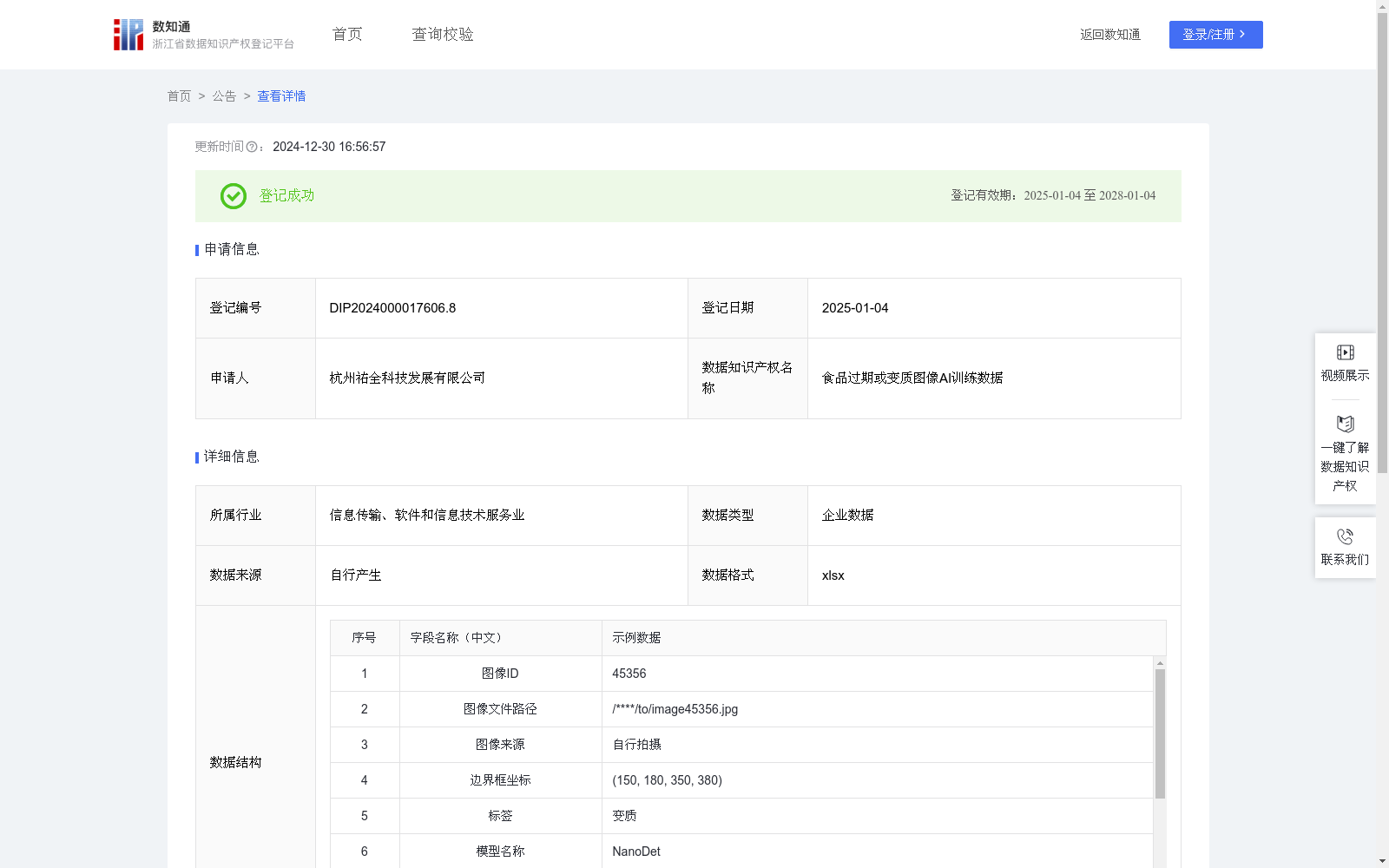
食品过期或变质图像AI训练数据
收藏浙江省数据知识产权登记平台2024-12-30 更新2024-12-31 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/109421
下载链接
链接失效反馈官方服务:
资源简介:
本数据的价值在于其为构建精准、高效的食品过期或变质识别AI模型提供了丰富且具针对性的信息基础。这些数据覆盖了食品在过期或变质过程中的关键特征,包括颜色变化、形态异常、霉斑生长等,使AI模型能够深入学习并掌握这些因素对食品安全的影响。通过利用这些数据进行训练,AI模型能够更加准确地识别出食品是否过期或变质,进而在实际应用中提供更加自动化和客观的食品质量监测。这一训练过程的核心价值在于提升AI模型的识别精确度和适应能力,确保其在面对现实食品储存和销售环境中的复杂多变情况时,能够做出更加符合食品安全管理需求的决策。1.数据采集:原始图像数据来源于自行拍摄或算法生成,确保数据来源多样化和合法性,并对原始图像的ID、文件路径进行记录。
2.数据预处理与标注:根据自身项目需求和模型要求,将食品过期或变质图像数据分类成训练集和测试集,并对训练集进行标注,形成边界框坐标及对应的标签。
3.模型选择与初始化:选择NanoDet预训练模型,并初始化模型参数,设置合理的超参数,如学习率、批量大小、冗余度等,以优化模型的训练过程。
4.模型训练:使用TensorFlow深度学习框架加载和初始化模型,然后将准备好的训练集输入到模型中进行训练。在训练过程中,模型会不断调整权重,以最小化预测框与真实框之间的差值,从而提高检测的准确性,训练通常需要多个epoch(迭代次数)。
5.模型评估:在训练完成后,使用测试集对模型进行评估。计算模型在不同场景下的精度、召回率、F1分数等性能指标,确保模型的准确性和鲁棒性。
6.模型部署与实时性能评估:将最终训练、测试后得到的模型应用到具体的项目中。在实际应用中,评估模型的实时性能(即准确率),确保满足项目需求。
The core value of this dataset is that it provides a rich and targeted information basis for constructing accurate and efficient AI models for identifying expired or spoiled food. This dataset covers the key characteristics of food during the expiration or spoilage process, including color changes, morphological abnormalities, mold growth, etc., enabling AI models to deeply learn and understand the impact of these factors on food safety. By training on this dataset, AI models can more accurately identify whether food has expired or spoiled, thereby enabling more automated and objective food quality monitoring in practical applications. The core value of this training process lies in improving the recognition accuracy and adaptability of AI models, ensuring that they can make decisions that better meet the requirements of food safety management when facing the complex and variable situations in real-world food storage and sales environments.
1. Data Collection: The original image data is sourced from self-shot photography or algorithmic generation, ensuring the diversity and legality of data sources. The ID and file path of each original image are recorded.
2. Data Preprocessing and Annotation: According to the project requirements and model specifications, the food expiration and spoilage image dataset is divided into a training set and a test set. The training set is annotated to generate bounding box coordinates and corresponding labels.
3. Model Selection and Initialization: The pre-trained NanoDet model is selected, and its parameters are initialized. Reasonable hyperparameters such as learning rate, batch size, and regularization strength are set to optimize the model training process.
4. Model Training: The TensorFlow deep learning framework is used to load and initialize the model, and the prepared training set is input into the model for training. During the training process, the model continuously adjusts its weights to minimize the difference between the predicted bounding boxes and the ground-truth boxes, thereby improving detection accuracy. The training typically requires multiple epochs (iteration rounds).
5. Model Evaluation: After the training is completed, the test set is used to evaluate the model. Performance metrics such as precision, recall, and F1-score under different scenarios are calculated to ensure the model's accuracy and robustness.
6. Model Deployment and Real-time Performance Evaluation: The final trained and tested model is applied to specific projects. In practical applications, the real-time performance (i.e., accuracy) of the model is evaluated to ensure that it meets the project requirements.
提供机构:
杭州祐全科技发展有限公司
创建时间:
2024-11-30
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


