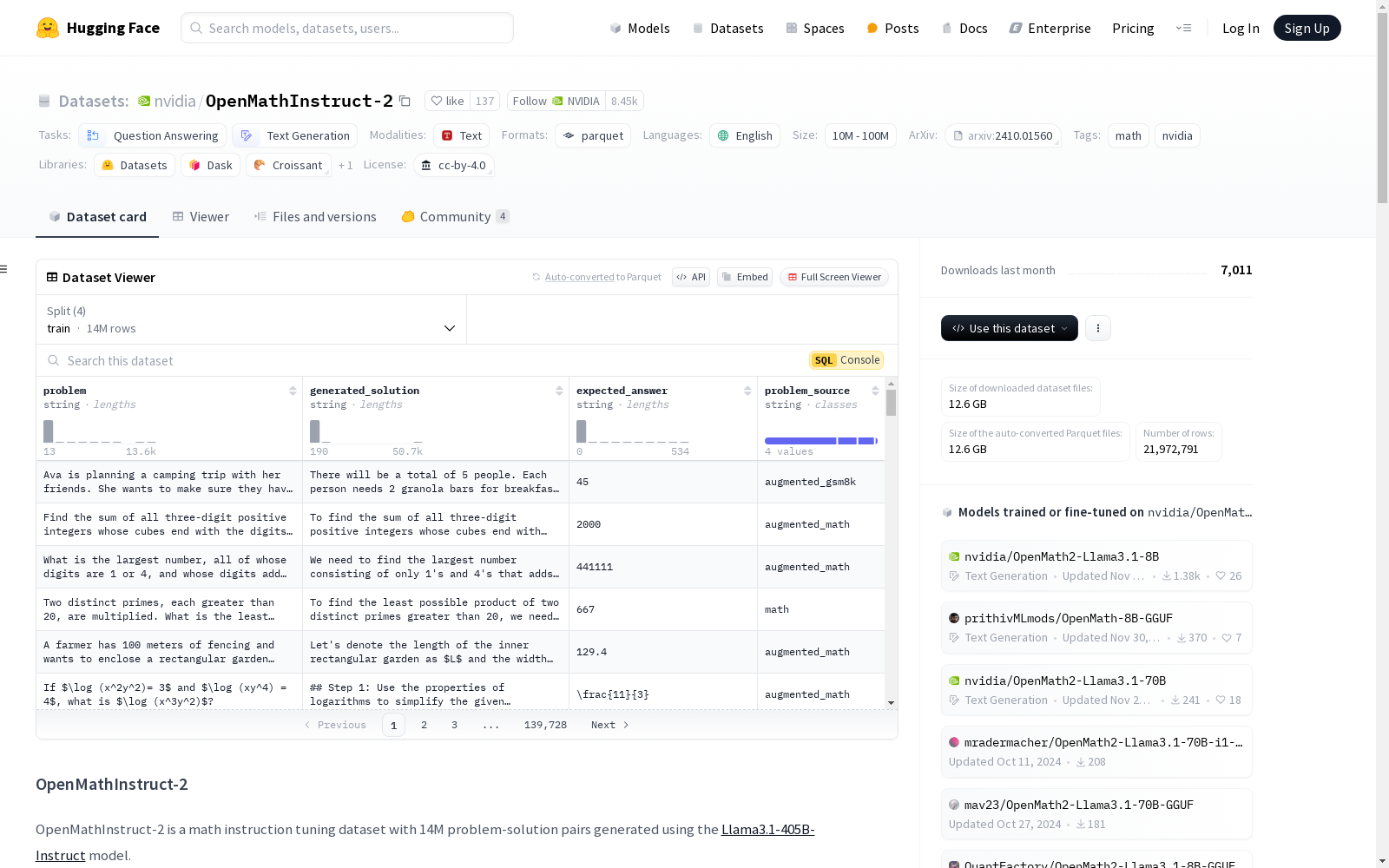
OpenMathInstruct-2
收藏Hugging Face2024-10-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/nvidia/OpenMathInstruct-2
下载链接
链接失效反馈官方服务:
资源简介:
OpenMathInstruct-2是一个数学指令调优数据集,包含1400万个问题-解决方案对。这些数据对是通过使用Llama3.1-405B-Instruct模型生成的。数据集的构建基于GSM8K和MATH训练集的问题,通过解决方案增强和问题-解决方案增强两种方式生成新的问题和解决方案。数据集包含四个主要字段:问题、生成的解决方案、预期答案和问题来源。预期答案对于训练集中的问题是从数据集中提供的真实答案,而对于增强的问题则是通过多数投票得出的答案。数据集还包括一个污染探索器,用于查找与GSM8K、MATH、AMC 2023、AIME 2024和Omni-MATH测试集问题相似的问题。此外,还发布了一系列基于此数据集训练的OpenMath2模型,并提供了代码、模型和数据集的链接,以及如何重现结果的详细说明。
OpenMathInstruct-2 is a mathematical instruction tuning dataset containing 14 million question-solution pairs. These pairs are generated using the Llama3.1-405B-Instruct model. The dataset is constructed based on the questions from the GSM8K and MATH training sets, with new questions and solutions generated via two approaches: solution augmentation and question-solution augmentation. It includes four core fields: question, generated solution, expected answer, and question source. For questions from the original training sets, the expected answer is the ground-truth answer provided in the source dataset, while for augmented questions, the expected answer is derived via majority voting. The dataset also features a contamination explorer designed to identify questions similar to those in the GSM8K, MATH, AMC 2023, AIME 2024, and Omni-MATH test sets. Additionally, a series of OpenMath2 models trained on this dataset have been released, along with links to the code, models, and dataset, as well as detailed instructions on how to reproduce the experimental results.
提供机构:
NVIDIA
创建时间:
2024-09-29
原始信息汇总
OpenMathInstruct-2 数据集概述
基本信息
- 数据集名称: OpenMathInstruct-2
- 许可证: CC BY 4.0
- 语言: 英语 (en)
- 标签: 数学 (math), NVIDIA
- 大小类别: 10M < n < 100M
- 任务类别: 问答 (question-answering), 文本生成 (text-generation)
数据集结构
- 特征:
- problem: 字符串类型,原始问题或增强问题。
- generated_solution: 字符串类型,合成生成的解决方案。
- expected_answer: 字符串类型,原始问题的真实答案或增强问题的多数投票答案。
- problem_source: 字符串类型,问题来源(GSM8K、MATH或增强版本)。
数据生成
- 生成方式:
- Solution augmentation: 为GSM8K和MATH训练集中的问题生成链式思维解决方案。
- Problem-Solution augmentation: 生成新问题,并为其生成解决方案。
数据集内容
- 问题来源:
- 直接来自GSM8K或MATH训练集的问题。
- 从GSM8K或MATH训练集增强生成的新问题。
附加资源
- 污染探索器: 用于查看OpenMathInstruct-2数据集中与GSM8K、MATH、AMC 2023、AIME 2024和Omni-MATH测试集问题相似的问题。
- 相关论文: 详细信息参见 arXiv:2410.01560。
模型表现
- 模型:
- Llama3.1-8B-Instruct
- OpenMath2-Llama3.1-8B
- Llama3.1-70B-Instruct
- OpenMath2-Llama3.1-70B
- 性能:
- 在GSM8K、MATH、AMC 2023、AIME 2024和Omni-MATH测试集上的表现。
开源资源
- 代码: NeMo-Skills
- 模型: NVIDIA OpenMath 2 模型集合
- 数据集: OpenMathInstruct-2
引用
bibtex @article{toshniwal2024openmath2, title = {OpenMathInstruct-2: Accelerating AI for Math with Massive Open-Source Instruction Data}, author = {Shubham Toshniwal and Wei Du and Ivan Moshkov and Branislav Kisacanin and Alexan Ayrapetyan and Igor Gitman}, year = {2024}, journal = {arXiv preprint arXiv:2410.01560} }
搜集汇总
数据集介绍
构建方式
OpenMathInstruct-2数据集的构建基于GSM8K和MATH训练集中的数学问题,通过Llama3.1-405B-Instruct模型生成问题与解答对。该过程包括两个主要步骤:一是对GSM8K和MATH中的问题进行解答增强,生成链式思维解答;二是通过生成新的问题并为其提供解答,实现问题与解答的双重增强。这种构建方式不仅丰富了数据集的内容,还提高了数据的多样性和复杂性。
特点
OpenMathInstruct-2数据集包含14M个问题与解答对,涵盖了从基础到高级的数学问题。每个数据点包括原始问题、生成的解答、预期答案以及问题来源。特别地,对于增强生成的问题,预期答案采用多数投票的方式确定,确保了答案的可靠性。此外,数据集提供了1M、2M和5M的公平下采样版本,便于不同规模的研究需求。
使用方法
使用OpenMathInstruct-2数据集时,可以通过Hugging Face的datasets库直接加载特定规模的数据子集,如1M、2M或5M。对于需要完整数据集的用户,提供了将数据集转换为jsonl格式的代码示例,便于进一步处理和分析。此外,数据集的使用还支持通过提供的污染探索器工具,检查与多个数学测试集问题的相似性,确保研究的严谨性。
背景与挑战
背景概述
OpenMathInstruct-2数据集是由NVIDIA团队于2024年发布的一个数学指令调优数据集,旨在通过大规模的开源指令数据加速人工智能在数学领域的应用。该数据集包含了1400万条问题-解答对,基于Llama3.1-405B-Instruct模型生成,并结合了GSM8K和MATH数据集的训练集问题。通过解决方案增强和问题-解答增强两种方式,数据集不仅扩展了现有问题的解答路径,还生成了全新的数学问题及其解答。这一数据集的发布为数学推理模型的训练提供了丰富的资源,推动了数学领域人工智能研究的进展。
当前挑战
OpenMathInstruct-2数据集在构建和应用过程中面临多重挑战。首先,数学问题的多样性和复杂性要求生成的解答必须具有高度的逻辑性和准确性,这对模型的推理能力提出了极高的要求。其次,数据集的构建依赖于大规模的问题生成和解答验证,如何确保生成的问题和解答的质量与多样性是一个技术难题。此外,数据集中存在少量超长问题(超过1024个Llama token),虽然占比极低,但可能影响模型的训练效率和内存占用。尽管这些问题可以通过过滤解决,但仍需在数据预处理阶段进行额外处理。最后,如何有效利用该数据集提升模型在多个数学基准测试(如GSM8K、MATH等)上的表现,也是研究人员需要深入探索的方向。
常用场景
经典使用场景
OpenMathInstruct-2数据集在数学问题求解领域具有广泛的应用,尤其是在数学推理和问题生成任务中。该数据集通过结合GSM8K和MATH训练集的问题,生成了大量的数学问题及其解决方案,特别适用于训练和评估大型语言模型在数学推理任务中的表现。研究人员可以利用该数据集进行模型微调,提升模型在复杂数学问题上的推理能力。
解决学术问题
OpenMathInstruct-2数据集解决了数学推理任务中数据稀缺和多样性不足的问题。通过生成大量的问题-解决方案对,该数据集为研究人员提供了丰富的训练资源,使得模型能够在更广泛的数学问题上进行训练和测试。这不仅提升了模型在数学推理任务中的泛化能力,还为数学教育领域的自动化评估和辅助教学提供了有力支持。
衍生相关工作
基于OpenMathInstruct-2数据集,研究人员已经开发了一系列OpenMath2模型,这些模型在GSM8K、MATH等数学基准测试中表现出色。此外,该数据集还推动了数学推理领域的开源工具和模型的开发,如NeMo-Skills项目,进一步促进了数学推理任务的自动化和智能化研究。
以上内容由遇见数据集搜集并总结生成


