waxal-orm-tts-merged
收藏Hugging Face2026-05-15 更新2026-05-16 收录
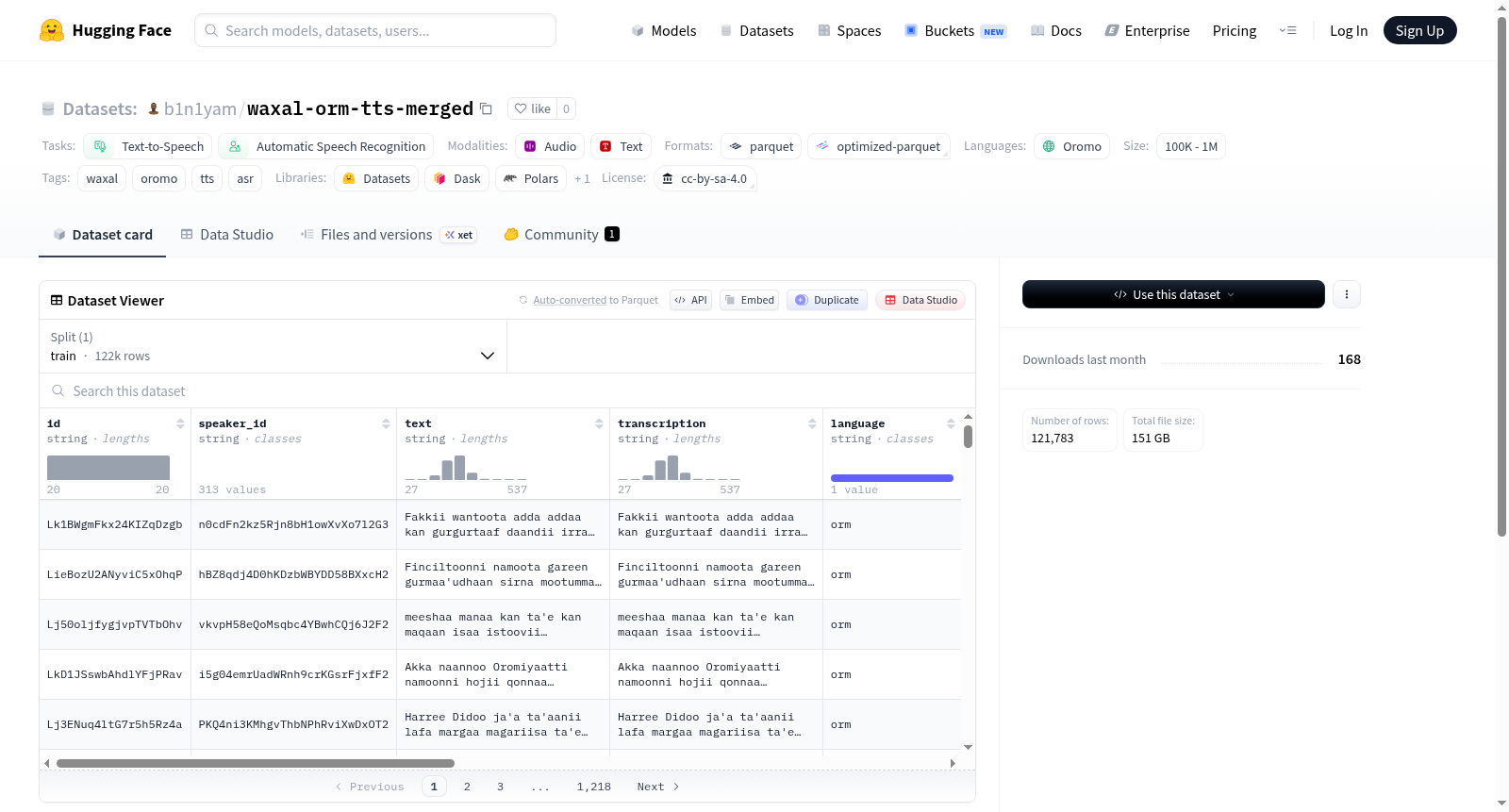
下载链接:
https://huggingface.co/datasets/b1n1yam/waxal-orm-tts-merged
下载链接
链接失效反馈官方服务:
资源简介:
Waxal Oromo TTS Merged 是一个专为奥罗莫语(Oromo)设计的语音处理数据集,适用于文本转语音(TTS)和自动语音识别(ASR)任务。该数据集合并了两个来源的数据:来自 `google/WaxalNLP` 的人工标注奥罗莫语ASR部分,以及来自 `israel/waxal-autolabled` 的自动标注奥罗莫语部分。为优化TTS使用,数据预处理阶段移除了自动标注转录中开头的 `[ORM]` 语言标签。数据集以结构化行形式组织,每行包含 `text` 和 `transcription` 两个字段,这两个字段的值经过清理后保持一致。数据以Parquet格式存储,文件路径为 `data/train-*.parquet`。数据集遵循CC BY-SA 4.0许可证,旨在支持奥罗莫语的语音合成与识别研究与应用。
Waxal Oromo TTS Merged is a speech processing dataset specifically designed for the Oromo language, suitable for text-to-speech (TTS) and automatic speech recognition (ASR) tasks. The dataset merges data from two sources: the manually annotated Oromo ASR portion from `google/WaxalNLP`, and the automatically annotated Oromo portion from `israel/waxal-autolabled`. To optimize for TTS usage, the preprocessing phase removed the leading `[ORM]` language tag from the automatic transcriptions. The dataset is organized in structured rows, each containing two fields: `text` and `transcription`, with their values cleaned to ensure consistency. Data is stored in Parquet format, with file paths as `data/train-*.parquet`. It follows the CC BY-SA 4.0 license and aims to support research and applications in Oromo speech synthesis and recognition.
创建时间:
2026-05-13
原始信息汇总
数据集概述
数据集名称:Waxal Oromo TTS Merged
许可证:CC-BY-SA-4.0
任务类别:文本到语音(TTS)、自动语音识别(ASR)
语言:奥罗莫语(orm)
数据集描述
该数据集是合并数据集,整合了两个来源:
google/WaxalNLP中人工标注的奥罗莫语 ASR 子集。israel/waxal-autolabled中自动标注的奥罗莫语子集。
数据处理
- 为适配 TTS 使用,已从自动标注的转录文本中移除开头的
[ORM]语言标签。 - 数据行包含
text和transcription字段,两者具有相同的清洗后内容。
数据配置
- 默认配置名称:
default - 数据文件位置:
data/train-*.parquet - 数据拆分:训练集(train)
搜集汇总
数据集介绍
构建方式
该数据集名为waxal-orm-tts-merged,旨在融合两种不同来源的阿姆哈拉语(Oromo)语音数据,以构建一个更为全面且适用于文本转语音(TTS)及自动语音识别(ASR)任务的语料库。其构建过程巧妙整合了来自`google/WaxalNLP`的人工标注ASR分割数据与`israel/waxal-autolabled`的自动标注分割数据。针对TTS应用场景,数据集中自动标注转录文本前端的`[ORM]`语言标记已被系统性移除,从而确保每个数据行中的`text`与`transcription`字段均包含经过清洗后的一致性文本内容。最终,这些数据以Parquet格式统一存储在`data/train-*.parquet`文件中,便于高效加载与处理。
使用方法
使用该数据集时,用户可直接通过HuggingFace Datasets库加载,指定配置名为`default`并读取`train`分割,数据文件路径为`data/train-*.parquet`。对于TTS任务,模型可直接利用`text`或`transcription`字段作为目标文本输入,无需额外预处理;对于ASR任务,则可使用语音特征与对应转录文本进行训练。由于数据集已统一清洗格式,开发者仅需关注音频特征与文本之间的映射关系,显著降低了数据适配成本。推荐将数据集用于训练端到端TTS系统、多语种语音合成模型或低资源语言的语音识别基线模型。
背景与挑战
背景概述
在低资源语言的自然语言处理领域,数据稀缺是制约语音合成(TTS)和自动语音识别(ASR)技术发展的关键瓶颈。Oromo语作为非洲之角广泛使用的库希特语族语言,其数字化语言资源长期匮乏,严重阻碍了相关语音技术的突破。为此,研究人员于近年创建了Waxal Oromo TTS Merged数据集,该数据集由多个机构合作完成,核心研究人员来自Google和独立研究者,其研究问题聚焦于通过融合人工标注与自动标注的Oromo语语音数据,构建一个高质量、统一的语音数据集,以支持TTS和ASR模型的训练。该数据集的发布填补了Oromo语在语音技术领域的空白,对推动低资源语言的语音交互应用具有重要影响力。
当前挑战
该数据集面临的核心挑战源于Oromo语的低资源属性。在领域问题层面,构建高保真度TTS系统需要文本与语音的精准对齐,而Oromo语的复杂音系结构和变体使得自动标注的转录文本存在噪声,影响模型生成语音的自然度和准确性。在构建过程中,数据集合并了来自不同来源的标注数据,人工标注与自动标注的标签格式不一致,如自动标注中需移除的前置语言标记,这要求细致的文本清洗和标准化工作。此外,如何确保合并后数据在各层面的连贯性,避免因标注差异引入偏差,也是构建过程中的一大挑战。
常用场景
经典使用场景
该数据集融合了WaxalNLP项目的人工标注与自动标注语料,专为奥罗莫语(Oromo)的文本到语音合成(TTS)与自动语音识别(ASR)任务设计。在TTS场景中,研究者利用其高质量文本-语音配对样本,训练神经网络模型将输入文本转换为流畅自然的奥罗莫语音频;在ASR场景中,则可用于训练语音识别系统,将奥罗莫语口语信号精准转录为文字。其合并策略有效扩大了低资源语言的训练数据规模,为构建鲁棒的端到端语音系统提供了基础。
解决学术问题
该数据集直面奥罗莫语等低资源语言在语音技术中的数据稀缺困境。通过整合人工与自动化两种标注管道,解决了传统TTS/ASR数据集标注成本高昂、覆盖不足的核心问题。在学术层面,它推动了跨语言迁移学习与半监督训练方法的探索,使得研究者能够评估不同标注质量对模型性能的影响,并为语音合成中的音素对齐、韵律建模等难题提供了实验基准,具有推动非洲语言语音技术民主化的重要意义。
实际应用
在实际应用中,该数据集可直接用于开发面向奥罗莫语用户的智能语音助手、语音导航系统及语音内容播报工具。例如,在埃塞俄比亚的公共信息播报、农业技术推广或教育场景中,TTS模型能够将文本信息实时转换为语音,服务识字率较低的群体。ASR模型则可部署于语音搜索、会议转写或客户服务热线,打通人机语音交互的最后屏障,显著提升奥罗莫语社区的数字包容性。
数据集最近研究
最新研究方向
在低资源语言语音合成与识别领域,Waxal Oromo TTS Merged数据集为奥罗莫语(Oromo)的多模态研究提供了关键支撑。近期前沿方向聚焦于融合人工标注与自动标注语音数据,以缓解低资源语言标注匮乏的瓶颈,推动端到端文本转语音(TTS)与自动语音识别(ASR)联合建模。该数据集通过去除语言标签并统一转录文本,显著提升了跨任务数据复用性,为非洲语言语音技术的公平发展奠定基础,呼应了全球AI领域对语言多样性的关注。其合并策略有望成为其他濒危语言数据集构建的范本,加速“数字语言平等”进程。
以上内容由遇见数据集搜集并总结生成


