MediBeng
收藏Hugging Face2025-04-18 更新2025-04-19 收录
下载链接:
https://huggingface.co/datasets/pr0mila-gh0sh/MediBeng
下载链接
链接失效反馈官方服务:
资源简介:
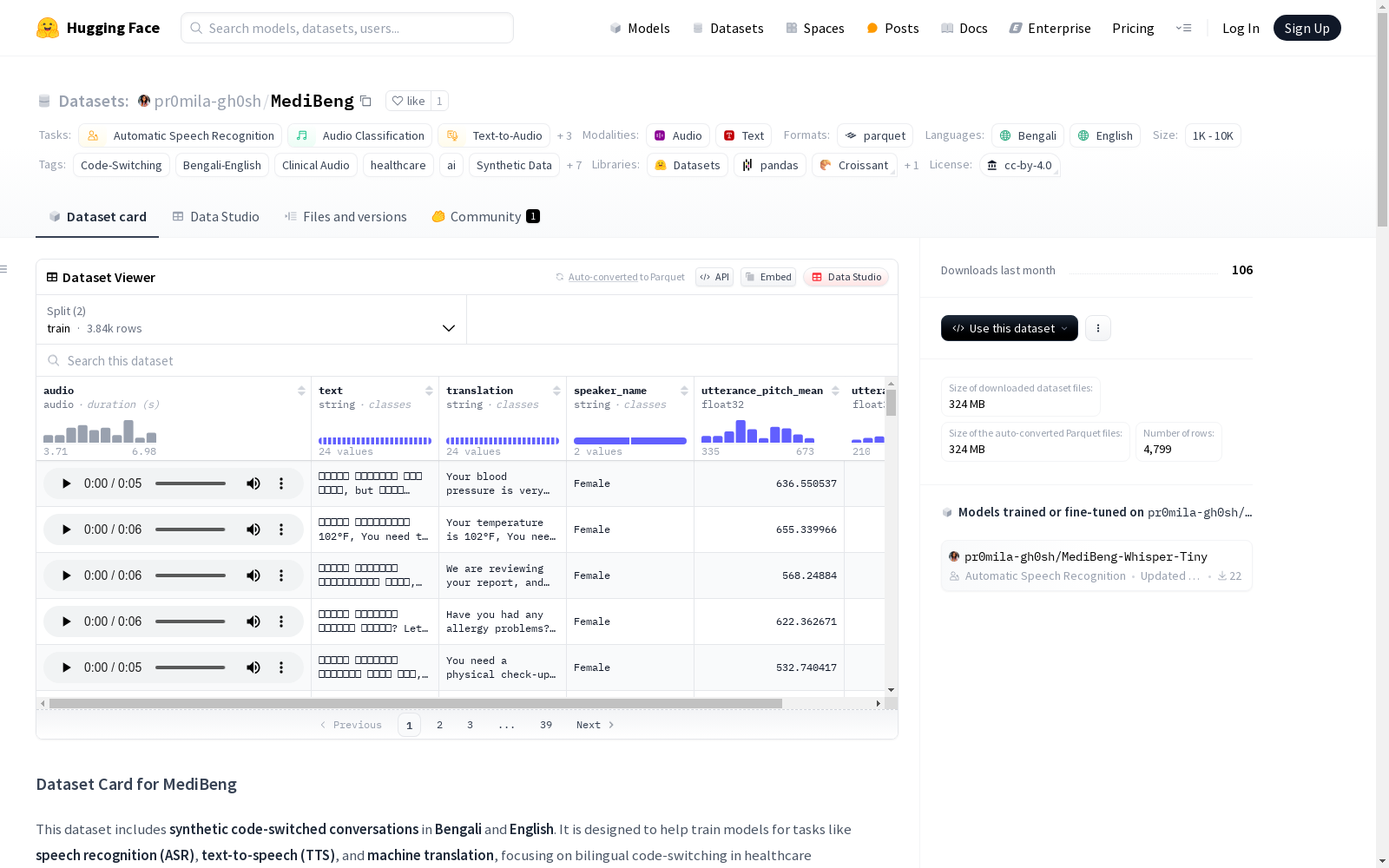
MediBeng数据集包含合成代码转换对话,涉及孟加拉语和英语在临床环境中的模拟会话。该数据集用于训练自动语音识别、文本到语音和机器翻译等模型,专注于医疗环境中的双语代码转换。
创建时间:
2025-04-14
搜集汇总
数据集介绍
构建方式
在医疗领域双语交流需求日益增长的背景下,MediBeng数据集通过系统化流程构建而成。研究者首先采集了孟加拉语和英语的双语临床对话音频,随后进行专业转录形成混合文本。为增强数据的科研价值,对音频特征进行了深度处理,包括计算基频均值和标准差等声学参数。所有数据经过结构化处理后,以Parquet格式存储并上传至开源平台,确保数据的可追溯性和可复用性。
特点
该数据集最显著的特点是模拟了真实医疗场景中的双语混用现象,包含孟加拉语和英语的混合对话文本及对应音频。每段数据均配有完整的英文翻译和说话人性别标注,并附有精细的声学特征分析。作为合成数据集,它在保护隐私的前提下,为语音识别、机器翻译等任务提供了高质量的标注数据。数据规模适中,特别适合作为补充语料用于模型微调。
使用方法
研究人员可通过HuggingFace平台直接获取该数据集,其标准化的数据结构便于快速集成到现有工作流中。数据集适用于多种自然语言处理任务,包括但不限于语音识别、文本转语音和机器翻译。使用建议先阅读配套的技术博客和GitHub文档,了解数据生成细节。对于医疗领域的特定应用,建议结合其他真实临床数据进行交叉验证以提升模型泛化能力。
背景与挑战
背景概述
MediBeng数据集由Promila Ghosh创建,旨在解决医疗场景中孟加拉语与英语代码转换(Code-Switching)的语音识别与翻译问题。该数据集专注于临床语境下的双语混合对话,通过合成数据模拟医患交流,为自动语音识别(ASR)、机器翻译及文本转语音(TTS)任务提供训练资源。其合成特性确保了数据隐私性,同时填补了低资源语言在医疗AI领域的空白,对提升多语言医疗服务的可及性具有重要价值。
当前挑战
该数据集面临的核心挑战包括:1)合成数据与真实临床对话的语义差异可能导致模型泛化能力受限;2)小规模数据(1K<n<10K)难以支撑端到端大模型训练;3)音高特征等工程化设计需平衡语言学准确性与计算效率。构建过程中,需克服孟加拉语-英语混合语序的非规则性,以及医疗术语跨语言对齐的复杂性,这些因素对数据生成的逼真度提出了更高要求。
常用场景
经典使用场景
在医疗健康领域,双语混合对话的自动处理需求日益增长。MediBeng数据集通过模拟孟加拉语和英语的临床对话场景,为语音识别(ASR)、文本转语音(TTS)和机器翻译任务提供了理想的训练素材。其合成的双语混合对话特别适合研究医疗环境中的语言切换现象,为模型在复杂语言环境下的性能优化提供了重要支持。
实际应用
在实际应用中,MediBeng数据集为开发医疗辅助系统提供了关键支持。基于该数据集训练的模型能够准确识别和翻译双语混合的医患对话,显著提升了医疗服务的可及性。特别是在孟加拉语地区,这类技术可以帮助克服语言障碍,改善医疗信息传递效率,为多语言医疗环境下的沟通问题提供了切实可行的解决方案。
衍生相关工作
围绕MediBeng数据集,研究者们已开展多项重要工作。其中最突出的是MediBeng Whisper-Tiny项目,该项目专注于医疗场景下的双语语音翻译,显著提升了模型在临床环境中的表现。此外,该数据集还催生了一系列关于医疗领域语言切换、跨语言信息处理的研究,为相关领域的技术发展奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


