temporal-vqa
收藏资源简介:
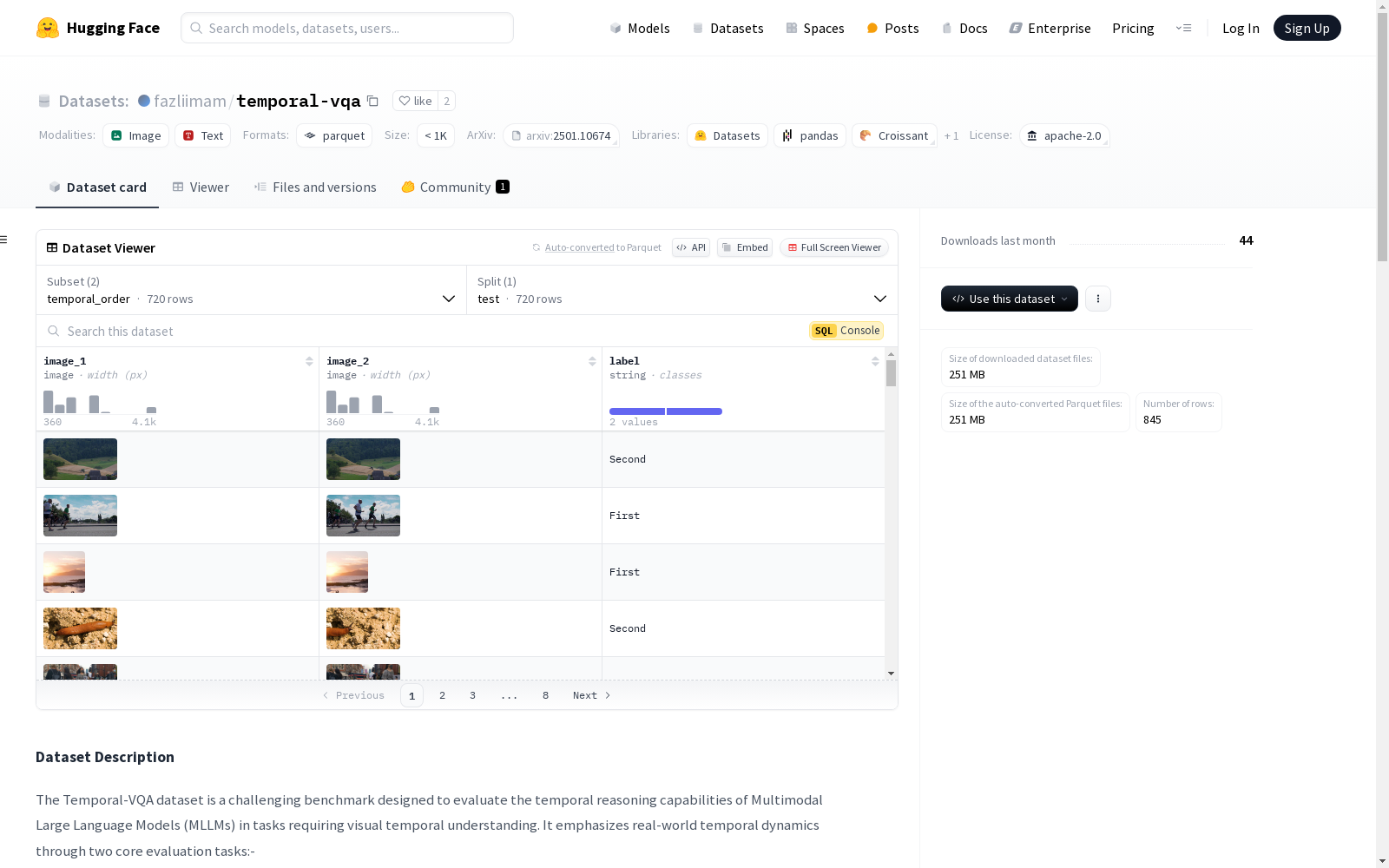
Temporal-VQA数据集是一个具有挑战性的基准,旨在评估多模态大语言模型(MLLMs)在需要视觉时间理解的任务中的时间推理能力。它通过两个核心评估任务强调现实世界的时间动态: - **时间顺序理解**:该任务向MLLMs展示来自视频序列的时间连续帧。模型必须分析并确定事件的正确顺序,评估其理解事件随时间进展的能力。 - **时间间隔估计**:在此任务中,MLLMs被展示在不同时间间隔拍摄的图像对。模型需要通过从几秒到几年的多项选择中估计图像之间的时间间隔。
The Temporal-VQA dataset is a challenging benchmark designed to evaluate the temporal reasoning capabilities of multimodal large language models (MLLMs) in tasks requiring visual temporal understanding. It highlights real-world temporal dynamics through two core evaluation tasks: - **Temporal Order Comprehension**: This task presents temporally continuous frames from video sequences to MLLMs. Models must analyze and determine the correct event order, assessing their ability to understand event progression over time. - **Temporal Interval Estimation**: In this task, MLLMs are provided with pairs of images captured at distinct time intervals. Models are required to estimate the temporal interval between the two images via multiple-choice options ranging from several seconds to several years.