CLARIN-Emo
收藏Hugging Face2024-11-23 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/clarin-knext/CLARIN-Emo
下载链接
链接失效反馈官方服务:
资源简介:
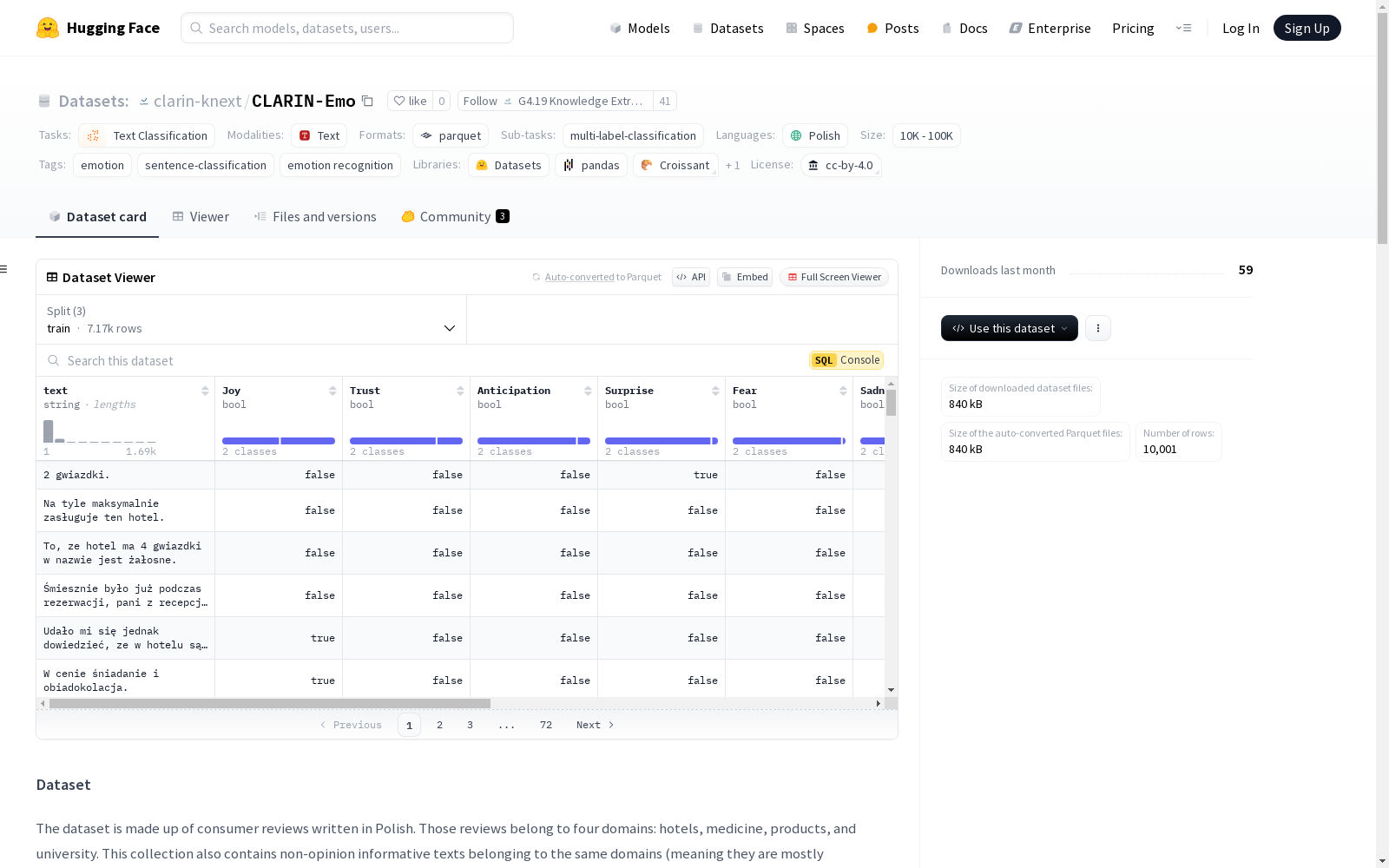
该数据集由波兰语的消费者评论组成,涵盖酒店、医药、产品和大学四个领域。数据集不仅包含评论,还包括属于同一领域的非观点性信息文本(主要是中性的)。每个句子和整个评论都被标注了普鲁特奇克的情感轮中的情感(如喜悦、信任、期待、惊讶、恐惧、悲伤、厌恶、愤怒)以及感知到的情感(正面、负面、中性),其中矛盾的情感使用正面和负面标签同时标注。数据集由六个人独立标注,最终标签由至少两人标注的结果决定,这意味着存在争议的文本和句子可能被标注为对立的情感。每个句子都有自己的标注,但这些标注是在整个评论的背景下创建的。数据集分为训练集、验证集和测试集,每个集合包含完整的评论,没有评论被分割在不同的集合中。
This dataset consists of Polish-language consumer reviews covering four distinct domains: hotels, medicine, products, and universities. It includes not only consumer reviews but also non-opinionated informational texts (mostly neutral) from these same domains. Each individual sentence and the full review are annotated with emotions from Plutchik’s Wheel of Emotions (including joy, trust, anticipation, surprise, fear, sadness, disgust, and anger) alongside their perceived sentiment (positive, negative, or neutral). For cases involving conflicting emotions, both positive and negative labels are applied. The dataset was annotated by six independent annotators, and the final label is determined by the consensus of at least two annotators, meaning that controversial texts and sentences may carry opposing emotion annotations. Each sentence has its own unique annotation, though these annotations are formulated within the context of the entire review. The dataset is partitioned into training, validation, and test sets, with each set containing complete reviews; no review is split across multiple sets.
提供机构:
G4.19 Knowledge Extraction Team
创建时间:
2024-11-23
搜集汇总
数据集介绍
构建方式
CLARIN-Emo数据集构建于波兰语的消费者评论,涵盖酒店、医疗、产品和大学四个领域。数据集不仅包含情感性评论,还纳入了同一领域的中立性文本。每条句子及整体评论均采用Plutchnik情感轮模型进行标注,涵盖喜悦、信任、期待、惊讶、恐惧、悲伤、厌恶和愤怒等情感,同时标注了积极、消极和中立的情感极性。六名独立标注者进行标注,最终标签由至少两人一致确认,确保了标注的可靠性。数据集按评论级别划分,训练集、验证集和测试集分别包含776、167和167条评论。
特点
CLARIN-Emo数据集以其多标签情感分类为显著特点,每条句子及整体评论均标注了多种情感和情感极性。数据集涵盖了广泛的情感维度,能够支持复杂的情感分析任务。其独特的标注方式允许同一文本同时标注对立情感,反映了真实场景中情感的复杂性。此外,数据集的波兰语背景为跨语言情感分析提供了宝贵资源。数据集格式清晰,每条评论以特殊符号标记结束,便于区分评论边界。
使用方法
CLARIN-Emo数据集适用于多标签情感分类任务,可用于训练和评估情感识别模型。使用时应按数据集提供的格式加载数据,分别处理训练集、验证集和测试集。每条句子及其对应的情感标签可作为模型的输入和输出。整体评论的标注可用于评估模型在更大文本单元上的表现。数据集支持多种机器学习框架,用户可根据需求选择适合的模型架构。在使用过程中,需注意数据集的语言背景,确保模型能够处理波兰语文本。
背景与挑战
背景概述
CLARIN-Emo数据集由波兰语消费者评论构成,涵盖酒店、医疗、产品和大学四个领域,并包含非观点性文本。该数据集基于Plutchnik情感轮理论,标注了八种基本情感(喜悦、信任、期待、惊讶、恐惧、悲伤、厌恶、愤怒)以及情感极性(积极、消极、中性)。数据集由六名独立标注者完成,最终标签通过多数投票确定,确保标注的可靠性。该数据集由波兰科学院计算机科学研究所等机构的研究人员创建,旨在推动情感识别和文本分类领域的研究,尤其在波兰语情感分析方面具有重要影响力。
当前挑战
CLARIN-Emo数据集在情感识别领域面临多重挑战。首先,情感的多标签分类问题增加了模型训练的复杂性,尤其是当同一文本被标注为相互矛盾的情感时。其次,波兰语作为低资源语言,情感表达的多样性和文化特异性使得模型泛化能力受限。在数据集构建过程中,标注者之间的主观差异以及情感标签的模糊性也带来了显著挑战。此外,如何在句子级别和整体评论级别之间建立一致的情感关联,仍是亟待解决的技术难题。
常用场景
经典使用场景
CLARIN-Emo数据集在情感识别和文本分类领域具有广泛的应用。该数据集通过标注波兰语消费者评论中的情感和情感极性,为研究者提供了一个多标签分类任务的基准。其经典使用场景包括训练和评估情感识别模型,特别是在多语言和多领域情感分析中,CLARIN-Emo数据集展现了其独特的价值。
解决学术问题
CLARIN-Emo数据集解决了情感分析领域中的多个关键学术问题。首先,它提供了基于Plutchnik情感轮的多标签情感标注,使得研究者能够更细致地分析文本中的复杂情感。其次,数据集中的情感极性标注(积极、消极、中性)为情感分类任务提供了明确的指导。此外,数据集的跨领域特性(酒店、医疗、产品、大学)使得研究者能够在不同领域中验证模型的泛化能力。
衍生相关工作
CLARIN-Emo数据集衍生了一系列经典研究工作。例如,Koptyra等人利用该数据集训练了基于人类标注和ChatGPT的情感识别模型,并在国际计算科学会议上发表了相关成果。此外,Kocoń等人在《Information Fusion》期刊上发表了关于ChatGPT在多任务学习中的应用研究,其中也使用了CLARIN-Emo数据集进行情感分析任务的验证。这些研究不仅推动了情感识别技术的发展,也为多语言情感分析提供了新的思路。
以上内容由遇见数据集搜集并总结生成


