Low-Quality Vision Deep DataDriven Datasets for RL (LQV-D4RL)
收藏arXiv2024-06-13 更新2024-06-18 收录
下载链接:
https://sites.google.com/view/semopo
下载链接
链接失效反馈官方服务:
资源简介:
LQV-D4RL是由南京大学等机构创建的数据集,专门设计用于深度数据驱动的强化学习研究。该数据集包含15个不同的设置,来源于DMControl Suite和Gym环境,数据由非专家策略收集,包含移动干扰因素。创建过程中采用了保守采样方法,以分离任务相关和无关的信息。LQV-D4RL旨在解决从低质量视觉数据中学习高质量策略的挑战,适用于需要处理复杂视觉输入的强化学习任务。
LQV-D4RL is a dataset created by Nanjing University and other institutions, specifically designed for deep data-driven reinforcement learning research. It includes 15 distinct settings derived from the DMControl Suite and Gym environments, with data collected by non-expert policies and featuring moving interference factors. A conservative sampling method was adopted during its creation to separate task-relevant and task-irrelevant information. LQV-D4RL aims to address the challenge of learning high-quality policies from low-quality visual data, and is suitable for reinforcement learning tasks that require processing complex visual inputs.
提供机构:
南京大学人工智能学院,中国 2国家软件新技术重点实验室,南京大学,中国 3北京大学数学科学学院,统计科学中心,北京,中国 4北京理工大学网络空间科学与技术学院,北京,中国
创建时间:
2024-06-13
搜集汇总
数据集介绍
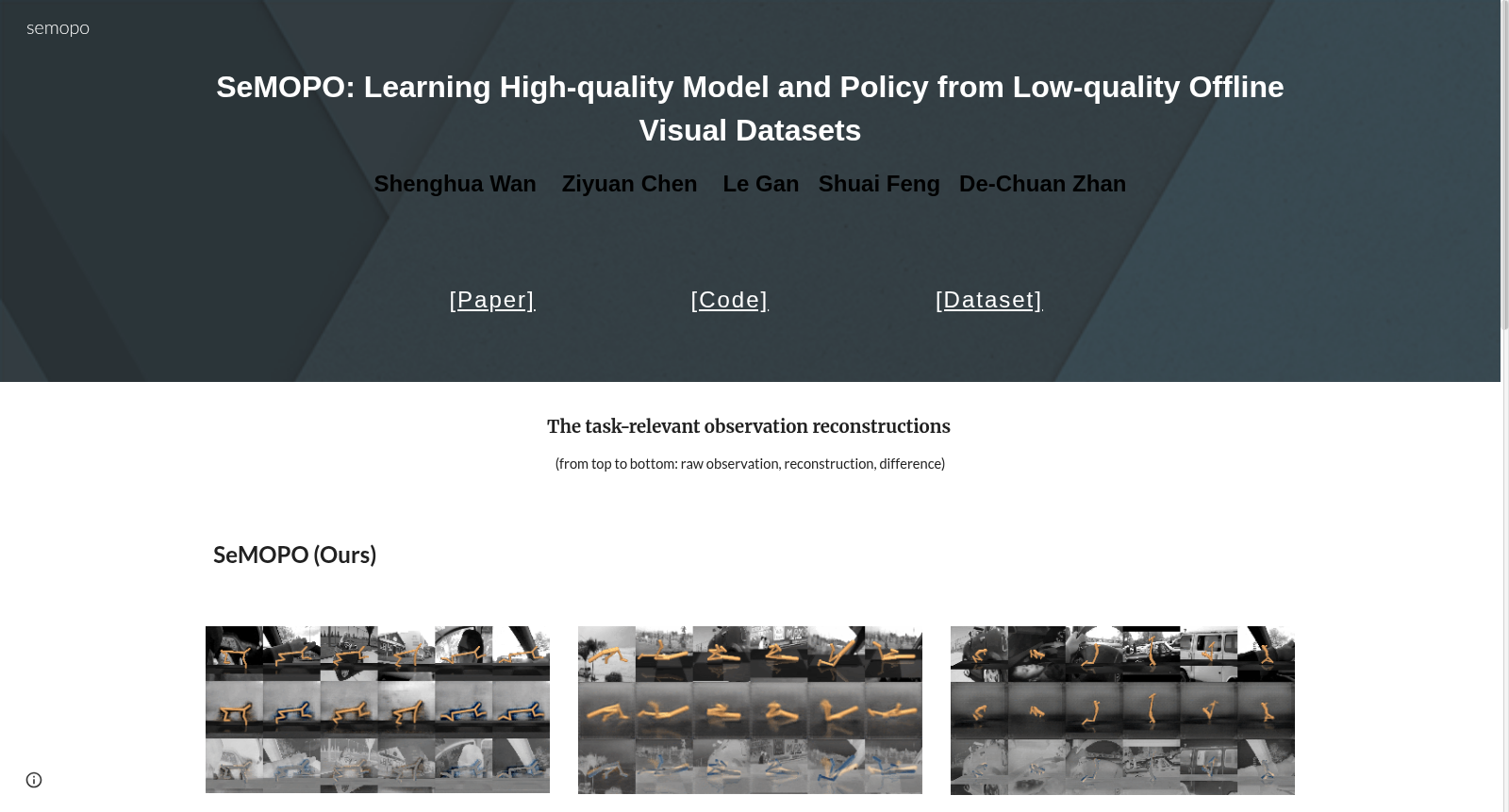
构建方式
在离线强化学习领域,面对从包含复杂干扰物的视觉数据中学习高质量策略的挑战,LQV-D4RL数据集的构建旨在模拟真实场景中低质量数据的特点。该数据集基于DeepMind Control Suite和Gym环境,选取了Walker Walk、Cheetah Run、Hopper Hop、Humanoid Walk及Car Racing五个任务,每个任务下设置了随机策略、中等回放缓冲区和中等性能策略三种数据收集模式。数据采集过程中,观察图像被替换为Kinetics数据集中“驾驶汽车”类别的动态视频背景,以引入具有非平凡动态的复杂干扰。轨迹长度统一为1000步,随机与中等数据集各包含200条轨迹,中等回放数据集则包含400条轨迹,确保了数据在行为策略多样性与状态覆盖范围上的平衡。
特点
LQV-D4RL数据集的核心特征体现在其刻意设计的“低质量”属性上,这包括两个方面:一是数据由非专家或随机策略收集,反映了现实世界中数据来源的普遍次优性;二是观察图像中嵌入了动态背景干扰,模拟了高维视觉输入中常见的任务无关噪声。这种设计使得数据集能够有效评估算法在存在分布偏移和复杂视觉干扰下的鲁棒性。此外,数据集覆盖了从连续控制到赛车游戏的多样化任务,并提供了三种不同性能水平的行为策略数据,为研究离线视觉强化学习中的模型不确定性估计、策略优化及泛化能力提供了丰富的基准场景。
使用方法
使用LQV-D4RL数据集时,研究者通常遵循离线强化学习的标准流程,即从固定数据集中学习策略而无需与环境在线交互。数据集以图像观察、动作和奖励序列的形式提供,可直接用于训练基于模型或无模型的离线强化学习算法。对于基于模型的方法,建议先利用数据集训练动态模型和奖励模型,再在学得模型上进行策略优化;同时,可借鉴SeMOPO等方法,通过分离内生与外生状态来更精准地估计模型不确定性,以缓解分布偏移问题。评估时,应在与训练数据相同但干扰背景可能不同的在线环境中测试学得策略的性能,并使用归一化回报等指标进行量化比较,以全面衡量算法在低质量视觉数据下的学习效果。
背景与挑战
背景概述
在离线强化学习领域,处理高维视觉输入并从中学习有效策略已成为一项关键挑战。LQV-D4RL数据集由Shenghua Wan等人于2024年构建,旨在模拟现实世界中数据收集的典型困境:数据集通常由非专家策略生成,且观测中包含具有复杂动态的干扰信息。该数据集基于DMControl Suite和Gym环境构建,涵盖随机、中等重放和中等性能三种策略水平,并在观测背景中引入了动态视频干扰。其核心研究问题在于如何从这种低质量的离线视觉数据中学习高质量的世界模型与策略,从而推动离线视觉强化学习在自动驾驶、机器人控制等实际场景中的应用。
当前挑战
LQV-D4RL数据集面临的挑战主要体现在两个方面:在领域问题层面,其旨在解决从包含动态干扰的离线视觉数据中学习鲁棒策略的难题,这要求模型能够准确区分任务相关与任务无关的观测成分,并克服分布偏移问题;在构建过程中,数据收集需模拟非专家策略的行为,并引入具有非平凡动态的背景干扰,这增加了数据生成的复杂性与真实性。此外,如何确保数据集在不同任务与策略水平下具有足够的多样性与挑战性,以全面评估方法的泛化能力,亦是构建过程中的关键挑战。
常用场景
经典使用场景
在视觉强化学习领域,处理低质量离线数据集已成为一项关键挑战。LQV-D4RL数据集专为评估模型在复杂视觉干扰下的鲁棒性而设计,其经典使用场景集中于从包含动态背景噪声的高维图像观测中学习有效策略。该数据集模拟了现实世界中由非专家策略收集的数据,并引入了具有非平凡动态的移动干扰物,为研究离线视觉强化学习算法提供了标准化测试平台。通过在Walker Walk、Cheetah Run等经典控制任务中嵌入Kinetics视频背景,LQV-D4RL能够系统评估算法在存在视觉干扰时的策略学习能力,成为该领域方法验证的核心基准。
衍生相关工作
基于LQV-D4RL数据集的研究催生了多个经典工作的发展。SeMOPO方法通过保守采样策略分离内生与外生状态,显著提升了离线视觉强化学习的性能。该数据集还促进了对外生块马尔可夫决策过程理论框架的深入探索,为后续研究提供了新的理论分析工具。在方法层面,它推动了如Offline DV2、LOMPO等模型基方法的改进,同时也启发了对DrQ+BC、InfoGating等模型无关方法的适应性研究。这些衍生工作共同推动了处理视觉干扰的离线强化学习技术发展,形成了该领域的重要研究脉络。
数据集最近研究
最新研究方向
在离线强化学习领域,面对由非专家策略收集且包含复杂视觉干扰的低质量数据集,LQV-D4RL数据集的推出标志着研究重心转向如何从这类噪声观测中稳健地学习高质量策略。前沿研究聚焦于基于模型的离线方法,特别是通过状态分解来区分任务相关与无关的动态信息。以SeMOPO方法为代表,其核心创新在于引入外生块马尔可夫决策过程框架,将潜在状态分离为内生的任务相关部分和外生的干扰部分,并辅以保守采样策略,从而更精准地估计模型不确定性。这一方向不仅有效缓解了分布偏移问题,提升了在含噪声视觉输入下的策略性能,也为自动驾驶、机器人控制等需从现实世界嘈杂数据中学习的应用提供了新的基准和理论保障。
相关研究论文
- 1SeMOPO: Learning High-quality Model and Policy from Low-quality Offline Visual Datasets南京大学人工智能学院,中国 2国家软件新技术重点实验室,南京大学,中国 3北京大学数学科学学院,统计科学中心,北京,中国 4北京理工大学网络空间科学与技术学院,北京,中国 · 2024年
以上内容由遇见数据集搜集并总结生成


