Community Alignment
收藏arXiv2025-07-13 更新2025-07-16 收录
下载链接:
https://huggingface.co/datasets/facebook/community-alignment-dataset
下载链接
链接失效反馈官方服务:
资源简介:
社区对齐数据集(Community Alignment)是迄今为止最大且最具代表性的多语言和多轮偏好数据集,由来自五个国家的标注人员提供了近20万次比较。该数据集基于负相关抽样方法收集,旨在解决算法单一文化现象,即现有的大型语言模型(LLMs)在响应上表现出高度的同质性,无法有效学习人类偏好的多样性。数据集包括超过2500个提示-响应集,每个集至少由10个标注者标注,并且28%的标注还包含了高质量的中文解释。该数据集为改善LLMs对全球多样化人群的有效性提供了一个宝贵的资源。
Community Alignment Dataset (Community Alignment) is the largest and most representative multilingual, multi-turn preference dataset to date, curated with nearly 200,000 pairwise comparisons contributed by annotators from five countries. Collected via negative correlation sampling, this dataset aims to address the algorithmic monoculture phenomenon—where existing large language models (LLMs) exhibit high homogeneity in their responses and fail to effectively learn the diversity of human preferences. It includes over 2,500 prompt-response sets, each annotated by at least 10 annotators, and 28% of the annotations also contain high-quality Chinese explanations. This dataset provides a valuable resource for improving the effectiveness of LLMs for globally diverse populations.
提供机构:
FAIR at Meta
创建时间:
2025-07-13
原始信息汇总
Community Alignment Dataset 概述
数据集基本信息
- 名称: Community Alignment Dataset
- 许可证: Creative Commons Attribution 4.0 International License (CC-BY-4.0)
- 语言: 印地语 (hi)、英语 (en)、葡萄牙语 (pt)、意大利语 (it)、法语 (fr)
- 标签: alignment, preference, reward, llm
- 数据规模: 10K < n < 100K
数据集特点
- 大规模: 包含约200,000个LLM响应的比较,来自超过3,000名独特的标注者。
- 多语言: 包含英语、法语、意大利语、印地语和葡萄牙语的比较,其中63%的比较是非英语的。
- 提示级重叠: 2,599个提示至少包含10个标注,标注者在提示之间重叠。
- 高质量自然语言解释: 27%的提示中,标注者提供了详细的解释,说明为什么他们更喜欢某个响应。
数据集用途
- 用于对齐LLM与跨文化的人类偏好。
- 支持基于社会选择和分布方法的LLM对齐。
- 用户需在使用时实施适当的过滤和审核措施,以确保生成的输出符合其内容标准。
引用信息
-
BibTex: BibTex @article{zhang2025cultivating, title = {Cultivating Pluralism In Algorithmic Monoculture: The Community Alignment Dataset}, author = {Lily Hong Zhang and Smitha Milli and Karen Jusko and Jonathan Smith and Brandon Amos and Wassim and Bouaziz and Manon Revel and Jack Kussman and Lisa Titus and Bhaktipriya Radharapu and Jane Yu and Vidya Sarma and Kris Rose and Maximilian Nickel}, year = {2025}, journal = {arXiv preprint arXiv: 2507.09650} }
-
文本引用: Zhang, L. H., Milli, S., Jusko, K., Smith, J., Amos, B., Bouaziz, W., Revel, M., Kussmann, J., Titus, L., Radharapu, B., Yu, J., Sarma, V., Rose, K., Nickel, M. (2025). Cultivating Pluralism In Algorithmic Monoculture: The Community Alignent Dataset.
反馈与联系
- 如有任何反馈或问题,请联系: communityalignment@meta.com
搜集汇总
数据集介绍
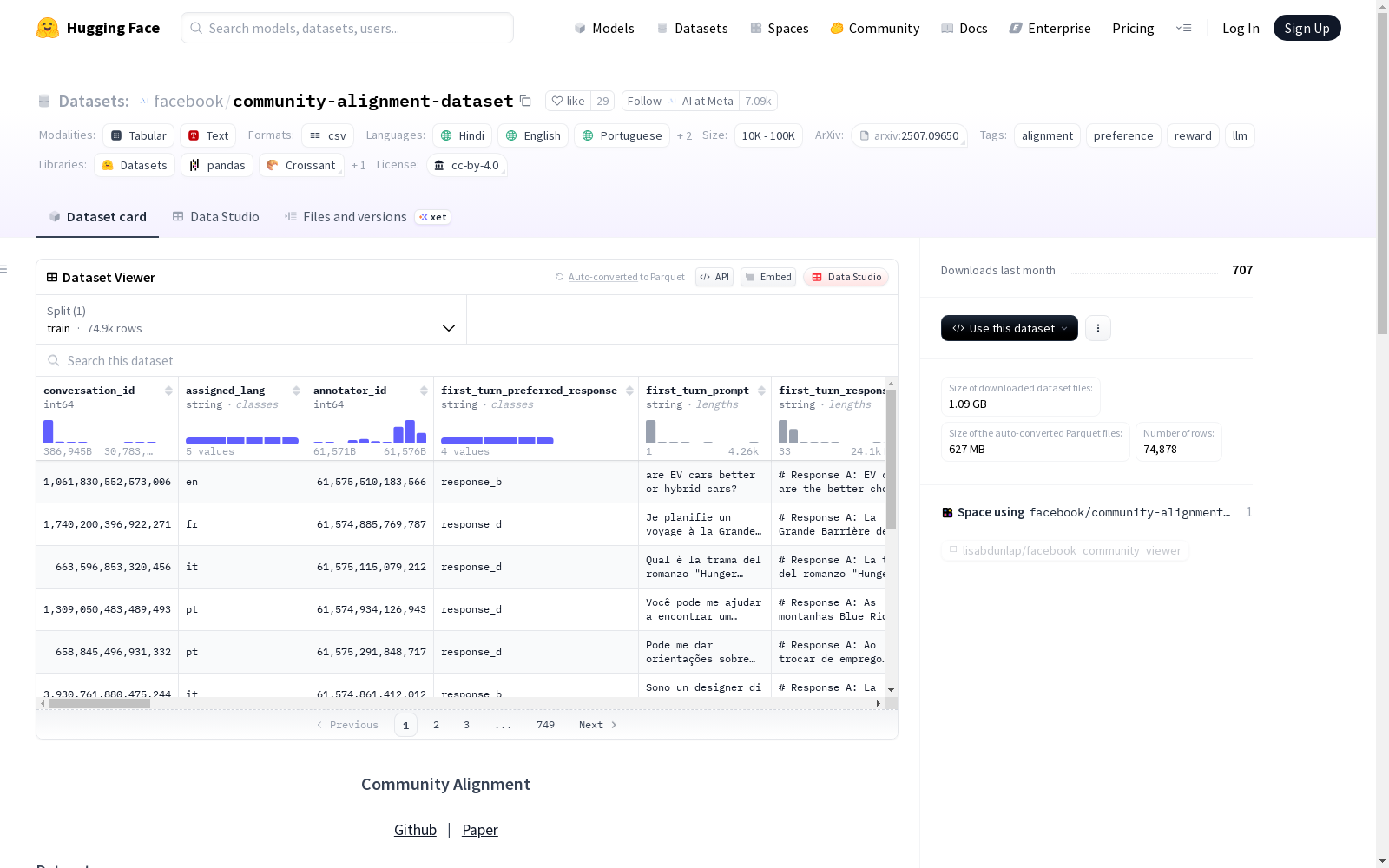
构建方式
Community Alignment数据集的构建过程基于负相关采样(NC sampling)技术,旨在解决大型语言模型(LLMs)在偏好学习中的算法单一性问题。研究团队首先通过一项涵盖五个国家(N=15,000)的大规模多语言人类研究,揭示了人类偏好的显著多样性远超21种前沿LLMs的响应范围。随后,他们提出通过提示工程技术显式生成负相关样本,确保候选响应集能覆盖对立价值观维度(如世俗理性与传统价值观)。最终,基于此方法收集了约20万条跨五国(美国、法国、意大利、巴西、印度)的多轮多语言偏好对比数据,并平衡了年龄、性别和种族等人口统计学特征。
特点
该数据集的核心特点体现在四个方面:其一,采用负相关采样技术突破模型响应同质化,使候选集能覆盖对立价值观;其二,涵盖英语、法语、意大利语、葡萄牙语和印地语五种语言,63%的对比数据为非英语,显著扩展了跨文化对齐研究的语言边界;其三,28%的标注包含高质量自然语言解释(平均53词),为理解选择动机提供细粒度依据;其四,首次在偏好数据集中实现提示级标注者重叠设计,超过2500个提示集由至少10名标注者独立评估,支持社会选择理论和分布式对齐方法的验证。
使用方法
使用该数据集时,研究者可通过三种路径实现价值观对齐:首先,直接应用标准对齐方法(如SFT、DPO)于负相关采样生成的候选集,实验证明其学习异质偏好的效能显著优于温度采样;其次,利用多标注者重叠特性,开发基于社会选择理论的聚合算法或分布对齐策略;第三,结合自然语言解释开发可解释的对齐框架。需注意,使用前应通过GPT-4o构建的评判模型对响应进行价值观维度标注(传统/世俗理性维度准确率85.8%,生存/自我表达维度78.3%),并建议参照论文提供的代码本进行跨文化分析。
背景与挑战
背景概述
Community Alignment数据集由Meta的研究团队于2025年7月创建,旨在解决大型语言模型(LLMs)在全球多样化用户偏好下的对齐问题。该数据集通过多国(美国、法国、意大利、巴西和印度)的大规模人类偏好研究(N=15,000),揭示了人类偏好的显著异质性与当前LLMs输出的同质化(仅覆盖41%的人类偏好)之间的差距。核心研究问题聚焦于如何通过负相关采样(NC sampling)技术增强模型对多元文化价值观的捕捉能力,从而推动语言模型在全球化应用中的包容性发展。
当前挑战
该数据集面临两大挑战:1) 领域挑战:现有对齐方法因候选响应同质化(算法单一文化现象),难以学习人类价值观的异质性,例如无法有效捕捉英格哈特-韦尔策尔全球价值观调查中的传统/世俗理性与生存/自我表达维度差异;2) 构建挑战:需克服多语言数据收集的复杂性(5种语言)、候选响应多样性不足的问题(通过负相关采样生成对抗性候选集),以及确保跨国注释者群体在年龄、性别和种族上的平衡代表性。
常用场景
经典使用场景
Community Alignment数据集被广泛应用于评估和优化大型语言模型(LLM)在多元文化背景下的表现。通过收集来自五个国家(美国、法国、意大利、巴西和印度)的多样化人类偏好数据,该数据集为研究LLM如何适应不同文化、政治和价值观冲突提供了重要支持。
衍生相关工作
基于Community Alignment数据集,研究者们开发了多种多元对齐方法,如个性化微调、社会选择理论应用和分布式对齐策略。这些工作进一步推动了AI系统在全球化背景下的适应性和包容性研究。
数据集最近研究
最新研究方向
随着大型语言模型(LLM)在全球范围内的快速普及,如何适应不同文化、政治和其他维度下用户的多样化偏好成为了一个关键挑战。Community Alignment数据集的提出,正是为了解决这一挑战。该数据集通过大规模多语言人类研究,揭示了人类偏好与现有LLM响应之间的显著差异,并提出了负相关采样(NC sampling)这一创新方法,以增强对齐方法在学习异质偏好方面的性能。Community Alignment不仅是迄今为止最大、最具代表性的多语言多轮偏好数据集,还通过其设计特点推动了多元化对齐研究的前沿,包括支持更广泛的偏好测量、扩展到 underrepresented 语言、支持表达性自然语言对齐方法,以及推进基于社会选择和分布式的对齐方法。这一数据集的发布为改善LLM在全球多样化用户中的有效性提供了宝贵资源。
相关研究论文
- 1Cultivating Pluralism In Algorithmic Monoculture: The Community Alignment DatasetFAIR at Meta · 2025年
以上内容由遇见数据集搜集并总结生成


