gdelt-gkg-2025-v2
收藏Hugging Face2025-02-12 更新2025-02-13 收录
下载链接:
https://huggingface.co/datasets/dwb2023/gdelt-gkg-2025-v2
下载链接
链接失效反馈官方服务:
资源简介:
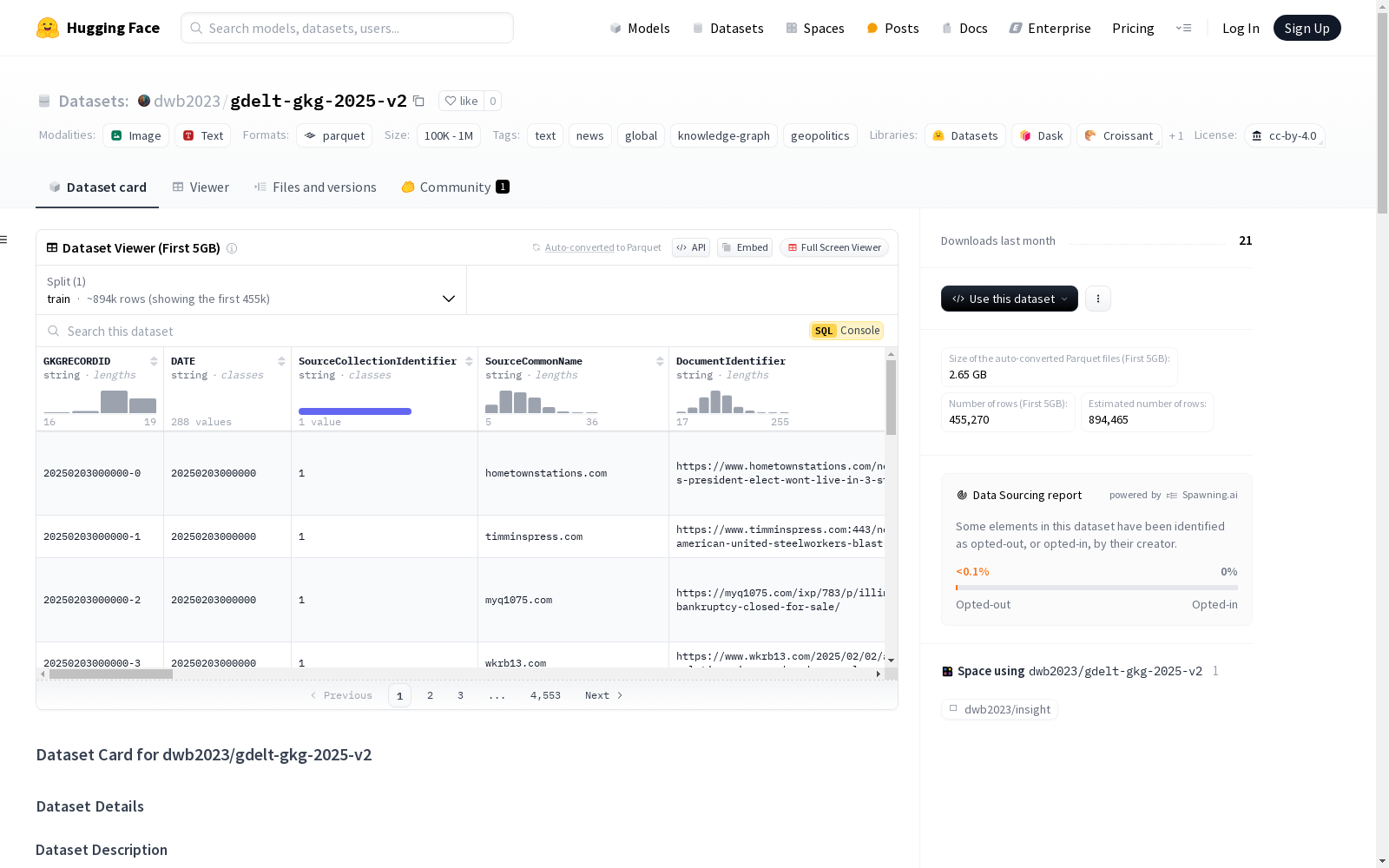
GDELT全球知识图谱2025数据集,涵盖2025年2月的内容,记录了全球事件互动、行为者关系和情境叙述,支持时间、空间和主题分析。数据集包含了日期、来源标识、文档标识、计数、主题、位置、人名、组织名、情感、时间参照、文档图像URL、引文和实体名称等特征。
The GDELT Global Knowledge Graph 2025 Dataset covers content from February 2025, documenting global event interactions, actor relationships and contextual narratives, supporting temporal, spatial and thematic analysis. The dataset includes features such as date, source identifier, document identifier, counts, topics, locations, personal names, organization names, sentiment, temporal references, document image URLs, citations and entity names.
创建时间:
2025-02-12
搜集汇总
数据集介绍
构建方式
本数据集GDelt-gkg-2025-v2,针对2025年2月全球事件互动、行为者关系及情境叙述进行专门构建。它从原始GDelt数据集中精选了部分字段,通过ETL管道进行数据转换,旨在为时态、空间和主题分析提供支持,从而形成了这一时期全球知识图谱的精细视角。
特点
该数据集特色在于其覆盖了全球范围内的知识图谱信息,不仅包含了核心的文档元数据,还涉及数值度量、分类、命名实体识别、情感分析、时间信息以及内容提取等维度。特别值得一提的是,它对原始数据集进行了增强,如提升了地理位置、人名、组织名的识别精确度,并对主题分类和情感分析进行了深化。
使用方法
用户可以直接利用此数据集进行全球事件的时态分析。然而,由于其历史和静态的特性,并不适合用于实时监测。同样,它也不应用于医疗诊断或预测性健康建模。使用时,用户需遵循CC-BY-4.0许可协议,并正确引用数据集来源。
背景与挑战
背景概述
GDELT Global Knowledge Graph (GKG)数据集是一个全球事件交互、行为者关系和情境叙述的集合,旨在支持时间、空间和主题分析。该数据集名为gdelt-gkg-2025-v2,由dwb2023团队于2025年 curated,专注于2025年2月的数据。其核心研究问题在于如何通过知识图谱的方式,详细记录和解析全球政治、经济和社会事件及其相互关系。该数据集的创建,为研究国际关系、地缘政治学以及全球事件动态提供了宝贵的资源,对相关领域产生了深远的影响。
当前挑战
该数据集面临的挑战主要在于:1) 如何准确捕捉和表示全球事件的复杂性,尤其是在地缘政治领域,事件的多元性和动态性使得数据集构建极具挑战性;2) 数据集构建过程中的技术挑战,包括选择合适的数据特征、确保数据质量以及开发有效的ETL(提取、转换、加载)管道。此外,由于数据集的静态特性,它不适用于实时监测,且在医疗诊断或预测健康模型方面的应用也超出了其设计范围。
常用场景
经典使用场景
在全球化事件交互、行为者关系和情境叙述的研究领域中,gdelt-gkg-2025-v2数据集因其包含全球知识图谱数据而成为一项宝贵的资源。该数据集的经典使用场景主要在于对全球事件进行时间序列分析,研究者能够通过该数据集深入挖掘特定时间段内的全球事件动态,为理解国际关系演变提供数据支撑。
衍生相关工作
基于gdelt-gkg-2025-v2数据集,已经衍生出多项相关工作,包括构建更复杂的知识图谱、进行跨语言的信息抽取、以及开发能够实时监测全球事件的系统等。这些相关工作进一步扩展了该数据集的应用范围,为全球事件研究提供了新的视角和方法。
数据集最近研究
最新研究方向
gdelt-gkg-2025-v2数据集汇聚了全球事件互动、行为者关系及情境叙述,旨在支持时态、空间与主题分析。近期研究集中于深入挖掘该数据集中的增强特征,如扩展的主题分类和分类法、增强的地点与人物名称提取,以及情感分析与数量测量提取,以期在全球地缘政治事件、社会政治与经济影响等领域取得新的洞察。该数据集为研究新兴大型语言模型能力的影响提供了宝贵资源,特别是在情境化实体识别、情感计算和主题建模方面的研究显示出其重要的学术与应用价值。
以上内容由遇见数据集搜集并总结生成


