BSHG/ShapeAdaptiveImageTextDataset
收藏Hugging Face2024-07-15 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/BSHG/ShapeAdaptiveImageTextDataset
下载链接
链接失效反馈官方服务:
资源简介:
Shape-adaptive Image-Text Dataset是一个官方发布的图像-文本数据集,主要用于相关领域的研究。该数据集完全由合成数据组成,仅供研究使用,且可能包含令人不安的内容。数据集采用CC BY-NC-SA 4.0许可证。
The Shape-adaptive Image-Text Dataset is an official release for research on image and text shape adaptation. The dataset consists entirely of synthesized data and is intended for research purposes. It should be noted that the dataset is uncurated and may contain some disturbing content. Use of the dataset is at the users own risk, and the views and content within the dataset do not reflect those of the authors.
提供机构:
BSHG
原始信息汇总
Shape-adaptive Image-Text Dataset
数据集概述
- 名称: Shape-adaptive Image-Text Dataset
- 官方发布: 是
许可
- 许可协议: CC BY-NC-SA 4.0
- 许可链接: https://creativecommons.org/licenses/by-nc-sa/4.0/
免责声明
- 数据类型: 合成数据
- 使用目的: 仅限研究用途
- 数据规模: 大规模且未经筛选
- 潜在风险: 可能包含令人不适的内容
- 责任声明: 数据内容不代表作者观点
示例用法
-
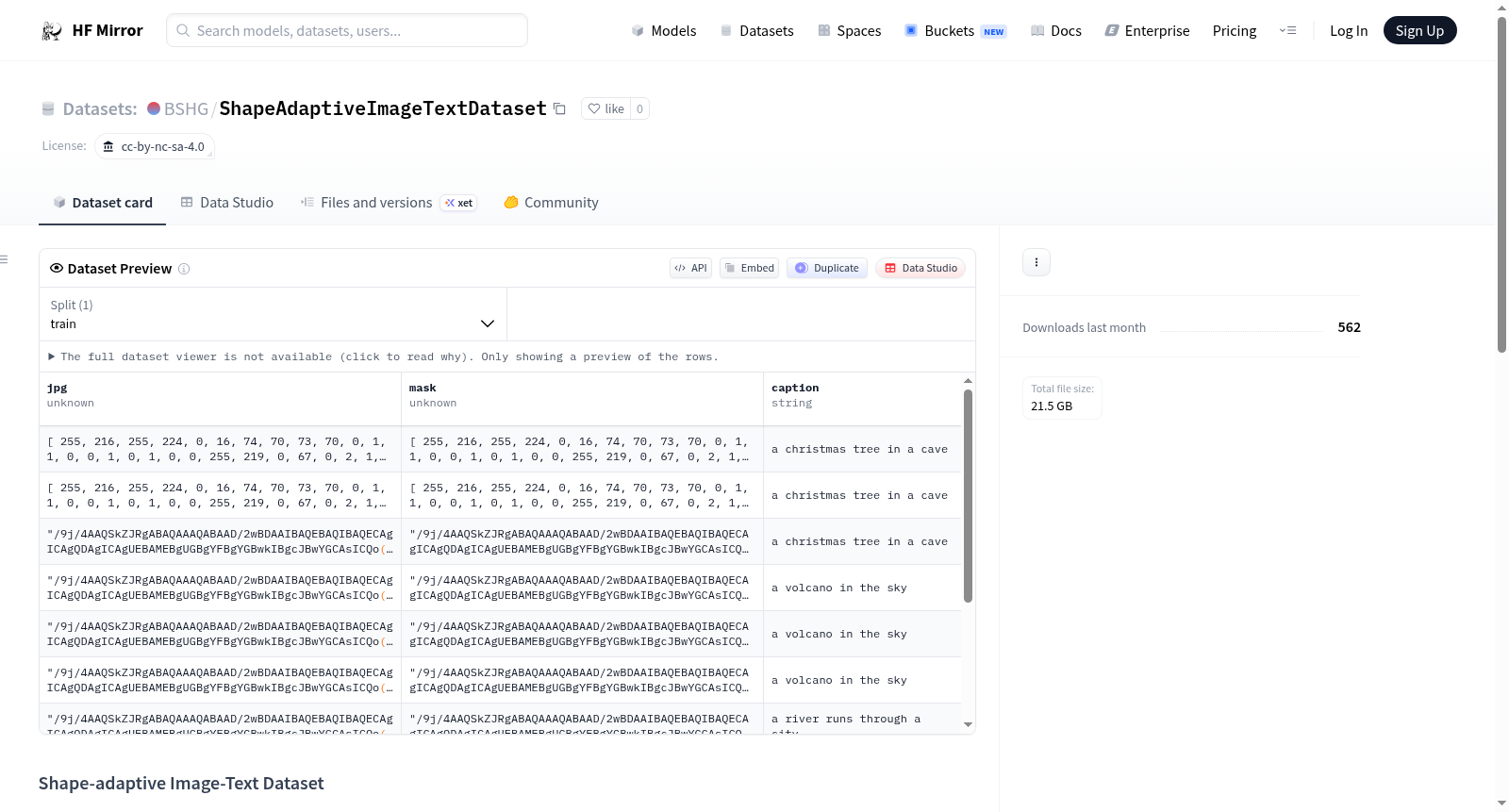
数据格式: Parquet
-
数据字段: jpg, mask, caption
-
示例代码: python import os import json from PIL import Image from io import BytesIO import pyarrow.parquet as pq
with open("./meta.json", "r") as file: meta = json.load(file)
parquet_item = meta[0]
parquet_file_path = os.path.join(".", "data", parquet_item[0]) parquet_file = pq.read_table(parquet_file_path, columns=["jpg", "mask", "caption"]) parquet_slice = parquet_file.slice(parquet_item[1], length=1).to_pydict()
img = Image.open(BytesIO(parquet_slice["jpg"][0])).convert("RGB") mask = Image.open(BytesIO(parquet_slice["mask"][0])).convert("L") caption = parquet_slice[caption][0]
搜集汇总
数据集介绍
构建方式
在计算机视觉与自然语言处理交叉领域,Shape-adaptive Image-Text Dataset的构建体现了对合成数据生成技术的深度应用。该数据集通过系统化的合成流程生成,其核心在于结合图像与对应的文本描述,并特别引入了形状自适应掩码信息。数据以Parquet格式高效存储,每一条记录均包含图像、掩码及文本标注,确保了数据结构的一致性与可扩展性。整个构建过程完全基于合成方法,旨在为相关研究提供大规模、多模态的基础资源。
特点
该数据集最显著的特点在于其完全由合成数据构成,规模庞大且未经人工筛选,这为模型训练带来了丰富的多样性,同时也意味着数据中可能包含非常规内容。数据集遵循CC BY-NC-SA 4.0协议,明确限定于非商业研究用途。其独特之处是提供了与图像对应的形状自适应掩码,这为图像分割、编辑及多模态理解等任务提供了额外的结构化信息,增强了数据在视觉-语言对齐研究中的实用价值。
使用方法
使用该数据集时,研究人员需首先加载元数据文件以获取数据分片信息,随后通过PyArrow库读取Parquet格式的具体数据文件。示例代码展示了如何提取图像、掩码及文本描述,其中图像与掩码需从字节流转换为PIL对象以便进一步处理。由于数据集完全为合成且未经筛选,使用者应意识到其中可能存在的潜在风险,并严格遵循许可协议,仅将数据用于学术研究目的。
背景与挑战
背景概述
在计算机视觉与自然语言处理的交叉领域,图像-文本数据集的构建一直是推动多模态学习发展的核心驱动力。BSHG/ShapeAdaptiveImageTextDataset作为一项新兴资源,由相关研究机构于近期发布,旨在通过合成数据技术探索形状自适应场景下的视觉-语言对齐问题。该数据集聚焦于图像掩码与文本描述之间的细粒度关联,为图像分割、内容生成及跨模态理解等任务提供了新的实验平台,其CC BY-NC-SA 4.0许可协议进一步促进了学术研究的开放协作。
当前挑战
该数据集致力于解决形状自适应图像-文本匹配的复杂问题,其核心挑战在于如何精准建模不规则物体轮廓与语义描述之间的动态对应关系,这对传统刚性对齐方法提出了更高要求。在构建过程中,大规模合成数据的生成与质量控制构成了主要难点,包括掩码标注的几何一致性维护、文本描述的多样性平衡,以及未筛选内容可能引发的伦理风险,这些因素共同增加了数据可靠性与应用安全性的保障难度。
常用场景
经典使用场景
在计算机视觉与自然语言处理的交叉领域,Shape-adaptive Image-Text Dataset为形状自适应图像生成任务提供了关键支持。该数据集通过合成图像与对应文本描述及掩码,典型应用于训练模型学习根据文本提示生成具有特定形状或布局的图像内容,尤其在可控图像合成研究中,它帮助模型理解文本语义与视觉形状之间的复杂映射关系。
衍生相关工作
围绕该数据集,学术界已衍生出多项经典研究工作,主要集中在形状引导的图像生成模型与文本到图像合成技术的改进上。这些工作利用数据集的掩码信息,开发了能够更精准响应形状约束的生成架构,进一步推动了多模态人工智能在艺术创作、虚拟现实及自动化内容生产等前沿领域的应用探索。
数据集最近研究
最新研究方向
在计算机视觉与自然语言处理的交叉领域,Shape-adaptive Image-Text Dataset的推出为图像-文本对齐研究注入了新的活力。该数据集以其独特的形状自适应特性,正推动着多模态模型在图像分割、内容生成及视觉问答等前沿方向的发展。研究者们借助其合成数据与掩码信息,探索跨模态表示学习中的细粒度语义对齐,尤其在可控图像生成和场景理解任务中展现出潜力。随着生成式人工智能的兴起,该数据集在促进模型对复杂视觉结构的适应性方面,为领域内热点如扩散模型与视觉语言大模型的训练提供了重要支撑,对提升多模态系统的鲁棒性与泛化能力具有深远意义。
以上内容由遇见数据集搜集并总结生成


