puzzlevqa
收藏Hugging Face2024-08-07 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/declare-lab/puzzlevqa
下载链接
链接失效反馈官方服务:
资源简介:
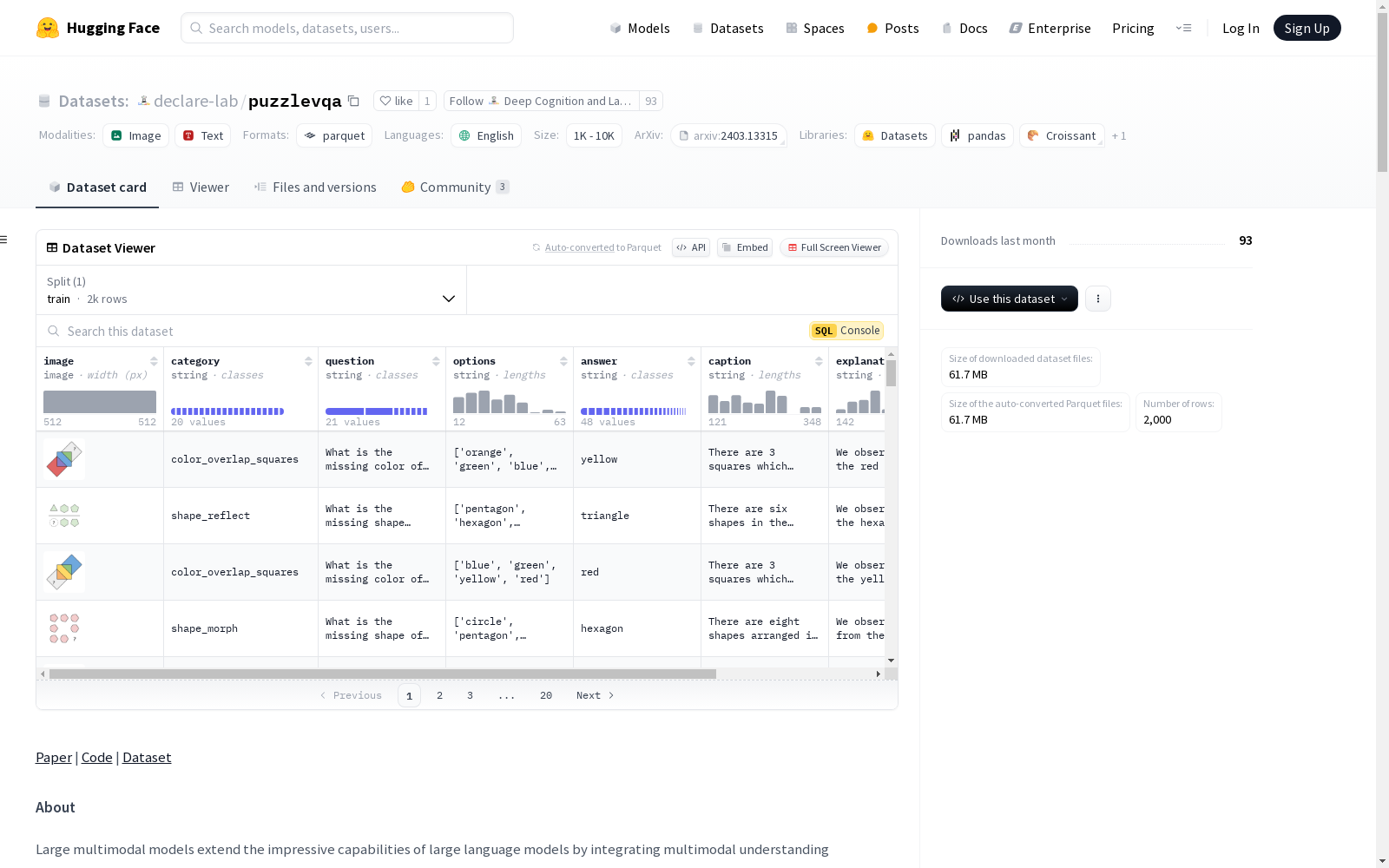
PuzzleVQA数据集是一个包含抽象图案的谜题集合,旨在评估大型多模态模型在基本概念(如颜色、数字、大小和形状)上的抽象图案理解能力。数据集包括图像、类别、问题、选项、答案、描述、解释和推导等特征。通过实验发现,即使是GPT-4V也无法解决超过一半的谜题,主要瓶颈在于较弱的视觉感知和归纳推理能力。数据集通过提供逐步的推理解释来指导模型,以诊断推理挑战。此外,数据集还设计了单概念和双概念谜题,以增强多样性。
创建时间:
2024-08-07
原始信息汇总
PuzzleVQA 数据集概述
数据集信息
特征
- image: 图像数据
- category: 字符串类型,类别
- question: 字符串类型,问题
- options: 字符串类型,选项
- answer: 字符串类型,答案
- caption: 字符串类型,描述
- explanation: 字符串类型,解释
- deduction: 字符串类型,推理
数据分割
- train: 训练集,包含2000个样本,数据大小为64254754.0字节
数据大小
- 下载大小: 61704981字节
- 数据集大小: 64254754.0字节
数据集配置
- default: 默认配置,训练数据路径为
data/train-*
数据集描述
关于
PuzzleVQA 是一个基于抽象模式的谜题集合,用于评估大型多模态模型对基本概念(如颜色、数字、大小和形状)的理解能力。通过实验发现,即使是 GPT-4V 也无法解决超过一半的谜题,主要瓶颈在于较弱的视觉感知和归纳推理能力。
示例谜题
数据集包含涉及颜色概念的示例问题,以及 GPT-4V 的错误答案。解决过程分为三个阶段:视觉感知(蓝色)、归纳推理(绿色)和演绎推理(红色)。
谜题组件
每个谜题实例由多模态模板布局和模式定义,并填充适当的对象以展示底层模式。同时,构建了地面真相推理解释,以解释谜题并说明通用解决方案阶段。
谜题分类
数据集包含基于基本概念(如颜色和大小)的抽象谜题分类,设计了单概念和双概念谜题以增强多样性。
评估结果
评估结果显示,GPT-4V 在单概念和双概念谜题中表现突出,尤其在“数字”类别中表现优异。其他模型如 Claude 3 Opus 和 LLaVA-13B 在特定类别中也有良好表现。
引用
如果该工作对您的研究有启发,请引用:
@article{chia2024puzzlevqa, title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns}, author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria}, journal={arXiv preprint arXiv:2403.13315}, year={2024} }
搜集汇总
数据集介绍
构建方式
PuzzleVQA数据集的构建基于抽象模式的多模态模板设计。首先,研究人员定义了每个谜题的布局和模式,并通过填充适合的对象来展示底层模式。为了增强可解释性,每个谜题实例都配备了真实推理解释,涵盖视觉感知、归纳推理和演绎推理三个阶段。这种构建方式不仅确保了谜题的多样性和复杂性,还为模型提供了明确的推理路径,便于诊断其推理能力的瓶颈。
特点
PuzzleVQA数据集的核心特点在于其专注于抽象模式的评估,涵盖颜色、数字、大小和形状等基础概念。数据集包含单概念和双概念谜题,旨在全面测试多模态模型的推理能力。每个谜题均配有详细的推理解释,帮助研究人员深入分析模型在视觉感知、归纳推理和演绎推理中的表现。此外,数据集的多样性和复杂性使其成为评估和提升多模态模型抽象推理能力的理想工具。
使用方法
PuzzleVQA数据集的使用方法主要包括模型评估和推理能力诊断。研究人员可以通过加载数据集中的图像、问题和推理解释,测试多模态模型在抽象模式上的表现。数据集提供了单概念和双概念谜题的分类,便于针对不同推理能力进行针对性评估。此外,通过分析模型在视觉感知、归纳推理和演绎推理中的表现,研究人员可以识别模型的瓶颈,并设计改进策略。数据集还支持与现有模型的对比实验,为多模态推理研究提供基准。
背景与挑战
背景概述
PuzzleVQA数据集由Yew Ken Chia等研究人员于2024年提出,旨在评估大型多模态模型在抽象模式理解与推理方面的能力。该数据集基于颜色、数字、大小和形状等基础概念,构建了一系列抽象谜题,旨在揭示这些模型在模拟人类一般智能和推理能力方面的局限性。通过实验,研究人员发现即使是先进的GPT-4V模型,也无法解决超过一半的谜题,尤其是在视觉感知和归纳推理方面存在显著瓶颈。PuzzleVQA的提出为多模态模型的研究提供了新的评估标准,并为未来改进这些模型的认知能力指明了方向。
当前挑战
PuzzleVQA数据集的核心挑战在于如何有效评估多模态模型在抽象模式理解与推理方面的能力。首先,抽象模式的多样性和复杂性使得模型在视觉感知和归纳推理方面面临巨大挑战,尤其是在处理颜色、数字、大小和形状等基础概念时,模型的表现远未达到人类水平。其次,数据集的构建过程中,研究人员需要设计具有高度多样性和复杂性的谜题模板,并为其生成详细的推理解释,这对数据标注和验证提出了极高的要求。此外,如何通过系统化的实验分析,揭示模型在推理过程中的具体瓶颈,也是该数据集面临的重要挑战之一。
常用场景
经典使用场景
PuzzleVQA数据集主要用于评估大型多模态模型在抽象模式识别和推理能力上的表现。通过包含颜色、数字、大小和形状等基本概念的谜题,该数据集能够系统地测试模型在视觉感知、归纳推理和演绎推理等方面的能力。研究人员可以利用这些谜题来诊断模型在复杂推理任务中的瓶颈,并探索如何提升模型在抽象模式理解上的表现。
实际应用
在实际应用中,PuzzleVQA数据集可以用于开发和优化多模态模型在教育、游戏设计和智能助手等领域的表现。例如,在教育领域,该数据集可以帮助设计更具挑战性的学习任务,以提升学生的抽象思维能力。在游戏设计中,基于PuzzleVQA的模型可以用于生成更具趣味性和挑战性的谜题,增强用户体验。此外,智能助手也可以通过该数据集提升其在复杂推理任务中的表现,从而更好地服务于用户。
衍生相关工作
PuzzleVQA数据集已经衍生出多项相关研究,尤其是在多模态模型的推理能力评估和改进方面。例如,基于该数据集的研究揭示了GPT-4V在视觉感知和归纳推理上的瓶颈,并提出了逐步引导模型进行推理的方法。此外,该数据集还激发了更多关于如何提升模型在抽象模式理解上的研究,推动了多模态模型在模拟人类认知过程方面的进一步发展。
以上内容由遇见数据集搜集并总结生成


