MMPR 多模态推理偏好数据集
收藏超神经2024-11-21 更新2024-12-14 收录
下载链接:
https://hyper.ai/cn/datasets/35897
下载链接
链接失效反馈官方服务:
资源简介:
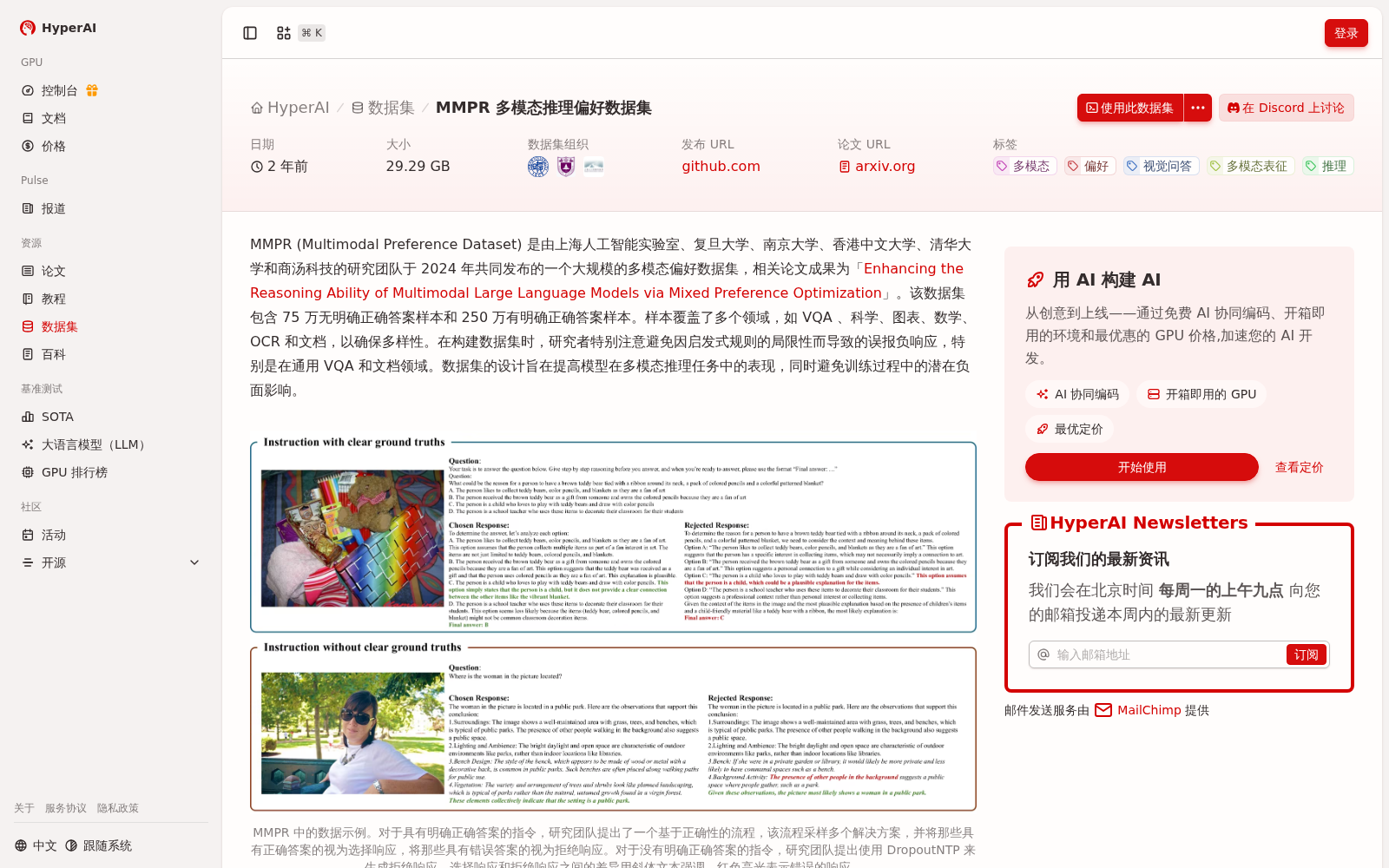
MMPR (Multimodal Preference Dataset) 是由上海人工智能实验室、复旦大学、南京大学、香港中文大学、清华大学和商汤科技的研究团队于 2024 年共同发布的一个大规模的多模态偏好数据集,相关论文成果为「Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization」。该数据集包含 75 万无明确正确答案样本和 250 万有明确正确答案样本。样本覆盖了多个领域,如 VQA 、科学、图表、数学、 OCR 和文档,以确保多样性。在构建数据集时,研究者特别注意避免因启发式规则的局限性而导致的误报负响应,特别是在通用 VQA 和文档领域。数据集的设计旨在提高模型在多模态推理任务中的表现,同时避免训练过程中的潜在负面影响。
MMPR (Multimodal Preference Dataset) is a large-scale multimodal preference dataset jointly released in 2024 by research teams from Shanghai AI Laboratory, Fudan University, Nanjing University, The Chinese University of Hong Kong, Tsinghua University and SenseTime. The associated research paper is titled "Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization". This dataset contains 750,000 samples without explicitly correct answers and 2.5 million samples with explicitly correct answers. The samples cover multiple domains including VQA, science, charts, mathematics, OCR and documents to ensure diversity. When constructing the dataset, the researchers paid special attention to avoiding false negative responses caused by the limitations of heuristic rules, especially in the general VQA and document domains. The dataset is designed to improve the performance of models on multimodal reasoning tasks while avoiding potential negative impacts during training.
创建时间:
2024-11-18
搜集汇总
数据集介绍
背景与挑战
背景概述
MMPR多模态推理偏好数据集由上海人工智能实验室等多家机构于2024年联合发布,旨在通过混合偏好优化增强多模态大语言模型的推理能力。该数据集包含75万无明确正确答案样本和250万有明确正确答案样本,覆盖VQA、科学、图表等多个领域,并在构建时注重避免误报负响应,以提升模型训练效果。
以上内容由遇见数据集搜集并总结生成


