sequelbox/Tachibana4-DeepSeek-V4-Pro-PREVIEW
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/sequelbox/Tachibana4-DeepSeek-V4-Pro-PREVIEW
下载链接
链接失效反馈官方服务:
资源简介:
Tachibana4-PREVIEW是Tachibana 4的早期预览数据集,包含前1.2k行数据。这是一个由DeepSeek-V4-Pro生成的代理编码数据集,专注于现实世界中具有挑战性的编码任务,涵盖多种编程语言和主题。重点领域包括后端和前端开发、系统编程、分布式系统、性能优化、数据结构、数据库和数据工程、游戏和移动开发、安全工程、编译器设计、自定义工具、任务自动化、实用bug修复等。数据集强调多种编程语言,如Python、C、C++、C#、Go、TypeScript、Java、JavaScript、Rust、Haskell、SQL、Shell、R、Ruby、汇编代码等。合成提示使用不同角色、经验水平和沟通风格,以最大化现实世界的灵活性和可用性。响应展示了DeepSeek V4 Pro模型在思考模式下的代理编码能力。此早期预览中的响应未经编辑、过滤或审查,可能存在不准确的答案和无限思考循环等问题。
Tachibana4-PREVIEW is an early sneak preview of Tachibana 4, containing the first 1.2k rows. It is an upcoming agentic coding dataset generated by DeepSeek-V4-Pro, focusing on real-world, challenging agentic coding tasks across a variety of programming languages and topics. Areas of focus include back-end and front-end development, systems programming, distributed systems, performance optimization, data structures, databases and data engineering, game and mobile development, security engineering, compiler design, custom tooling, task automation, practical bugfixes, and more. A wide variety of emphasized languages improves development capability: Python, C, C++, C#, Go, TypeScript, Java, JavaScript, Rust, Haskell, SQL, Shell, R, Ruby, assembly code, and more. Synthetic prompts utilize a variety of personas, experience levels, and styles of communication to maximize real-world flexibility and usability. Responses demonstrate the agentic coding capabilities of DeepSeeks V4 Pro model in thinking mode. Responses in this early preview have not been edited, filtered, or reviewed at all, and potential issues may include inaccurate answers and infinite thought loops.
提供机构:
sequelbox
搜集汇总
数据集介绍
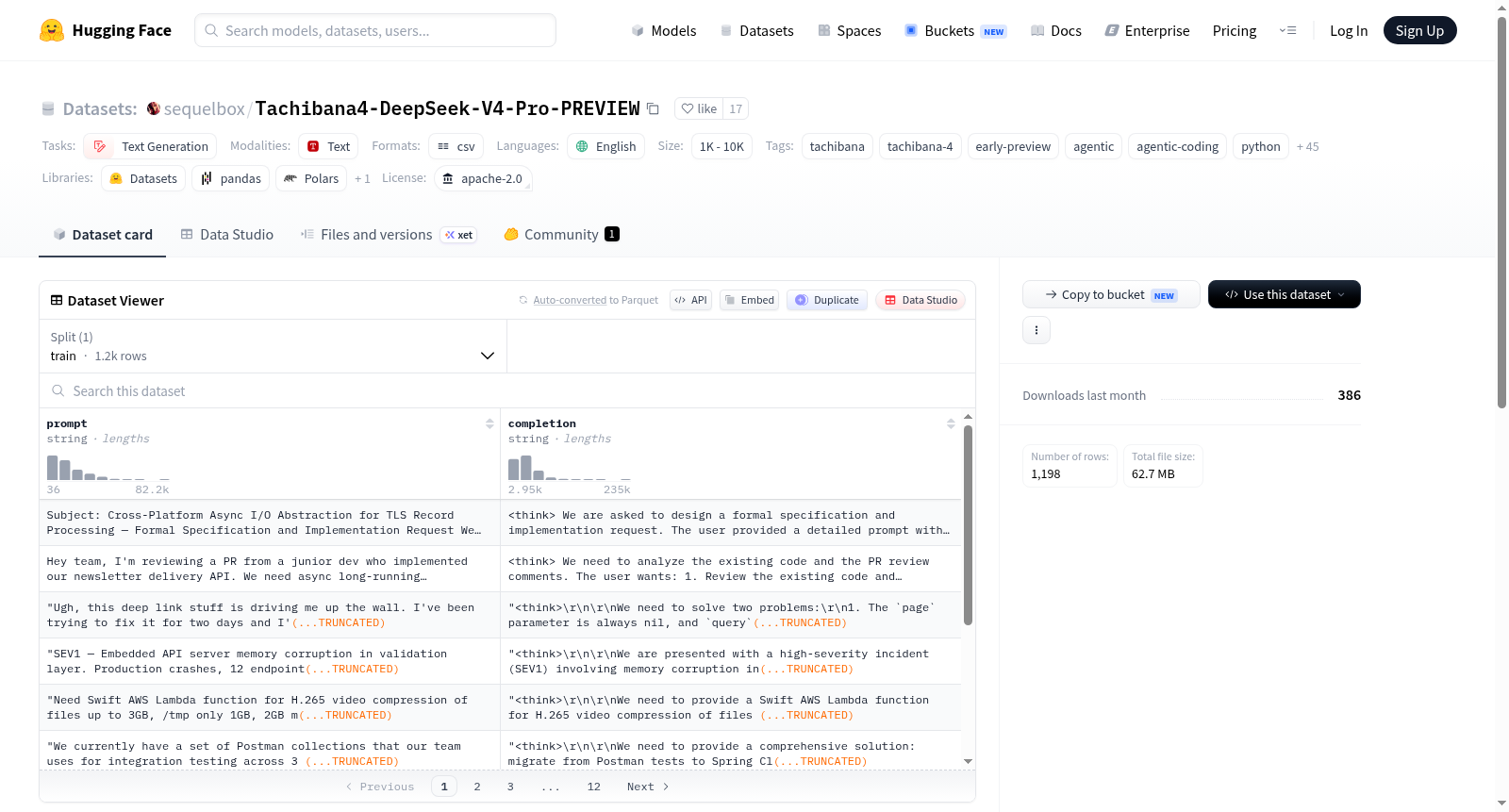
构建方式
Tachibana4-DeepSeek-V4-Pro-PREVIEW 数据集是 Tachibana 4 系列的早期预览版本,源自 DeepSeek-V4-Pro 模型生成的合成数据。其构建过程强调对模型思考模式下智能体编码能力的忠实还原,包含首批 1200 条样本。数据通过模型在真实世界、高挑战性的编程任务中生成,任务涵盖从后端开发、系统编程到编译器设计、安全工程等多个领域,并采用多样化的角色、经验水平和交流风格进行提示设计,以增强模型的灵活性与实用性。该数据集未经任何编辑、筛选或审查,旨在如实呈现 V4 Pro 模型的原始输出。
特点
该数据集的核心特点在于其广泛的编程语言覆盖与任务类型的多样性,涵盖 Python、C、C++、C#、Go、TypeScript、Java、JavaScript、Rust、Haskell 等十余种语言。其聚焦于实际开发场景中的智能体编码任务,包括算法与数据结构、并发编程、API 设计、数据库管理、游戏开发、嵌入式系统及微服务架构等。此外,数据集的提示合成策略融合了不同的角色设定与沟通风格,最大程度地模拟真实世界中的开发需求,从而提升模型在多领域任务中的适应性与推理能力。
使用方法
用户可将该数据集用于训练或微调语言模型,以增强其在智能体编程任务中的表现。鉴于数据集为原始未处理的预览版本,建议使用者在使用前自行进行子集过滤与人工审查,以剔除可能存在的错误答案或无限思考循环等缺陷。数据集适用于文本生成任务,尤其是需要强化模型在多样化编程语言和复杂工程场景下进行推理与问题解决能力的场景。用户应根据自身需求灵活处理,以实现最佳的训练效果。
背景与挑战
背景概述
Tachibana4-DeepSeek-V4-Pro-PREVIEW数据集由SequelBox团队于近期发布,作为Tachibana 4系列的早期预览版本,其核心研究问题聚焦于提升大语言模型在智能体编程(Agentic Coding)任务中的表现。该数据集利用DeepSeek-V4-Pro模型生成,包含约1200行合成样本,覆盖Python、C++、Rust、TypeScript等多种编程语言,以及后端开发、系统编程、分布式系统、性能优化、游戏开发等广泛领域。通过引入多样化角色、经验水平和交流风格的提示,该数据集旨在增强模型在实际场景中的灵活性与实用性,对推动代码生成与智能体系统的研究具有重要意义,为后续的精细调优与评估提供了初步基准。
当前挑战
该数据集面临的核心挑战包括:1)所解决的领域问题——智能体编程任务要求模型具备跨语言、跨领域的复杂问题解决能力,如同时处理后端架构设计、系统级性能调优及并发编程,这对模型的上下文理解、逻辑推理和代码生成一致性提出了极高要求;2)构建过程中的挑战——作为早期预览,数据集的响应未经编辑、筛选或审查,可能存在不准确答案和无限思维循环等质量问题,影响训练稳定性。此外,合成数据的多样性与真实世界场景的匹配度有待验证,用户需自行进行子筛选和人工检查,确保数据集在训练中的可靠性与有效性。
常用场景
经典使用场景
Tachibana4-DeepSeek-V4-Pro-PREVIEW数据集的核心设计锚定于智能体编程(agentic coding)领域,为研究者与开发者提供了一个涵盖多语言、多领域的合成对话样本库。该数据集包含约1200条精心构造的初始样本,专注于真实世界中的高难度编程挑战,覆盖从后端开发、前端工程到系统编程、分布式架构、性能优化、数据库工程、游戏开发、移动端实现以及安全工程等广泛技术范畴。其经典使用方式在于,利用这些包含多角色视角与多样化沟通风格的提示-响应对,来训练和评估大型语言模型在复杂编程任务中的推理与执行能力,尤其是模拟智能体在自主编写代码、调试和重构时的思维过程。
衍生相关工作
该数据集的发布催生了一系列值得关注的衍生研究方向。一方面,基于其原始样本未经过滤编辑的特性,研究者可针对性地开发数据清洗与质量过滤算法,探索如何通过降噪、去重和错误标记修正来提升合成数据训练效果,这直接推动了智能数据蒸馏技术在编程领域的应用。另一方面,其多语言多领域的对话结构引出了对角色扮演与人格一致性保持的探讨,衍生出基于提示工程的分层微调工作,以优化模型在不同经验水平开发者语境下的响应适配性。此外,部分工作聚焦于将数据集中的思维链模式与外部代码执行环境(如沙盒测试)相结合,构建可验证的闭环反馈训练框架,进一步强化模型在真实编译与运行中的错误纠正能力,从而为自主编码智能体的可靠性提供了新的评估基准。
数据集最近研究
最新研究方向
Tachibana4-DeepSeek-V4-Pro-PREVIEW数据集聚焦于前沿的智能体编程(agentic coding)领域,由DeepSeek-V4-Pro模型生成的合成数据构成。该数据集涵盖了Python、C++、Rust、Go等十余种主流编程语言,并涉及后端与前端开发、系统编程、分布式系统、性能优化、数据库工程、游戏与移动开发、安全工程、编译器设计等多元化的真实世界编程任务。其独特之处在于通过模拟不同经验水平与沟通风格的角色人设,生成具有高度现实灵活性的交互指令,旨在提升大型语言模型在复杂编程场景下的自主推理与问题解决能力。作为Tachibana 4系列的早期预览版本,该数据集保留了模型原始输出状态,未经过滤或编辑,为研究智能体模型的编码能力边界、思维链模式及潜在局限提供了宝贵的原始素材,对推动代码生成与自主智能体系统的前沿探索具有重要参考价值。
以上内容由遇见数据集搜集并总结生成


