AI4Shipwrecks
收藏arXiv2024-01-26 更新2024-06-21 收录
下载链接:
https://umfieldrobotics.github.io/ai4shipwrecks/
下载链接
链接失效反馈官方服务:
资源简介:
AI4Shipwrecks数据集由密歇根大学创建,包含286张高分辨率标记的侧扫声纳图像,用于推动自主声纳图像理解的前沿技术。数据集通过在密歇根州的Thunder Bay国家海洋保护区使用自主水下航行器(AUV)进行调查收集。该数据集特别丰富,因为该区域拥有大量已知沉船目标,有助于机器学习在海洋探索中的应用。数据集旨在解决沉船检测算法的发展问题,特别是在声纳数据处理方面,以加速新沉船地点的发现。
The AI4Shipwrecks dataset was created by the University of Michigan, comprising 286 high-resolution annotated side-scan sonar images for advancing cutting-edge autonomous sonar image understanding technologies. The dataset was collected via surveys conducted using an Autonomous Underwater Vehicle (AUV) at the Thunder Bay National Marine Sanctuary in Michigan. This dataset is particularly valuable, as the sanctuary hosts a large number of known shipwreck targets, which supports the application of machine learning in marine exploration. The dataset aims to support the development of shipwreck detection algorithms, especially in sonar data processing, to accelerate the discovery of new shipwreck sites.
提供机构:
密歇根大学
创建时间:
2024-01-26
搜集汇总
数据集介绍
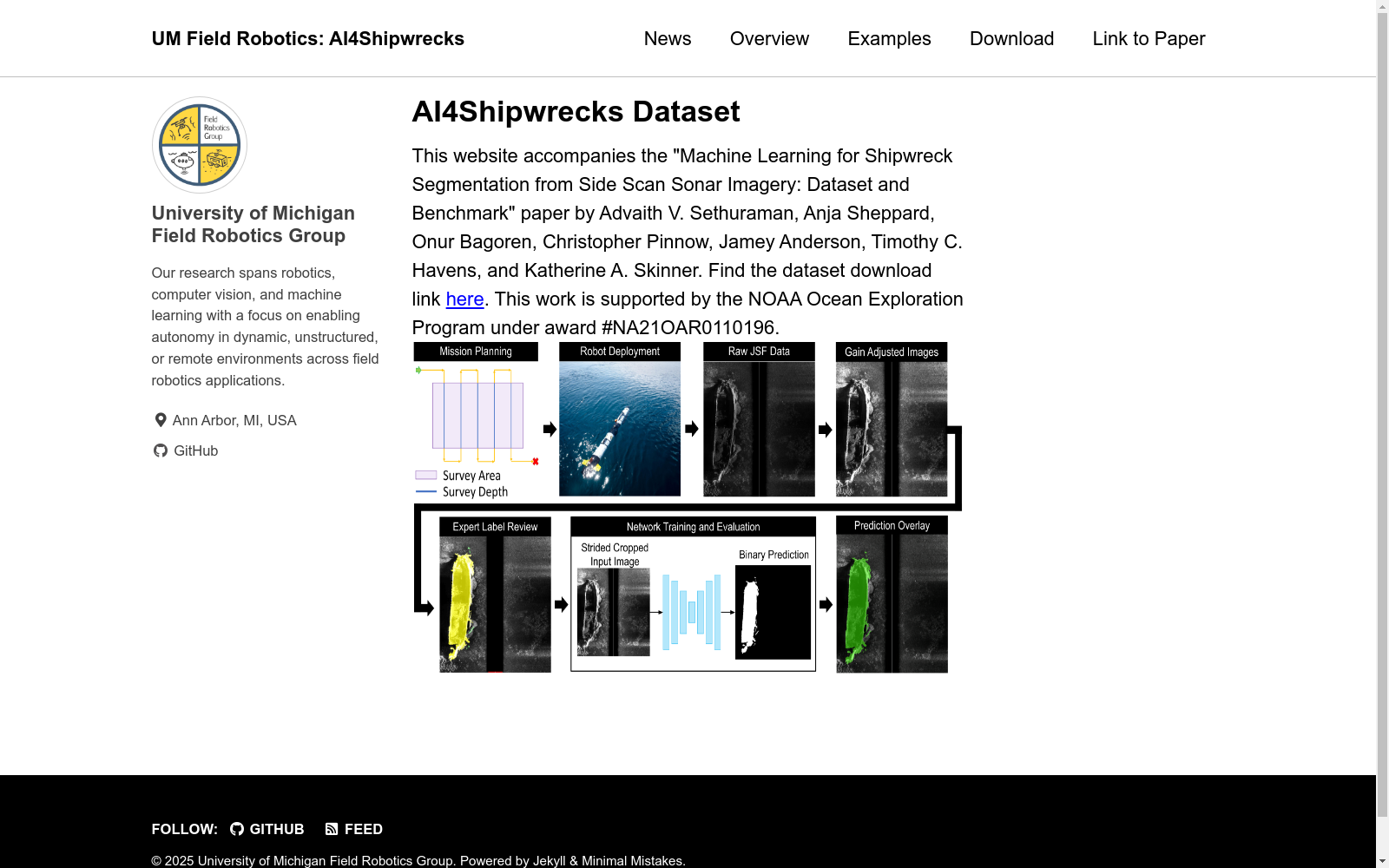
构建方式
AI4Shipwrecks数据集的构建方式基于对雷湾国家海洋保护区内的24个不同沉船地点进行的高分辨率侧扫声纳图像的收集。这些图像是在为期五周的自主水下航行器(AUV)调查中收集的,总共包括286张标记清晰的侧扫声纳图像。数据收集过程中,AUV被预先编程进行路线调查,并在航行过程中以恒定速度收集声纳数据。收集到的声纳数据经过后处理,转换为标准的图像格式,以便于深度神经网络的处理。随后,由机器学习算法生成像素级的分割预测,并以二进制分割掩码的形式输出,以便于可视化。
使用方法
使用AI4Shipwrecks数据集时,用户首先需要访问数据集的官方网站,以获取数据集和相应的软件工具。数据集被分为测试集和训练集,用户可以根据自己的研究需求选择使用其中的数据。为了便于神经网络的处理,数据集提供了全尺寸图像,并且可以通过步进裁剪的方式生成固定尺寸的图像。用户可以使用提供的基准实验结果来评估和比较不同深度学习模型的性能,从而为海洋探索领域中的机器学习研究提供参考。
背景与挑战
背景概述
在海洋机器人感知领域,开放源代码的基准数据集对于推动机器学习技术的发展至关重要。这些数据集为训练、验证和比较最先进的机器学习方法提供了大量的数据。然而,水下环境给收集用于海洋机器人感知的大规模基准数据集带来了许多操作上的挑战。此外,相对于搜索空间的大小,感兴趣的目标的稀缺性导致收集特定任务的有用数据集所需的时间和成本增加。因此,水下应用的可用的标记基准数据集有限。AI4Shipwrecks数据集旨在解决这一难题,它由24个独特的沉船遗址组成,总计286张高分辨率的标记侧扫声纳图像,以推动自主声纳图像理解领域的最新发展。该数据集利用了休伦湖中雷湾国家海洋保护区中独特丰富的目标,通过自主水下航行器(AUV)的调查收集和编制了声纳图像基准数据集。数据集的创建得到了专家海洋考古学家的协助,用于标记机器人收集的数据。该数据集用于进行基准实验,以比较最先进的监督分割方法,并展示了该领域的机遇和开放性挑战。数据集和基准测试工具将作为开源基准数据集发布,以促进五大湖和海洋探索的机器学习创新。
当前挑战
AI4Shipwrecks数据集面临的挑战主要包括:1)解决领域问题的挑战,即从侧扫声纳图像中分割沉船的挑战;2)构建过程中所遇到的挑战,包括水下环境的操作挑战、数据收集的时间和成本、以及相对较小的感兴趣目标的数量。此外,水下环境的独特性使得声纳图像的理解变得复杂,包括视差阴影效应、自遮挡、材料依赖的声学噪声和失真。为了克服这些挑战,研究人员采用了专家知识辅助的标记方法,并开发了高效的AUV调查平台,以获取高分辨率的声纳图像。
常用场景
经典使用场景
AI4Shipwrecks数据集主要用于推动机器学习在自主水下航行器(AUV)感知领域的应用。该数据集包含286张高分辨率侧扫声纳图像,覆盖了24个不同的沉船遗址,为研究人员提供了丰富的训练数据,以开发先进的机器学习模型进行沉船分割和识别。数据集的构建利用了休伦湖中桑德湾国家海洋保护区丰富的沉船资源,通过AUV进行实地调查收集数据,并由海洋考古专家进行标注,确保了数据的高质量和实用性。
解决学术问题
AI4Shipwrecks数据集解决了水下环境中缺乏大型基准数据集的问题,这对于推动水下机器人感知技术的发展至关重要。该数据集的发布填补了这一空白,为研究者提供了一个公开可用的、大规模的、带标签的侧扫声纳图像数据集,有助于评估和比较不同机器学习方法的性能。此外,该数据集还揭示了水下声纳图像理解的机遇和挑战,如声纳图像的视依赖阴影效应、自遮挡、材料依赖性声学噪声和失真等问题,为未来的研究提供了方向。
实际应用
AI4Shipwrecks数据集的实际应用场景包括但不限于海洋考古、海洋环境监测、水下资源勘探等领域。通过该数据集训练的机器学习模型可以自动处理声纳数据,快速识别和定位沉船遗址,从而加速新遗址的发现。此外,这些模型还可以用于水下环境的自动测绘和资源评估,为海洋科学研究和海洋工程提供支持。
数据集最近研究
最新研究方向
AI4Shipwrecks数据集的发布标志着海洋机器人感知领域的一项重要进展,特别是针对侧扫声纳图像的沉船分割任务。该数据集的创建旨在解决水下环境中数据收集的挑战,并填补了水下应用中标注数据集的匮乏。通过利用密歇根湖休伦湖雷湾国家海洋保护区的丰富沉船资源,研究人员得以收集并编译一个包含286张高分辨率标注侧扫声纳图像的基准数据集。这些数据集被用于对最先进的监督分割方法进行基准实验,并揭示了该领域的机遇和开放性挑战。AI4Shipwrecks数据集的公开将推动大湖和海洋探索中机器学习的创新。未来研究的一个有希望的领域是利用合成数据来增强真实声纳数据集,以便进行基于学习的检测和分割任务。此外,研究还应该集中在推进网络架构上,以使深度神经网络能够从有限的训练数据中学习。值得注意的是,最近的研究已经证明了小样本学习在海洋光学和声纳图像对象检测中的潜力。小样本学习和单样本学习旨在在看到该类对象的几个或单个实例后有效地学习表示该类对象,这对于每类样本相对较少的数据集来说是非常理想的。
相关研究论文
- 1Machine Learning for Shipwreck Segmentation from Side Scan Sonar Imagery: Dataset and Benchmark密歇根大学 · 2024年
以上内容由遇见数据集搜集并总结生成


