gemini-flash-2.0-speech
收藏Hugging Face2025-01-22 更新2025-01-23 收录
下载链接:
https://huggingface.co/datasets/shb777/gemini-flash-2.0-speech
下载链接
链接失效反馈官方服务:
资源简介:
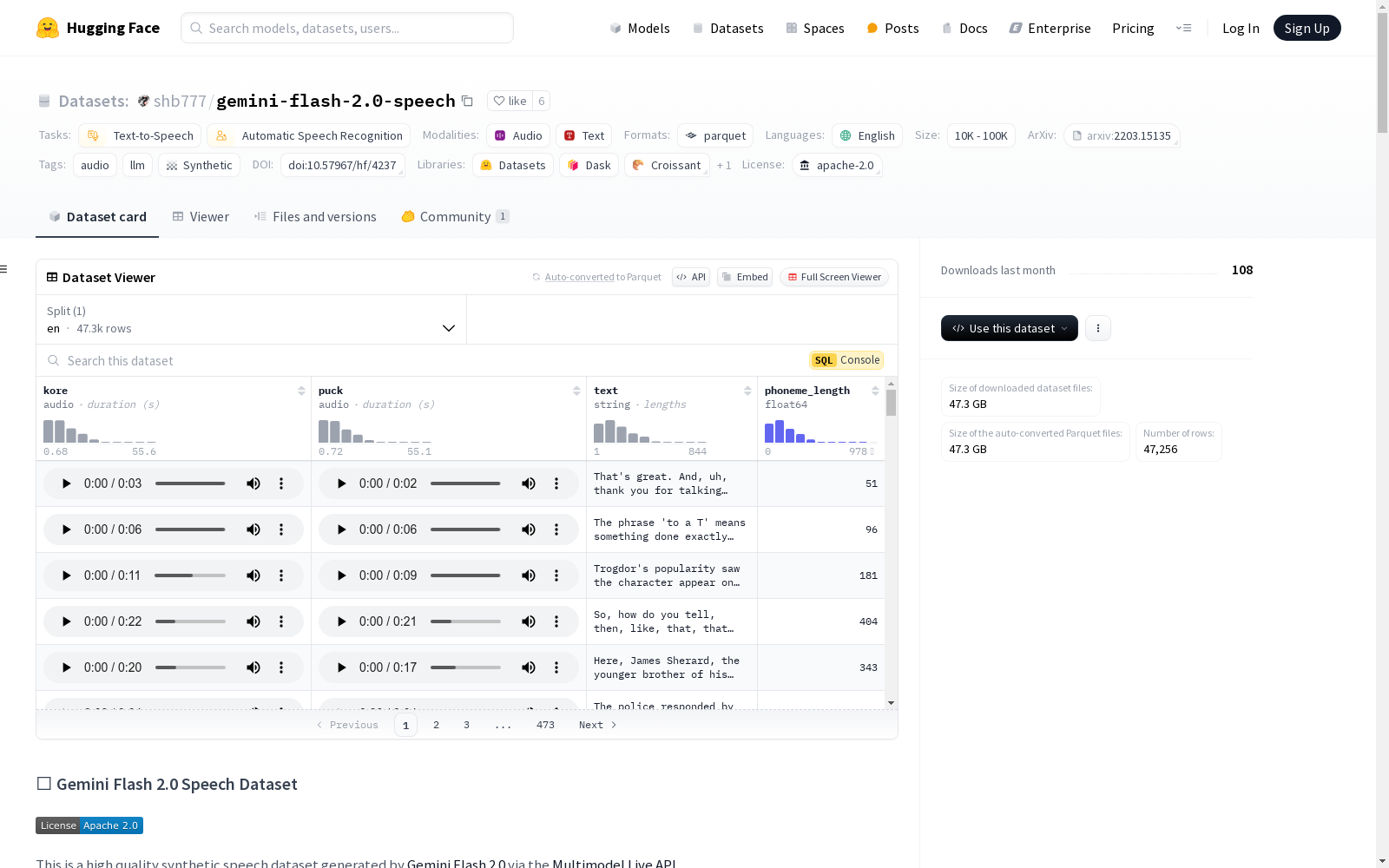
Gemini Flash 2.0 Speech数据集是一个高质量的合成语音数据集,由Gemini Flash 2.0模型通过Multimodel Live API生成。该数据集包含两位说话者(Puck和Kore)的英语语音数据,总计47,256个音频文件,总时长为1023527.20秒(约284.31小时)。数据集的文本内容多样,包括数字、LLM生成的句子、维基百科文章、播客、论文、技术和金融新闻以及Reddit帖子。数据集主要用于训练和实验STT/TTS模型。
The Gemini Flash 2.0 Speech Dataset is a high-quality synthetic speech dataset generated by the Gemini Flash 2.0 model via the Multimodal Live API. This dataset contains English speech data from two speakers, Puck and Kore, with a total of 47,256 audio files and a total duration of 1,023,527.20 seconds (approximately 284.31 hours). The dataset includes diverse text content, including numbers, sentences generated by LLMs, Wikipedia articles, podcasts, academic papers, technical and financial news, and Reddit posts. It is primarily used for training and experimenting with STT/TTS models.
创建时间:
2025-01-16
搜集汇总
数据集介绍
构建方式
Gemini Flash 2.0 Speech数据集是通过Google的Gemini Flash 2.0模型结合Multimodel Live API生成的高质量合成语音数据集。该数据集包含两位说话者(Puck和Kore)的英语语音,涵盖了多种文本来源,如维基百科文章、播客、技术新闻和Reddit帖子等。语音数据经过Misaki工具进行音素化处理,部分条目可能包含空值。
特点
该数据集的特点在于其多样化的文本来源和高质量的语音合成。数据集包含47,256个音频文件,总时长达284.31小时,平均每个音频文件时长为10.83秒。文本内容涵盖了数字、LLM生成的句子、维基百科文章、播客、论文、技术新闻和Reddit帖子等多种类型,确保了数据的广泛性和代表性。
使用方法
Gemini Flash 2.0 Speech数据集主要用于训练和测试语音识别(STT)和文本转语音(TTS)模型。用户可以通过Hugging Face平台下载数据集,并利用其丰富的语音和文本数据进行模型训练。数据集中的每个条目包含两位说话者的音频文件、对应的文本内容以及音素长度信息,便于用户进行多方面的实验和分析。
背景与挑战
背景概述
Gemini Flash 2.0 Speech数据集是由Google的Gemini Flash 2.0模型通过Multimodel Live API生成的高质量合成语音数据集,创建于2025年。该数据集包含两位说话者(Puck和Kore)的英语语音,涵盖了多种文本来源,如维基百科文章、播客、技术新闻等。其主要研究问题在于提升文本到语音(TTS)和自动语音识别(ASR)模型的性能,特别是在多源文本输入下的语音生成与识别能力。该数据集在语音合成领域具有重要影响力,为研究人员提供了丰富的实验数据,推动了语音技术的进一步发展。
当前挑战
Gemini Flash 2.0 Speech数据集在构建和应用过程中面临多重挑战。首先,语音合成的自然度和流畅性要求极高,尤其是在处理多源文本时,如何保持语音的一致性和自然感是一个技术难点。其次,数据集中部分音素长度信息缺失,可能影响模型的训练效果。此外,数据集的多样性和复杂性对模型的泛化能力提出了更高要求,如何在保证数据质量的同时提升模型的鲁棒性,是研究人员需要解决的关键问题。最后,数据集的规模较大,对计算资源和存储空间的需求较高,这也为实际应用带来了挑战。
常用场景
经典使用场景
Gemini Flash 2.0 Speech数据集在语音合成(TTS)和自动语音识别(ASR)领域具有广泛的应用。该数据集通过高质量的合成语音,涵盖了多种文本类型,包括维基百科文章、播客、技术新闻和Reddit帖子等,为研究人员提供了丰富的语音数据资源。其经典使用场景包括训练和评估TTS模型,生成自然流畅的语音输出,以及优化ASR系统,提升语音识别的准确性和鲁棒性。
解决学术问题
该数据集解决了语音合成和识别领域中的多个关键问题。首先,它提供了多样化的语音样本,涵盖了不同语境和语言风格,有助于提升模型的泛化能力。其次,数据集中的音素长度信息为语音合成模型的训练提供了额外的监督信号,使得生成的语音更加自然。此外,数据集的规模和质量为研究人员提供了可靠的基准,推动了语音技术的前沿研究。
衍生相关工作
该数据集衍生了许多经典研究工作,特别是在多模态语音合成和跨语言语音识别领域。研究人员利用该数据集开发了基于深度学习的TTS模型,如WaveNet和Tacotron的改进版本,进一步提升了语音合成的自然度和表现力。此外,该数据集还被用于训练多语言ASR模型,推动了跨语言语音识别技术的发展,为全球化应用提供了技术支持。
以上内容由遇见数据集搜集并总结生成


