快速加载文本部分数据,而图像数据则需要额外下载。该数据集特别适用于训练和评估涉及人类场景的视觉语言模型,如HumanVLM。通过这种方式,研究人员可以探索和开发更先进的视觉理解和生成技术,推动人像相关领域的研究进展。
背景与挑战
背景概述
HumanCaption-10M数据集由OpenFaceCQUPT团队于2024年9月发布,旨在推动以人为中心的计算机视觉任务研究。作为FaceCaption-15M的第二代版本,该数据集包含约1000万张与人类相关的图像及其自然语言描述,涵盖了面部特征等多模态信息。该数据集的构建基于公开模型如Qwen,并特别关注高质量、多样化的数据采集,以支持图像到文本及文本到图像的双向任务。HumanCaption-10M的发布为人类场景视觉语言模型(如HumanVLM)的训练提供了重要基础,推动了多模态人工智能领域的发展。
当前挑战
HumanCaption-10M数据集在构建和应用中面临多重挑战。首先,数据集的规模和质量要求极高,确保图像与文本描述的准确对应是一项复杂任务,尤其是在处理多样化的人类特征时。其次,数据集中可能存在偏见或不安全内容,这对模型的鲁棒性和公平性提出了更高要求。此外,多模态数据的融合与对齐技术仍需进一步优化,以实现更高效的图像与文本交互。最后,数据集的伦理使用问题不容忽视,如何在保护隐私的前提下推动研究进展,是当前亟待解决的关键问题。
常用场景
经典使用场景
HumanCaption-10M数据集在计算机视觉与自然语言处理的交叉领域中展现了其独特的价值。该数据集包含了约1000万张与人类相关的图像及其自然语言描述,广泛应用于图像到文本的生成任务。研究人员利用该数据集训练多模态模型,探索如何从图像中提取人类特征并生成准确的文本描述。这一过程不仅推动了图像理解技术的发展,还为人类行为分析、情感识别等任务提供了丰富的数据支持。
衍生相关工作
HumanCaption-10M数据集催生了一系列经典研究工作,其中最著名的是基于该数据集训练的HumanVLM模型。该模型是一个面向人类场景的多模态语言视觉模型,能够统一处理图像与文本的交互任务。此外,该数据集还推动了FaceCaption-15M等前代数据集的优化与扩展,为后续研究提供了重要的参考和基础。
数据集最近研究
最新研究方向
在计算机视觉与自然语言处理的交叉领域,HumanCaption-10M数据集为研究者提供了一个大规模、多样化且高质量的人类相关图像与自然语言描述配对资源。该数据集的核心研究方向聚焦于多模态学习,特别是图像到文本和文本到图像的生成任务。近年来,随着深度学习技术的快速发展,基于HumanCaption-10M的研究逐渐向更复杂的任务扩展,如人类场景视觉语言模型的构建与优化。通过训练领域特定的大规模视觉语言模型(如HumanVLM),研究者能够更好地理解人类场景中的视觉与语言关联,推动人机交互、智能辅助系统等应用的发展。此外,该数据集的发布也促进了相关领域的数据共享与标准化,为后续研究提供了坚实的基础。
以上内容由遇见数据集搜集并总结生成


