finance-slm-distillation-data
收藏Hugging Face2026-05-11 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/ash0t/finance-slm-distillation-data
下载链接
链接失效反馈官方服务:
资源简介:
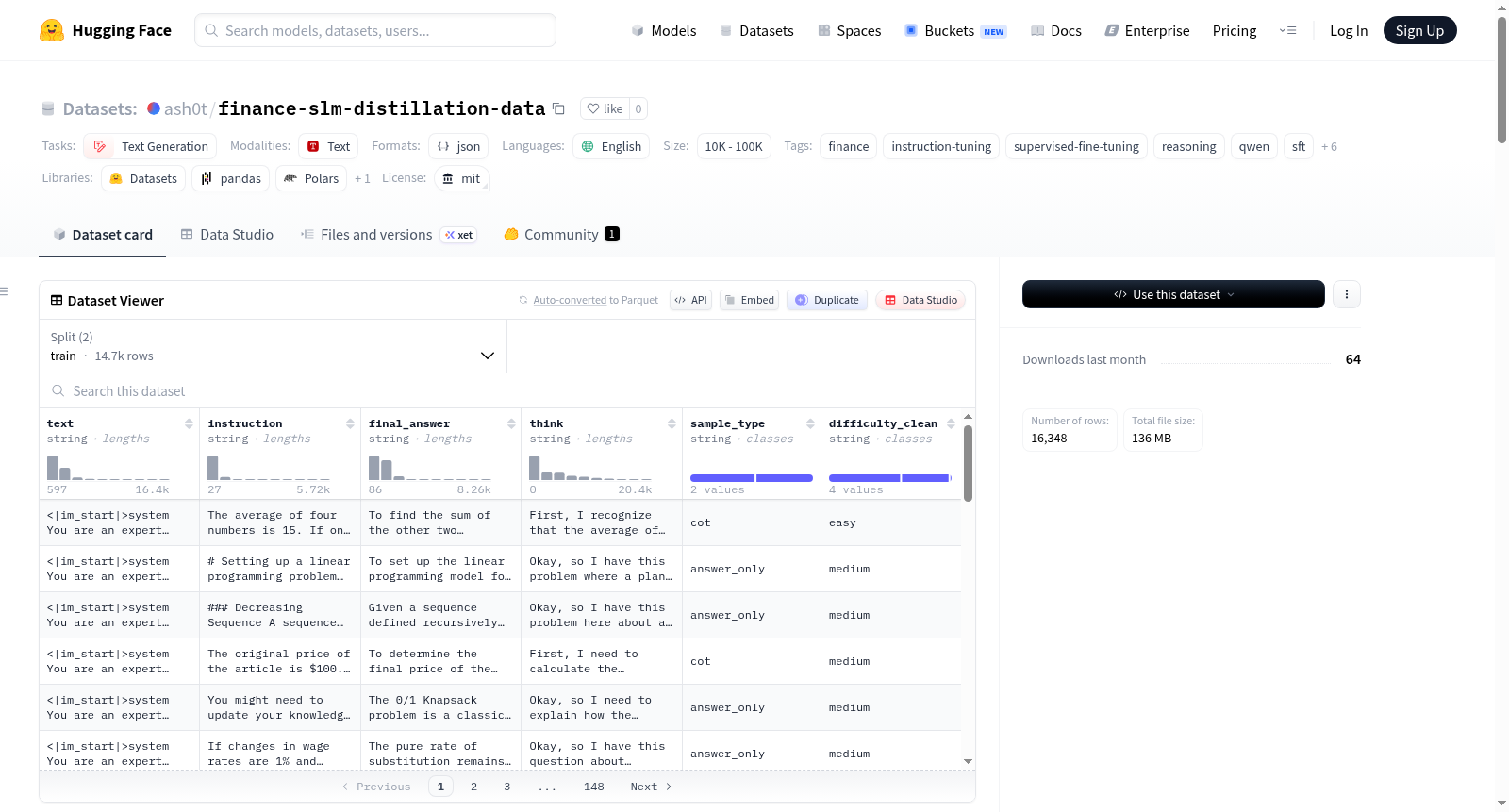
Finance Instruction SFT Dataset是一个用于大型语言模型对话式监督微调的金融导向指令数据集。该数据集源自heladell/Finance_DeepSeek-R1-Distill-dataset,并经过自定义预处理流程,重点关注金融领域过滤、推理质量过滤、答案质量过滤、对话格式化和针对推理评估优化的训练/测试拆分。预处理旨在提升金融领域相关性、定量推理质量、对话一致性、监督微调可用性、推理监督质量和评估推理真实性。数据集保留了简洁的仅答案示例和高质量推理轨迹(当显式推理可靠时),但仅当满足结构、推理密度、冗长度、噪声水平、数学一致性和最终答案可用性等启发式质量约束时才保留推理轨迹,以避免向模型教授噪声或不稳定的推理模式。训练集包含所有已验证的推理样本和剩余的仅答案样本;测试集仅包含仅答案样本,以确保在现实推理条件下评估模型,其中模型仅接收用户问题并必须自主生成推理。数据集采用Qwen兼容的对话格式,每个样本包含系统提示(将助手定位为定量金融、精算科学和金融风险分析专家)、用户输入和助手响应。数据集规模在10K到100K样本之间,语言为英语,适用于文本生成任务,如下游使用QLoRA或标准SFT流程的微调工作流。
Finance Instruction SFT Dataset is a finance-oriented instruction dataset for conversational supervised fine-tuning of large language models. It originates from heladell/Finance_DeepSeek-R1-Distill-dataset and undergoes a custom preprocessing pipeline focusing on financial domain filtering, reasoning quality filtering, answer quality filtering, dialogue formatting, and train/test splits optimized for reasoning evaluation. The preprocessing aims to enhance financial domain relevance, quantitative reasoning quality, dialogue consistency, supervised fine-tuning usability, reasoning supervision quality, and evaluation reasoning authenticity. The dataset retains concise answer-only examples and high-quality reasoning traces (when explicit reasoning is reliable), but only retains reasoning traces if they meet heuristic quality constraints such as structure, reasoning density, verbosity, noise level, mathematical consistency, and final answer availability, to avoid teaching the model noisy or unstable reasoning patterns. The training set includes all verified reasoning samples and remaining answer-only samples; the test set contains only answer-only samples to ensure model evaluation under realistic reasoning conditions, where the model only receives user questions and must generate reasoning autonomously. The dataset adopts a Qwen-compatible dialogue format, with each sample containing a system prompt (positioning the assistant as an expert in quantitative finance, actuarial science, and financial risk analysis), user input, and assistant response. The dataset size ranges from 10K to 100K samples, the language is English, and it is suitable for text generation tasks, such as fine-tuning workflows using QLoRA or standard SFT processes.
创建时间:
2026-05-11
搜集汇总
数据集介绍
构建方式
该数据集的构建源自于`heladell/Finance_DeepSeek-R1-Distill-dataset`,经过一系列精细化的预处理流程得以成型。流程涵盖金融领域关联性过滤、推理质量评估、答案质量筛选、对话格式转换以及面向推理评估的训练/测试集划分优化。特别地,对于包含`<think>`标签的推理痕迹,仅在满足结构完整性、推理密度、数学一致性等启发式质量约束时予以保留,否则将其转换为仅包含答案的样本,以避免模型学习到不稳定的推理模式。最终数据以兼容Qwen聊天模板的格式呈现,便于下游的QLoRA或标准SFT微调流程。
使用方法
使用该数据集时,用户可直接加载`train_sft.jsonl`与`test_sft.jsonl`文件,因其遵循Qwen式对话模板,故可无缝适配基于`transformers`库的聊天模型训练流程。推荐采用QLoRA或标准SFT框架进行微调,训练时需注意模型对系统提示词(如‘你是一位量化金融、精算科学与金融风险分析专家’)的响应。用户亦可通过分析附带的`preprocessing_report.csv`等诊断文件,深入理解数据筛选逻辑,并据此调整自身训练策略。
背景与挑战
背景概述
随着大型语言模型在金融领域的应用日益广泛,构建高质量的金融指令微调数据集成为提升模型专业推理能力的关键。该数据集由研究者在heladell/Finance_DeepSeek-R1-Distill-dataset基础上,通过精心设计的预处理流程进一步优化而来,创建时间聚焦于近期大模型金融对齐研究。数据集主要服务于量化金融、精算科学及金融风险分析等复杂推理场景,旨在通过监督微调增强大语言模型的金融领域对话能力、定量推理能力与思维链生成质量。其发布显著推动了金融大模型在指令遵循与推理真实性方面的研究进展,为相关领域提供了经过严格质量筛选的微调资源。
当前挑战
该数据集所解决的领域核心挑战在于金融场景下大模型推理质量的不稳定性与领域适应性不足。具体包括:1) 金融问题涉及严密的数学逻辑与领域知识,模型易生成表面合理但实际错误的推理链条,因此数据集通过启发式规则过滤低质量思维链,避免模型学习噪声模式;2) 构建过程中需平衡推理样本与纯答案样本的比例,确保模型既能学到显性推理过程,又能在无推理提示的真实推理条件下自主生成高质量回答;3) 训练集与测试集的划分策略存在挑战,测试集仅保留答案样本以模拟真实评估场景,同时需维持难度分布的一致性,这对筛选与分配算法提出了较高要求。
常用场景
经典使用场景
在金融领域大语言模型的微调实践中,该数据集被广泛用于指令微调(SFT)和推理能力增强。其设计精妙之处在于,它从DeepSeek-R1蒸馏数据出发,经过严格的金融领域过滤、推理质量筛选和答案质量校验,最终形成符合Qwen对话模板的结构化语料。研究人员常将其作为金融领域监督微调的核心训练集,尤其是面向定量金融、精算科学和金融风险分析等专业场景。数据集独特的训练/测试拆分策略——测试集仅包含纯答案样本,使得模型在评估时需自主生成推理过程,从而更真实地反映其推理能力。这种设计使其成为金融大模型从基础语言能力向专业推理能力跃迁的重要支撑资源,在ChatGPT风格的多轮对话微调流水线中展现出卓越的实用性。
解决学术问题
该数据集着力攻克了金融领域大语言模型在专业推理能力上的若干核心学术难题。传统通用指令数据集往往缺乏金融场景特有的定量分析和因果推理要求,导致模型在面对复杂金融问题时容易产生肤浅或不准确的回答。通过系统性过滤不可靠的推理痕迹,该数据集有效避免了模型学习到不稳定或噪声化的推理模式。它在保留高质量推理轨迹的同时,将低质量推理样本转化为纯答案示例,从而在数据层面解决了'推理监督信号质量不均'这一关键瓶颈。这一工作为金融领域链式思维(Chain-of-Thought)推理的可控训练提供了范本,推动了从通用语言模型向专业金融推理模型的转型,对提升模型在量化交易、风险评估等任务中的数学一致性和逻辑严谨性具有深远意义。
实际应用
在实际产业应用中,该数据集的价值体现在多个高壁垒的金融业务场景。它被广泛用于训练能够进行专业金融对话的智能助手,例如为投资银行构建的自动化研究分析系统、为保险公司设计的精算咨询机器人,以及为量化基金开发的实时市场解读引擎。这些系统需要模型不仅能理解专业术语,还能执行复杂的数学计算和逻辑推演——例如基于财务报表进行盈利预测、或根据市场数据评估衍生品定价风险。数据集对推理质量的严格把控,确保了部署模型在面对真实客户查询时能够生成可信、可解释的金融建议,从而在合规要求和用户体验之间取得平衡。此外,其与QLoRA等轻量级微调框架的兼容性,使得中小型金融机构也能在有限算力下完成模型适配,加速了AI技术在金融领域的落地。
数据集最近研究
最新研究方向
当前,金融领域的大语言模型研究正聚焦于通过高质量指令微调数据集提升模型的定量推理能力与领域适配性。finance-slm-distillation-data数据集应运而生,它从开源金融推理数据中经过精细的领域筛选、推理质量评估与对话格式化处理,专门针对量化金融、精算科学和风险分析等场景优化。该数据集的前沿性体现在其独特的训练/测试拆分策略——测试集仅保留纯答案样本,以模拟模型在真实推理场景中必须自主生成推理链的挑战。这一设计不仅强化了模型的金融领域常识,更推动了链式思维与QLoRA等轻量微调技术的融合,为构建可靠、可解释的金融智能助手提供了关键数据基础,对量化投资决策辅助和金融合规自动化具有重要影响。
以上内容由遇见数据集搜集并总结生成


