LargeScaleASR
收藏Hugging Face2025-01-22 更新2025-01-23 收录
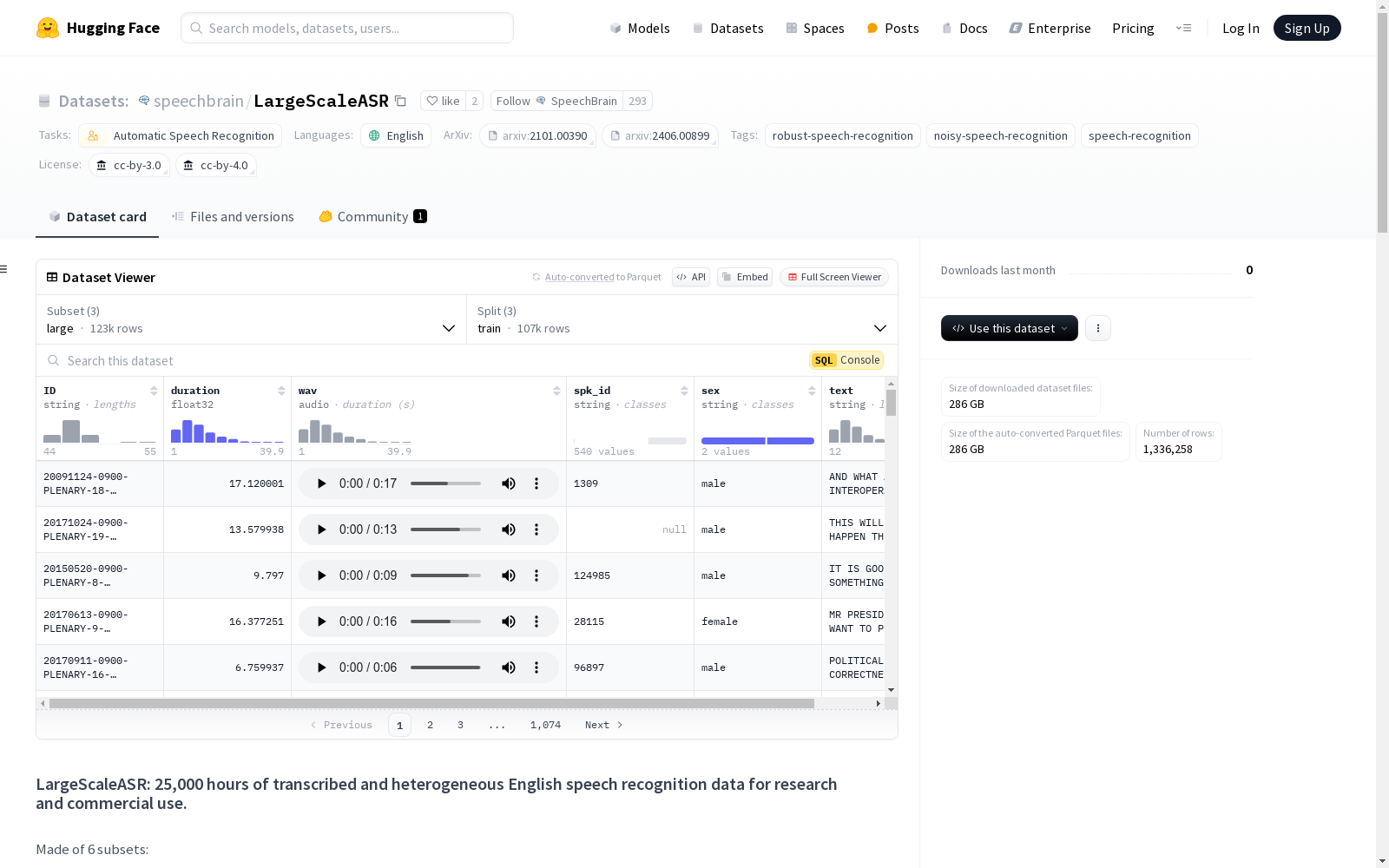
下载链接:
https://huggingface.co/datasets/speechbrain/LargeScaleASR
下载链接
链接失效反馈官方服务:
资源简介:
LargeScaleASR数据集是一个包含25,000小时转录和异构英语语音识别数据的数据集,适用于研究和商业用途。数据集由6个子集组成,分别是large、medium、small、clean、dev和test,每个子集包含不同小时数的转录语音数据。数据集主要用于自动语音识别任务,特别是鲁棒语音识别和噪声语音识别。数据集的创建涉及多个现有数据集的混合,包括VoxPopuli、LibriHeavy、Librispeech、YODAS、People's Speech和CommonVoice 18.0。数据集中的文本和音频都经过了标准化处理,以确保数据的一致性和质量。
The LargeScaleASR dataset is a collection of 25,000 hours of transcribed and heterogeneous English speech recognition data, suitable for both research and commercial use cases. The dataset comprises six subsets, namely large, medium, small, clean, dev, and test, with each subset containing transcribed speech data of varying durations. This dataset is primarily utilized for automatic speech recognition (ASR) tasks, especially robust speech recognition and noisy speech recognition. The creation of the dataset involves mixing multiple existing datasets, including VoxPopuli, LibriHeavy, LibriSpeech, YODAS, People's Speech, and CommonVoice 18.0. Both the textual and audio data in the dataset have been standardized to ensure data consistency and quality.
提供机构:
SpeechBrain
创建时间:
2025-01-22
搜集汇总
数据集介绍
构建方式
LargeScaleASR数据集通过整合多个现有数据集构建而成,涵盖了VoxPopuli、LibriHeavy、Librispeech、YODAS、People's Speech和CommonVoice 18.0等数据集。这些数据集的选择基于其开放的许可协议,并通过混合不同数据源的方式生成大规模、多样化的语音识别数据。数据集的构建过程中,特别关注了数据的多样性和质量,确保包含不同场景下的语音样本,如朗读、自发语音、干净语音和噪声语音。此外,数据集的文本和音频均经过标准化处理,以确保转录的准确性和一致性。
特点
LargeScaleASR数据集的特点在于其规模庞大且多样性丰富,涵盖了25,000小时的英语语音数据,分为多个子集,包括large、medium、small、clean、dev和test。每个子集针对不同的研究需求提供不同规模的语音样本。数据集特别注重语音的多样性,包含干净和噪声环境下的语音,以及朗读和自发语音的混合。此外,数据集的文本经过严格的标准化处理,确保转录的准确性和一致性,适合用于训练和评估鲁棒的语音识别模型。
使用方法
LargeScaleASR数据集的使用方法较为灵活,用户可以通过HuggingFace的`datasets`库加载数据集,并选择不同的子集(如small、medium或large)进行实验。加载后的数据包含音频文件、转录文本、说话者ID、性别等信息,用户可以直接用于语音识别模型的训练和评估。音频数据以原始字节形式存储,可通过`torchaudio`等工具解码。此外,数据集提供了详细的文档和示例代码,帮助用户快速上手并应用于实际研究中。
背景与挑战
背景概述
LargeScaleASR数据集由SpeechBrain团队于2024年发布,旨在为自动语音识别(ASR)领域提供大规模的、多样化的语音数据。该数据集整合了来自多个现有数据集的25,000小时英语语音数据,涵盖了朗读与自发语音、干净与嘈杂环境下的语音样本。其核心研究问题在于提升语音识别系统在复杂环境下的鲁棒性,尤其是在噪声干扰和多样化语音风格下的表现。该数据集的发布为语音识别领域的研究与商业应用提供了重要的数据支持,推动了ASR技术的进一步发展。
当前挑战
LargeScaleASR数据集在构建过程中面临多重挑战。首先,数据来源的多样性导致语音质量和转录准确性的不一致,尤其是来自YouTube的YODAS数据集存在大量语言识别错误和噪声转录。其次,文本和音频的标准化处理是另一大挑战,需通过复杂的文本处理工具对转录内容进行规范化,以确保发音的准确性。此外,数据集的存储与处理需求极高,仅大规模配置就需4TB存储空间,这对计算资源提出了较高要求。这些挑战不仅体现在数据集的构建过程中,也反映了语音识别领域在噪声环境下的技术瓶颈。
常用场景
经典使用场景
LargeScaleASR数据集在自动语音识别(ASR)领域中被广泛用于训练和评估模型。其包含的大量多样化语音数据,涵盖了从清晰到嘈杂、从朗读到自发对话的多种场景,使得研究者能够在不同环境下测试模型的鲁棒性和准确性。该数据集特别适用于开发能够在复杂声学环境中稳定工作的语音识别系统。
实际应用
在实际应用中,LargeScaleASR数据集被广泛用于开发智能语音助手、语音转文字工具以及实时语音翻译系统。其多样化的语音数据使得这些应用能够在各种现实场景中表现出色,例如在嘈杂的公共场所或具有不同口音的用户群体中。此外,该数据集还被用于语音识别技术的商业化产品中,以提升用户体验。
衍生相关工作
基于LargeScaleASR数据集,许多经典的研究工作得以展开。例如,SpeechBrain团队利用该数据集开发了一系列开源的语音识别工具,并在多个国际比赛中取得了优异的成绩。此外,该数据集还催生了许多关于噪声鲁棒性、多语言语音识别以及端到端语音识别模型的研究,推动了语音识别技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


