bacformer-genome-embeddings-with-phenotypic-traits-labels
收藏Hugging Face2025-05-29 更新2025-05-30 收录
下载链接:
https://huggingface.co/datasets/macwiatrak/bacformer-genome-embeddings-with-phenotypic-traits-labels
下载链接
链接失效反馈官方服务:
资源简介:
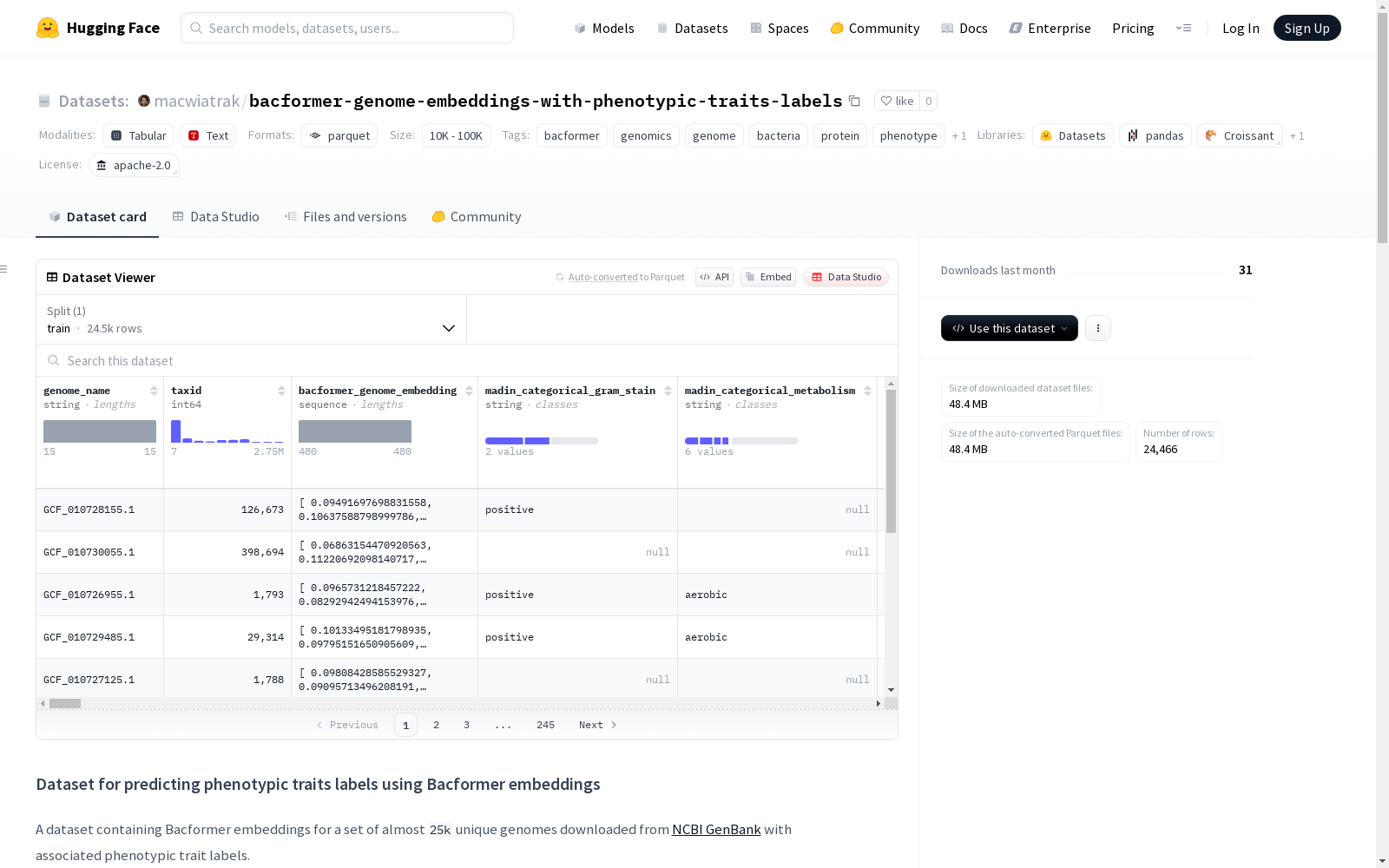
Bacformer基因组成embedding与表型特征标签数据集,包含来自NCBI GenBank的约25k个独特基因组的embedding,以及与之相关的表型特征标签。
创建时间:
2025-05-28
原始信息汇总
Bacformer基因组嵌入与表型性状标签数据集概述
数据集基本信息
- 许可证: Apache-2.0
- 标签: bacformer, genomics, genome, bacteria, protein, phenotype, prokaryotes
- 数据集名称: Bacformer genome embeddings with phenotypic traits labels dataset
- 数据规模: 10K < n < 100K
数据集内容
- 数据来源: 包含来自NCBI GenBank的近25k个独特基因组的Bacformer嵌入
- 表型性状标签:
- 从多个来源提取的139个独特分类表型性状
- 排除样本数量较少的表型性状
- 相同或相似标签在不同来源中保持独立
嵌入生成方法
- 模型: 使用macwiatrak/bacformer-masked-complete-genomes进行推理
- 处理方式: 通过平均上下文蛋白质嵌入获得基因组嵌入
使用方式
- 教程链接: 提供表型性状预测教程
- 代码示例: 包含使用线性回归模型预测表型的完整代码片段
联系方式
- 问题反馈: 通过GitHub仓库提交问题或功能请求
参考文献
- Madin, Joshua S., et al. (2020)
- Weimann, Aaron, et al. (2016)
- Brbić, Maria, et al. (2016)
搜集汇总
数据集介绍
构建方式
该数据集构建于微生物基因组学领域,整合了近2.5万个来自NCBI GenBank的独特基因组数据。通过提取多个权威文献[1,2,3]中的分类表型特征,经过严格筛选保留139个具有统计学意义的性状标签。基因组嵌入表示采用Bacformer模型推理生成,通过对上下文蛋白质嵌入进行平均池化得到每个基因组的特征向量,确保了表征的全面性和生物学相关性。
特点
作为微生物表型预测领域的重要资源,该数据集具有三个显著特征:其一是涵盖广泛的细菌表型标签,包括代谢特征和环境适应性等多元分类;其二是采用先进的Bacformer模型生成基因组级嵌入,捕获了蛋白质序列的深层语义信息;其三是经过严格的数据清洗,剔除低频表型并保持不同来源标签的独立性,确保数据质量满足机器学习建模需求。
使用方法
该数据集特别适合开发基因组表型预测模型,典型工作流程包括数据加载、表型选择、分层抽样和分类器训练。如示例代码所示,可采用逻辑回归等经典算法构建预测管道,通过标准化处理和超参数优化提升模型性能。数据集配套的Jupyter Notebook教程详细演示了从特征提取到模型评估的全流程,研究者可快速复现实验或开发新型预测算法。
背景与挑战
背景概述
Bacformer基因组嵌入与表型性状标签数据集由研究者Maciej Wiatrak等人构建,旨在通过深度学习模型Bacformer生成的基因组嵌入预测微生物的表型特征。该数据集整合了近25,000个来自NCBI GenBank的独特基因组数据,并关联了139个经过筛选的多样性表型性状标签,数据来源包括Madin等人和Weimann等人的研究成果。该数据集的建立为微生物基因组学领域提供了一种高效的表型预测方法,推动了基因组数据与表型关联研究的深入发展。
当前挑战
该数据集面临的核心挑战包括表型性状标签的稀疏性与异质性,部分性状样本量不足可能导致模型训练偏差。基因组嵌入的计算依赖于Bacformer模型的推理能力,其性能受限于蛋白质序列的上下文表示质量。此外,数据整合过程中需处理不同来源标签的语义差异,确保预测任务的可靠性。构建过程中,基因组数据的规模与复杂性也对计算资源提出了较高要求。
常用场景
经典使用场景
在微生物基因组学研究领域,Bacformer基因组嵌入与表型性状标签数据集为探索基因组与表型之间的复杂关联提供了重要工具。该数据集通过整合近25,000个来自NCBI GenBank的独特基因组及其对应的139种分类表型性状,为研究人员提供了一个全面的基准平台。其经典使用场景包括训练机器学习模型,以预测细菌的特定表型特征,如催化酶活性或抗生素抗性等。
实际应用
在实际应用中,该数据集支持了多个重要场景的开发。临床微生物学领域可利用其预测病原菌的致病性或药物敏感性,辅助诊断和治疗决策。工业微生物领域则通过预测菌株的代谢特性优化生物制造流程。环境科学研究者能够评估微生物群落在不同生态系统中的功能潜力,为生物修复提供理论依据。
衍生相关工作
基于该数据集已衍生出多项经典研究工作。部分研究聚焦于改进基因组嵌入方法,如开发更高效的蛋白质上下文嵌入算法。另一些工作则探索了多任务学习框架,以同时预测多个相关表型性状。此外,该数据集还被用于评估不同机器学习模型在表型预测任务中的性能,为方法学比较提供了标准化基准。
以上内容由遇见数据集搜集并总结生成


