K-LLaVA-W
收藏Hugging Face2024-11-28 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/NCSOFT/K-LLaVA-W
下载链接
链接失效反馈官方服务:
资源简介:
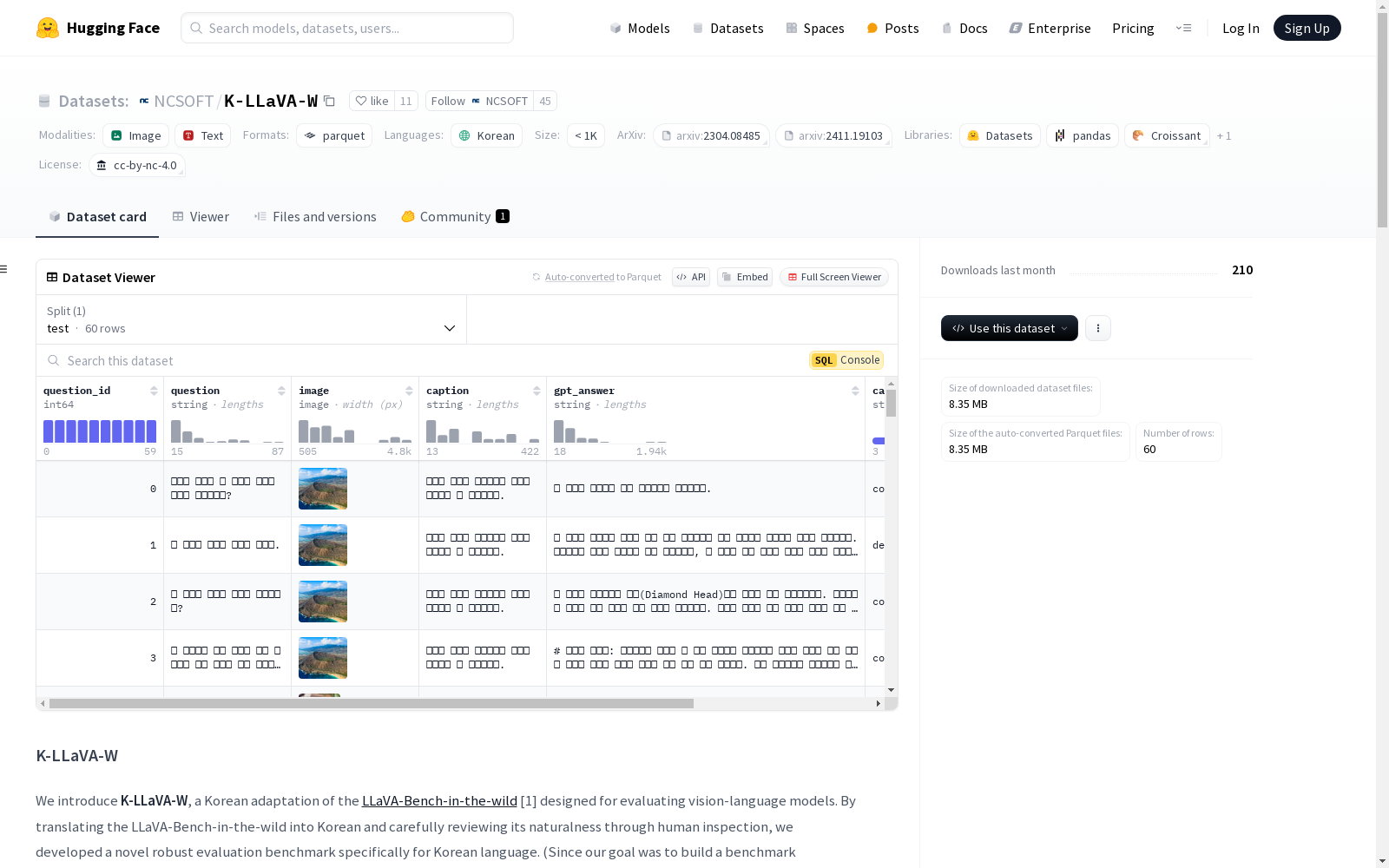
K-LLaVA-W 是一个针对视觉-语言模型的评估基准,专门为韩语设计。它是基于 LLaVA-Bench-in-the-wild 的韩语改编版本,包含24张不同领域的图像和60个日常生活问题,用于全面评估模型在韩语环境下的表现。数据集通过将原始的英语文本翻译成韩语,并经过人工审查以确保自然性,从而实现了本地化。
创建时间:
2024-11-26
原始信息汇总
K-LLaVA-W
概述
- 语言: 韩语 (ko)
- 许可: CC BY-NC 4.0
- 目标: 评估视觉-语言模型的性能
- 数据集类型: 视觉-语言评估基准
- 数据集内容:
- 包含24张来自不同领域的图像
- 包含60个日常生活中的问题
数据集特点
- 翻译与本地化: 将LLaVA-Bench-in-the-wild数据集翻译成韩语,并对图像中的文本进行本地化处理。
- 人工审查: 通过人工检查确保韩语的自然性和准确性。
评估方法
- 评估提示: 提供图像、问题、模型回答等信息,评估模型的回答在实用性、相关性、准确性、详细程度和韩语生成能力等方面的表现。
- 评分标准: 根据实用性、相关性、准确性、详细程度和韩语生成能力五个维度进行评分,每个维度评分范围为1到10。
结果
- VARCO-VISION-14B: 在K-LLaVA-W上的得分为84.74。
参考文献
- [1] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024.
搜集汇总
数据集介绍
构建方式
K-LLaVA-W数据集的构建基于LLaVA-Bench-in-the-wild的韩语适配版本,旨在评估视觉-语言模型在韩语环境下的表现。通过对原始数据集进行韩语翻译,并经过人工审核确保其自然性,研究人员开发了这一专门针对韩语的评估基准。数据集中包含24张涵盖多个领域的图像以及60个日常生活问题,确保了模型在韩语环境下的全面评估。
特点
K-LLaVA-W数据集的特点在于其专注于韩语环境下的视觉-语言模型评估。数据集中的图像和问题均经过韩语本地化处理,确保了语言的自然性和文化相关性。此外,数据集提供了丰富的元数据,包括问题ID、问题描述、图像、图像描述、GPT生成的答案以及类别信息,为模型评估提供了多维度的参考。
使用方法
K-LLaVA-W数据集的使用方法主要包括推理和评估两个阶段。在推理阶段,用户通过输入图像和问题,获取模型的回答。在评估阶段,用户需根据提供的图像描述、问题、GPT生成的答案以及目标模型的回答,按照‘有用性’、‘相关性’、‘准确性’、‘详细程度’和‘韩语生成能力’五个标准进行评分。评估结果以分数形式呈现,并附有详细的评分解释,确保评估的客观性和一致性。
背景与挑战
背景概述
K-LLaVA-W数据集是韩国语言环境下视觉-语言模型评估的重要基准,由NCSOFT的研究团队于2024年推出。该数据集基于LLaVA-Bench-in-the-wild的框架,经过韩语翻译和本地化处理,旨在为韩语视觉-语言模型提供更为精准的评估工具。K-LLaVA-W包含24张涵盖多个领域的图像和60个日常生活问题,能够全面评估模型在韩语环境下的表现。该数据集的推出不仅填补了韩语视觉-语言模型评估领域的空白,还为相关研究提供了重要的数据支持。
当前挑战
K-LLaVA-W数据集在构建和应用过程中面临多重挑战。首先,韩语的语言结构和表达方式与英语存在显著差异,如何在翻译过程中保持问题的自然性和准确性是一个关键问题。其次,图像中的文本需要从英语转换为韩语,以确保本地化的完整性,这对图像处理和文本识别技术提出了较高要求。此外,评估视觉-语言模型时,如何设计合理的评价标准以全面衡量模型在韩语环境下的表现,也是一个亟待解决的难题。这些挑战不仅影响了数据集的构建过程,也对后续模型评估的准确性和可靠性提出了更高的要求。
常用场景
经典使用场景
K-LLaVA-W数据集主要用于评估韩语视觉-语言模型的性能。该数据集通过将LLaVA-Bench-in-the-wild翻译为韩语,并经过人工审查确保其自然性,提供了一个专门针对韩语的评估基准。数据集包含24张不同领域的图像和60个日常生活问题,能够全面评估模型在韩语环境下的表现。
解决学术问题
K-LLaVA-W数据集解决了韩语视觉-语言模型评估中的语言适应性问题。通过提供韩语翻译和本地化的图像文本,该数据集为研究人员提供了一个可靠的基准,用于测试和比较不同模型在韩语环境下的性能。这不仅推动了韩语视觉-语言模型的发展,还为多语言模型的评估提供了新的视角。
衍生相关工作
K-LLaVA-W数据集的推出,催生了一系列针对韩语视觉-语言模型的研究工作。例如,VARCO-VISION技术报告详细介绍了基于该数据集的模型开发与评估过程。此外,该数据集还为其他多语言视觉-语言模型的研究提供了参考,推动了视觉-语言模型在多语言环境下的应用与发展。
以上内容由遇见数据集搜集并总结生成


