gigaspeech
收藏Hugging Face2024-10-13 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/lmms-lab/gigaspeech
下载链接
链接失效反馈官方服务:
资源简介:
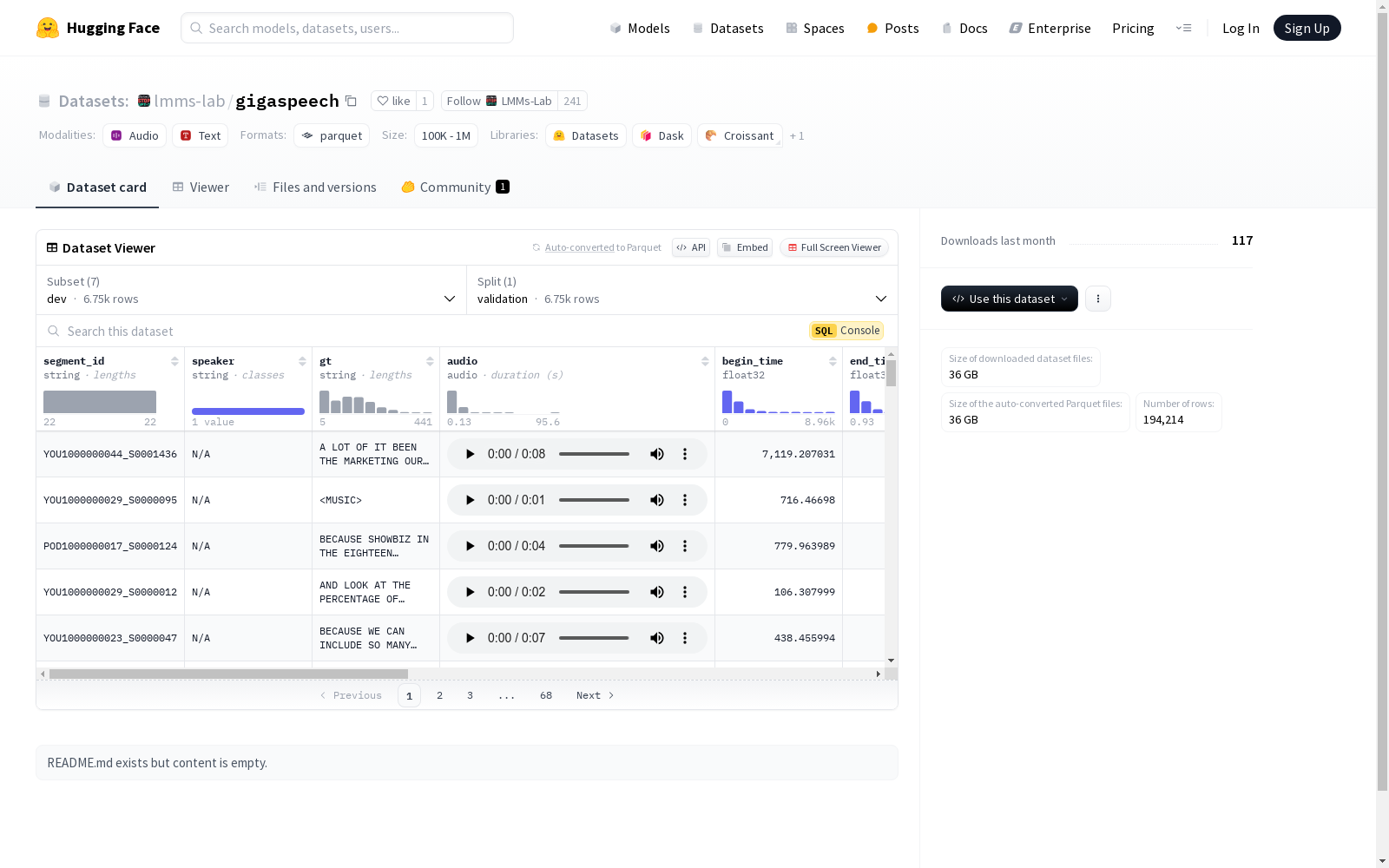
该数据集包含多个配置,每个配置都有不同的特征和分割。主要特征包括音频片段的ID、说话者、真实标签、音频数据(采样率为16000)、开始和结束时间、音频ID、标题、URL、媒体来源(如有声书、播客、YouTube)、类别(如人物与博客、商业、非营利与活动等)、原始完整路径和提示。每个配置都有验证和测试分割,数据量和示例数量在不同配置中有所不同。
创建时间:
2024-10-12
原始信息汇总
GigaSpeech 数据集概述
配置信息
配置 dev
- 特征:
segment_id: 字符串speaker: 字符串gt: 字符串audio: 音频,采样率 16000begin_time: 浮点数end_time: 浮点数audio_id: 字符串title: 字符串url: 字符串media_source: 分类标签,选项包括audiobook,podcast,youtubecategory: 分类标签,选项包括People and Blogs,Business,Nonprofits and Activism,Crime,History,Pets and Animals,News and Politics,Travel and Events,Kids and Family,Leisure,N/A,Comedy,Sports,Arts,Science and Technology,Autos and Vehicles,Music,Society and Culture,Education,Howto and Style,Film and Animation,Gaming,Entertainment,Health and Fitness,audiobookoriginal_full_path: 字符串prompt: 字符串
- 分割:
validation: 6750 个样本,1486742875.0 字节
- 下载大小: 1419537778 字节
- 数据集大小: 1486742875.0 字节
配置 l
- 特征: 同
dev - 分割:
validation: 6750 个样本,1486742875.0 字节test: 25619 个样本,4741534176.816 字节
- 下载大小: 5999560342 字节
- 数据集大小: 6228277051.816 字节
配置 m
- 特征: 同
dev - 分割: 同
l - 下载大小: 5999560342 字节
- 数据集大小: 6228277051.816 字节
配置 s
- 特征: 同
dev - 分割: 同
l - 下载大小: 5999560342 字节
- 数据集大小: 6228277051.816 字节
配置 test
- 特征: 同
dev - 分割:
test: 25619 个样本,4741534176.816 字节
- 下载大小: 4580022564 字节
- 数据集大小: 4741534176.816 字节
配置 xs
- 特征: 同
dev - 分割: 同
l - 下载大小: 5999560342 字节
- 数据集大小: 6228277051.816 字节
数据文件路径
dev:dev/validation-*l:l/validation-*,l/test-*m:m/validation-*,m/test-*s:s/validation-*,s/test-*test:test/test-*xs:xs/validation-*,xs/test-*
搜集汇总
数据集介绍
构建方式
GigaSpeech数据集的构建过程体现了大规模语音数据采集与标注的复杂性。该数据集通过从多种媒体来源(如播客、有声书和YouTube)获取音频数据,并对其进行精细的标注。每个音频片段均包含唯一的segment_id、说话者信息、文本转录(gt)、音频文件及其时间戳。此外,数据集还提供了音频的媒体来源、类别标签以及原始路径等元数据,确保了数据的多样性和可追溯性。
特点
GigaSpeech数据集以其规模庞大和多样性著称,涵盖了多个媒体来源和广泛的类别标签,如商业、教育、娱乐等。音频数据以16kHz或192kHz的采样率存储,确保了高质量的音质。每个音频片段均配有精确的时间戳和文本转录,便于语音识别和自然语言处理任务的研究。数据集的划分包括验证集和测试集,分别用于模型评估和性能测试,确保了数据的科学性和实用性。
使用方法
GigaSpeech数据集适用于多种语音处理任务,如自动语音识别(ASR)、说话者识别和语音合成。用户可通过HuggingFace平台下载数据集,并根据需要选择不同的配置(如dev、l、m、s、test、xl、xs)。每个配置包含验证集和测试集,用户可通过指定路径加载相应的数据文件。音频数据以标准格式存储,便于直接用于深度学习模型的训练和评估。数据集的丰富元信息也为多任务学习和跨领域研究提供了便利。
背景与挑战
背景概述
GigaSpeech数据集是一个大规模、多样化的语音识别数据集,旨在推动自动语音识别(ASR)技术的发展。该数据集由多个来源的音频数据构成,包括有声读物、播客和YouTube视频,涵盖了广泛的类别,如新闻、教育、娱乐等。GigaSpeech的创建标志着语音识别领域对大规模、多样化数据需求的响应,其丰富的音频内容和详细的元数据为研究人员提供了宝贵的资源,有助于提升ASR系统的鲁棒性和泛化能力。该数据集的发布为语音识别领域的研究和应用提供了新的基准,推动了相关技术的进步。
当前挑战
GigaSpeech数据集在构建和应用过程中面临多重挑战。首先,数据来源的多样性带来了音频质量和格式的不一致性,增加了数据清洗和预处理的复杂性。其次,大规模数据的标注工作耗时且成本高昂,尤其是在多语言和多方言环境下,标注的准确性和一致性难以保证。此外,数据集的隐私和版权问题也需谨慎处理,确保数据使用的合法性和合规性。在应用层面,如何有效利用如此大规模的数据进行模型训练,以及如何应对不同音频场景下的噪声和干扰,仍是当前研究的难点。这些挑战不仅考验了数据集的构建能力,也对语音识别技术的进一步发展提出了更高的要求。
常用场景
经典使用场景
GigaSpeech数据集在语音识别领域具有广泛的应用,尤其在自动语音识别(ASR)系统的训练和评估中表现突出。其丰富的音频数据和多样化的来源,如播客、有声书和YouTube视频,为模型提供了多样化的语音样本,帮助提升模型在不同场景下的泛化能力。
解决学术问题
GigaSpeech解决了语音识别领域中数据稀缺和多样性不足的问题。通过提供大规模、多来源的语音数据,该数据集为研究者提供了丰富的训练资源,显著提升了语音识别模型的准确性和鲁棒性。此外,其详细的元数据信息也为语音识别中的上下文理解和多任务学习提供了有力支持。
衍生相关工作
基于GigaSpeech数据集,许多经典的研究工作得以展开。例如,研究者利用该数据集开发了更高效的端到端语音识别模型,并在多语言语音识别和低资源语言识别任务中取得了显著进展。此外,该数据集还推动了语音合成和语音情感分析等领域的研究,为语音技术的全面发展提供了重要支持。
以上内容由遇见数据集搜集并总结生成


