persian_bbh
收藏Hugging Face2024-09-09 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/MatinaLLM/persian_bbh
下载链接
链接失效反馈官方服务:
资源简介:
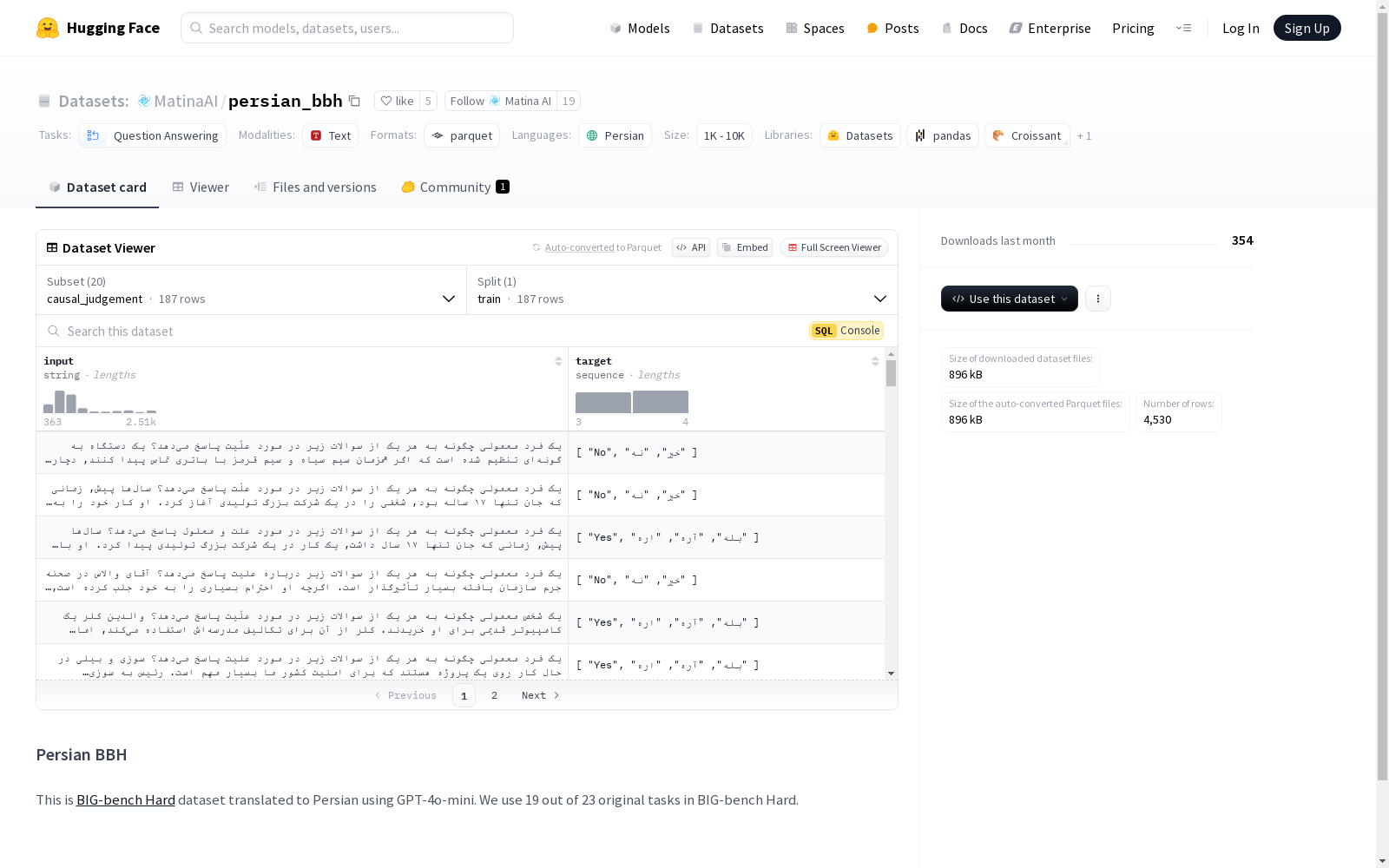
PersianBBH数据集是BIG-bench Hard数据集的波斯语翻译版本,包含了19个任务,涵盖了因果判断、逻辑推理、日期理解、歧义问答等多个领域。每个任务都有不同的配置名称、特征和训练集的详细信息,包括样本数量和数据大小。
创建时间:
2024-09-03
原始信息汇总
Persian BBH 数据集概述
基本信息
- 语言: 波斯语 (fa)
- 数据集大小: 1K<n<10K
- 任务类别: 问答 (question-answering)
- 数据集名称: PersianBBH
数据集配置
causal_judgement
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 330050num_examples: 187
- 下载大小: 538099
- 数据集大小: 661319
cot
- 特征:
category: stringcot: string
- 分割:
train:num_bytes: 79940num_examples: 19
- 下载大小: 23989
- 数据集大小: 79940
date_understanding
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 83260num_examples: 250
- 下载大小: 57774
- 数据集大小: 166520
disambiguation_qa
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 115334num_examples: 250
- 下载大小: 120524
- 数据集大小: 230668
dyck_languages
- 特征:
input: stringtarget: string
- 分割:
train:num_bytes: 52667num_examples: 250
- 下载大小: 25392
- 数据集大小: 105334
formal_fallacies
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 238028num_examples: 250
- 下载大小: 145232
- 数据集大小: 476524
logical_deduction_five_objects
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 247766num_examples: 250
- 下载大小: 120560
- 数据集大小: 495532
logical_deduction_seven_objects
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 314599num_examples: 250
- 下载大小: 156322
- 数据集大小: 629198
logical_deduction_three_objects
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 178420num_examples: 250
- 下载大小: 84750
- 数据集大小: 356840
multistep_arithmetic_two
- 特征:
input: stringtarget: int64
- 分割:
train:num_bytes: 13245num_examples: 250
- 下载大小: 15164
- 数据集大小: 26490
navigate
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 91645num_examples: 250
- 下载大小: 31379
- 数据集大小: 184895
object_counting
- 特征:
input: stringtarget: int64
- 分割:
train:num_bytes: 41989num_examples: 250
- 下载大小: 39501
- 数据集大小: 83978
penguins_in_a_table
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 107747num_examples: 146
- 下载大小: 85824
- 数据集大小: 215494
snarks
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 68428num_examples: 178
- 下载大小: 47418
- 数据集大小: 136856
sports_understanding
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 37523num_examples: 250
- 下载大小: 25310
- 数据集大小: 76661
temporal_sequences
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 278580num_examples: 250
- 下载大小: 146798
- 数据集大小: 557160
tracking_shuffled_objects_five_objects
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 289217num_examples: 250
- 下载大小: 149082
- 数据集大小: 578434
tracking_shuffled_objects_seven_objects
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 369909num_examples: 250
- 下载大小: 186210
- 数据集大小: 739818
tracking_shuffled_objects_three_objects
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 214888num_examples: 250
- 下载大小: 219404
- 数据集大小: 429776
web_of_lies
- 特征:
input: stringtarget: string (sequence)
- 分割:
train:num_bytes: 101679num_examples: 250
- 下载大小: 88010
- 数据集大小: 204980
搜集汇总
数据集介绍
构建方式
PersianBBH数据集是基于BIG-bench Hard数据集构建的,通过GPT-4o-mini模型将其翻译为波斯语。该数据集涵盖了BIG-bench Hard中的19个任务,涵盖了因果判断、逻辑推理、时间序列理解等多个领域。每个任务的数据均以文本形式存储,输入和输出分别以字符串或序列形式表示,确保了数据的多样性和复杂性。
特点
PersianBBH数据集的特点在于其多任务性和语言多样性。数据集包含19个不同的任务,每个任务都针对特定的认知能力进行设计,如逻辑推理、时间理解和数学运算等。数据以波斯语呈现,为波斯语自然语言处理研究提供了丰富的资源。此外,数据集的规模适中,每个任务的样本数量在19到250之间,适合用于模型训练和评估。
使用方法
PersianBBH数据集可用于波斯语自然语言处理任务的模型训练和评估。用户可以通过HuggingFace平台下载数据集,并根据任务需求选择特定的配置进行加载。每个任务的数据以JSON格式存储,便于直接用于模型输入。研究人员可以利用该数据集进行多任务学习、语言模型微调以及跨语言迁移学习等实验,以提升模型在波斯语任务上的表现。
背景与挑战
背景概述
PersianBBH数据集是基于BIG-bench Hard数据集的一个波斯语版本,旨在为波斯语自然语言处理任务提供高质量的基准测试。该数据集由研究人员通过GPT-4o-mini模型将BIG-bench Hard中的19个任务翻译为波斯语,涵盖了因果判断、逻辑推理、时间理解等多个复杂任务领域。BIG-bench Hard作为自然语言处理领域的重要基准,其波斯语版本的推出为波斯语社区的学术研究和模型开发提供了宝贵的资源。该数据集的创建不仅填补了波斯语复杂任务数据集的空白,也为跨语言模型评估提供了新的视角。
当前挑战
PersianBBH数据集在构建和应用过程中面临多重挑战。首先,波斯语作为一种形态丰富的语言,其语法结构和词汇复杂性对翻译和任务理解提出了较高要求,尤其是在逻辑推理和时间理解等任务中,语义的准确传递至关重要。其次,数据集的构建依赖于机器翻译模型,尽管GPT-4o-mini表现优异,但在跨语言任务中仍可能存在语义偏差或文化差异导致的翻译误差。此外,数据集的规模相对较小,部分任务的样本量有限,可能影响模型的泛化能力。如何在保持任务复杂性的同时扩展数据规模,并确保翻译质量,是未来研究的重要方向。
常用场景
经典使用场景
PersianBBH数据集在波斯语自然语言处理领域具有广泛的应用,尤其是在问答系统的开发与评估中。该数据集通过提供多种任务类型,如因果判断、逻辑推理、时间理解等,为研究人员提供了一个全面的测试平台。这些任务不仅涵盖了语言理解的基本层面,还涉及复杂的推理和逻辑分析,使得该数据集成为评估模型在波斯语环境下表现的重要工具。
解决学术问题
PersianBBH数据集解决了波斯语自然语言处理中的多个关键问题,尤其是在缺乏高质量波斯语数据集的情况下。通过提供多样化的任务,该数据集帮助研究人员更好地理解模型在处理复杂语言任务时的表现。特别是在逻辑推理、时间序列分析和多步算术等任务中,数据集为模型的鲁棒性和泛化能力提供了有效的评估标准,推动了波斯语NLP领域的研究进展。
衍生相关工作
PersianBBH数据集的发布催生了一系列相关研究工作,特别是在波斯语NLP模型的优化与评估方面。许多研究基于该数据集提出了新的模型架构和训练方法,以提升模型在复杂任务中的表现。此外,该数据集还激发了跨语言迁移学习的研究,推动了波斯语与其他语言之间的知识共享与模型迁移,进一步拓展了其应用范围。
以上内容由遇见数据集搜集并总结生成


