有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
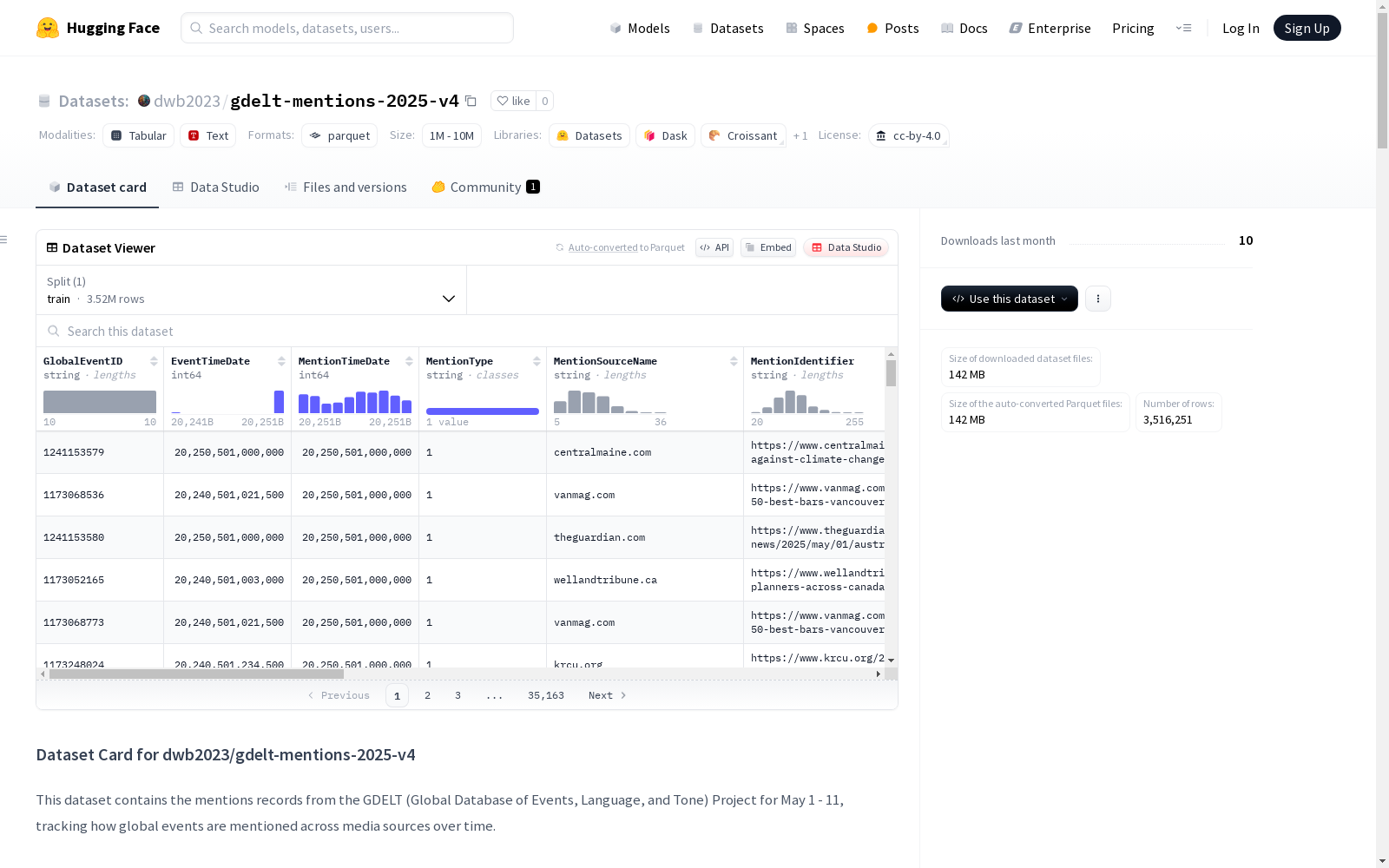
媒体覆盖偏见:
技术限制:
覆盖考虑:
用户应:
最佳实践:
BibTeX: bibtex @inproceedings{leetaru2013gdelt, title={GDELT: Global Data on Events, Language, and Tone, 1979-2012}, author={Leetaru, Kalev and Schrodt, Philip}, booktitle={International Studies Association Annual Conference}, year={2013}, address={San Francisco, CA} }
APA: Leetaru, K., & Schrodt, P. (2013). GDELT: Global Data on Events, Language, and Tone, 1979-2012. Paper presented at the International Studies Association Annual Conference, San Francisco, CA.
dwb2023
Breast Ultrasound Images (BUSI)
小型(约500×500像素)超声图像,适用于良性和恶性病变的分类和分割任务。
github 收录
中国食物成分数据库
食物成分数据比较准确而详细地描述农作物、水产类、畜禽肉类等人类赖以生存的基本食物的品质和营养成分含量。它是一个重要的我国公共卫生数据和营养信息资源,是提供人类基本需求和基本社会保障的先决条件;也是一个国家制定相关法规标准、实施有关营养政策、开展食品贸易和进行营养健康教育的基础,兼具学术、经济、社会等多种价值。 本数据集收录了基于2002年食物成分表的1506条食物的31项营养成分(含胆固醇)数据,657条食物的18种氨基酸数据、441条食物的32种脂肪酸数据、130条食物的碘数据、114条食物的大豆异黄酮数据。
国家人口健康科学数据中心 收录
DALY
DALY数据集包含了全球疾病负担研究(Global Burden of Disease Study)中的伤残调整生命年(Disability-Adjusted Life Years, DALYs)数据。该数据集提供了不同国家和地区在不同年份的DALYs指标,用于衡量因疾病、伤害和早逝导致的健康损失。
ghdx.healthdata.org 收录
UniMed
UniMed是一个大规模、开源的多模态医学数据集,包含超过530万张图像-文本对,涵盖六种不同的医学成像模态:X射线、CT、MRI、超声、病理学和眼底。该数据集通过利用大型语言模型(LLMs)将特定模态的分类数据集转换为图像-文本格式,并结合现有的医学领域的图像-文本数据,以促进可扩展的视觉语言模型(VLM)预训练。
github 收录
OpenPose
OpenPose数据集包含人体姿态估计的相关数据,主要用于训练和评估人体姿态检测算法。数据集包括多视角的图像和视频,标注了人体关键点位置,适用于研究人体姿态识别和动作分析。
github.com 收录