VQPP
收藏Hugging Face2026-05-03 更新2026-05-04 收录
下载链接:
https://huggingface.co/datasets/funzon3/VQPP
下载链接
链接失效反馈官方服务:
资源简介:
VQPP(视频查询性能预测基准)是一个用于评估视频检索系统中文本查询难度估计方法的基准数据集。该数据集旨在标准化对预检索和后检索QPP估计器的评估,涵盖两个数据集(MSR-VTT和VATEX)以及两种先进的检索架构(GRAM和VAST)。数据集包含GRAM和VAST检索系统的性能数据,分为两个主要部分:metrics(包含地面真实RR和Recall分数,分为训练集、验证集和测试集)和top100(包含用于后检索分析的前100个检索视频ID)。数据集结构清晰,适用于视频检索性能预测任务的研究和评估。
创建时间:
2026-04-29
原始信息汇总
数据集概述
数据集名称:VQPP (Video Query Performance Prediction Benchmark)
许可证:MIT
数据集用途:用于评估视频检索系统中文本查询难度估计方法的基准数据集。
数据集核心内容
VQPP 是一个标准化评估基准,支持对两类查询性能预测(QPP)估计器(预检索和后检索)进行评估,涵盖以下内容:
- 两个视频数据集:MSR-VTT 和 VATEX
- 两种检索架构:GRAM 和 VAST
数据组织与划分
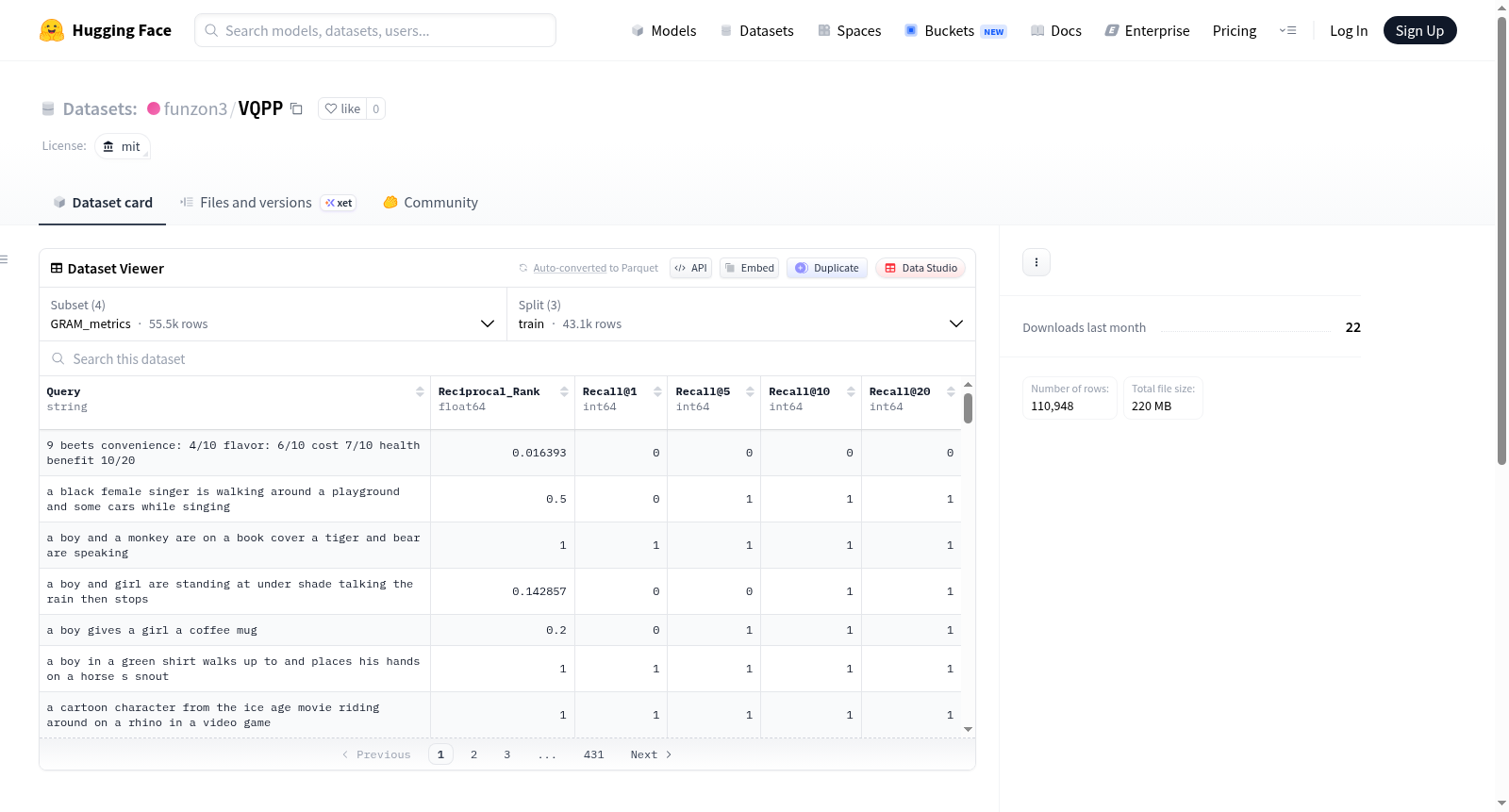
数据集包含四个配置(config),每个配置下均划分为训练集(train)、验证集(validation)和测试集(test):
| 配置名称 | 对应检索架构 | 数据内容 |
|---|---|---|
| GRAM_metrics | GRAM | 检索系统的真实 RR 和 Recall 分数 |
| GRAM_top100 | GRAM | 用于后检索分析的 Top-100 检索视频 ID |
| VAST_metrics | VAST | 检索系统的真实 RR 和 Recall 分数 |
| VAST_top100 | VAST | 用于后检索分析的 Top-100 检索视频 ID |
数据文件路径结构
├── GRAM/ │ ├── metrics/ # 真实 RR 和 Recall 分数(训练/验证/测试) │ └── top100/ # 前100检索视频 ID(训练/验证/测试) └── VAST/ ├── metrics/ # 真实 RR 和 Recall 分数(训练/验证/测试) └── top100/ # 前100检索视频 ID(训练/验证/测试)
搜集汇总
数据集介绍
构建方式
VQPP基准数据集旨在系统评估视频检索查询性能预测(QPP)方法的有效性。该数据集基于MSR-VTT与VATEX两个经典视频文本检索数据集,并整合了GRAM与VAST两种前沿检索架构。构建过程中,首先利用上述检索系统对查询进行处理,收集每项查询的逆序排名(RR)和召回率(Recall)作为真实性能指标。同时,额外存储每次检索返回的前100个视频ID,以供后检索QPP分析使用。数据按照标准比例划分为训练、验证与测试子集,分别存放于GRAM与VAST目录下的metrics和top100文件夹中,形成了结构清晰、层次分明的评估资源。
特点
VQPP具备跨数据集与跨架构的双重标准化特性,能够全面检验QPP估计器在多样化场景中的泛化能力。其独特之处在于同时提供前检索与后检索两类QPP方法的评估支持:通过metrics中的真实性能分数可实现前检索估计器的对比,而top100中的检索结果则为后检索方法提供了分析基础。此外,数据集严格遵守MIT开源协议,所有配置均经过精心设计,覆盖训练、验证与测试三阶段,确保实验的可重复性与公平性,为视频检索领域中的查询难度预测提供了坚实且统一的基准平台。
使用方法
在实际使用中,研究者可通过HuggingFace Datasets库便捷加载VQPP。只需指定所需配置名称,如'GRAM_metrics'、'GRAM_top100'、'VAST_metrics'或'VAST_top100',即可获取相应子集。每个配置均包含train、validation与test三个标准划分,满足模型开发与评估全流程需求。metrics配置可直接用于前检索QPP方法的性能比较,而top100配置则支持后检索分析。数据默认采用文件匹配模式自动识别路径下的所有文件,使用极为灵活。建议用户根据研究目标选择合适的检索系统与指标类型,充分发挥该基准的评测价值。
背景与挑战
背景概述
视频检索系统在多媒体信息处理领域占据着举足轻重的地位,其性能受查询文本质量与难度的影响显著。VQPP(Video Query Performance Prediction Benchmark)数据集应运而生,旨在为视频查询性能预测(QPP)提供标准化评估基准。该数据集由相关研究团队于论文中正式提出,依托MSR-VTT与VATEX两大经典视频数据集,结合GRAM与VAST两种前沿检索架构,系统性地构建了涵盖预检索与后检索策略的QPP评估框架。通过提供基于Reciprocal Rank(RR)和Recall的准确性标注,VQPP为探寻查询难度预测方法、优化视频检索系统提供了关键数据支撑,推动了该领域从经验性评估向标准化评测的转变。
当前挑战
VQPP数据集所面临的挑战主要聚焦于两大层面。其一,在领域问题层面,视频查询性能预测需应对查询多变、视频内容语义复杂及检索结果波动等难题,现有QPP方法在跨数据集、跨架构迁移中的泛化能力仍显不足。其二,在构建过程中,如何确保不同检索系统(GRAM与VAST)所产生预测分数的可比性与一致性,如何划分具有代表性的训练、验证与测试集以规避过拟合,以及如何精准定义Top-100检索结果中的相关性标签,均为构建过程带来了设计与标注层面的显著挑战。
常用场景
经典使用场景
VQPP数据集作为视频检索领域中查询性能预测(Query Performance Prediction, QPP)的标志性基准,其核心用途在于评估文本查询在视频检索系统中的难度预测能力。研究者可借助该数据集,分别对预检索(Pre-retrieval)和后检索(Post-retrieval)阶段的QPP方法进行标准化评测。具体而言,通过在MSR-VTT和VATEX两个广泛采用的视频语料库上,结合GRAM与VAST这两种前沿检索架构,VQPP提供了统一的度量标准——包括倒数排名(RR)和召回率(Recall),从而实现了对查询难度估计方法的公正比较与深入分析。
解决学术问题
在视频检索学术研究中,一个长期存在的挑战是如何准确预判文本查询的检索难度,这直接关系到系统性能优化与用户体验改善。VQPP数据集系统地解决了这一痛点,它首次为视频领域的查询性能预测提供了一个标准化基准,弥补了以往在图像或文本检索中虽有相关研究、但视频领域缺乏评测规范的空白。通过整合多种检索架构与数据集,VQPP推动了QPP方法在视频检索场景下的泛化能力评估,促使学者们更深入地理解查询因素(如歧义性、信息稀缺性)对检索效果的影响,并为设计更鲁棒的检索策略奠定了实证基础。
衍生相关工作
VQPP数据集的发布催生了一系列富有影响力的衍生工作。研究者基于其提供的标准化框架,探索了多种新颖的预检索特征(如查询语义多样性、视频片段匹配度)与后检索特征(如结果列表的排序一致性、视觉内容与查询的相关性分布)对预测性能的影响。同时,该基准也激励了跨模态QPP方法的研发,例如结合视觉语言模型(如CLIP)的嵌入表示来推断查询难度。在更广阔的学术脉络中,VQPP所倡导的评测体系被进一步拓展至零样本视频检索、跨语言查询预测等前沿方向,推动了视频检索领域性能预测研究的逐步成熟与系统化。
以上内容由遇见数据集搜集并总结生成


