VISTA-400K
收藏github2024-12-05 更新2024-12-06 收录
下载链接:
https://github.com/TIGER-AI-Lab/VISTA
下载链接
链接失效反馈官方服务:
资源简介:
VISTA-400K是一个高质量的视频指令跟随数据集,旨在通过视频时空增强方法生成长时间和高分辨率的视频指令数据,以增强视频语言模型的视频理解能力。
VISTA-400K is a high-quality video instruction-following dataset. It aims to generate long-duration and high-resolution video instruction data through video spatio-temporal enhancement approaches, thereby enhancing the video understanding capabilities of video-language models.
创建时间:
2024-11-29
原始信息汇总
VISTA 数据集概述
数据集简介
VISTA 是一个视频时空增强方法,旨在生成长时间和高分辨率的视频指令跟随数据,以增强视频语言模型(LMMs)的视频理解能力。
数据集特点
- 时空增强:利用图像和视频分类数据增强技术(如 CutMix、MixUp 和 VideoMix),通过空间和时间上的视频组合,生成增强的视频样本。
- 数据合成:基于增强后的视频,合成指令数据,利用现有的公开视频-字幕数据集,确保数据集的开放性和可扩展性。
- VISTA-400K:构建了一个高质量的视频指令跟随数据集,旨在提升视频语言模型对长时间和高分辨率视频的理解能力。
相关资源
- VISTA-400K 数据集:🤗 VISTA-400K
- HRVideoBench 数据集:🤗 HRVideoBench
引用
@misc{ren2024vistaenhancinglongdurationhighresolution, title={VISTA: Enhancing Long-Duration and High-Resolution Video Understanding by Video Spatiotemporal Augmentation}, author={Weiming Ren and Huan Yang and Jie Min and Cong Wei and Wenhu Chen}, year={2024}, eprint={2412.00927}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2412.00927}, }
搜集汇总
数据集介绍
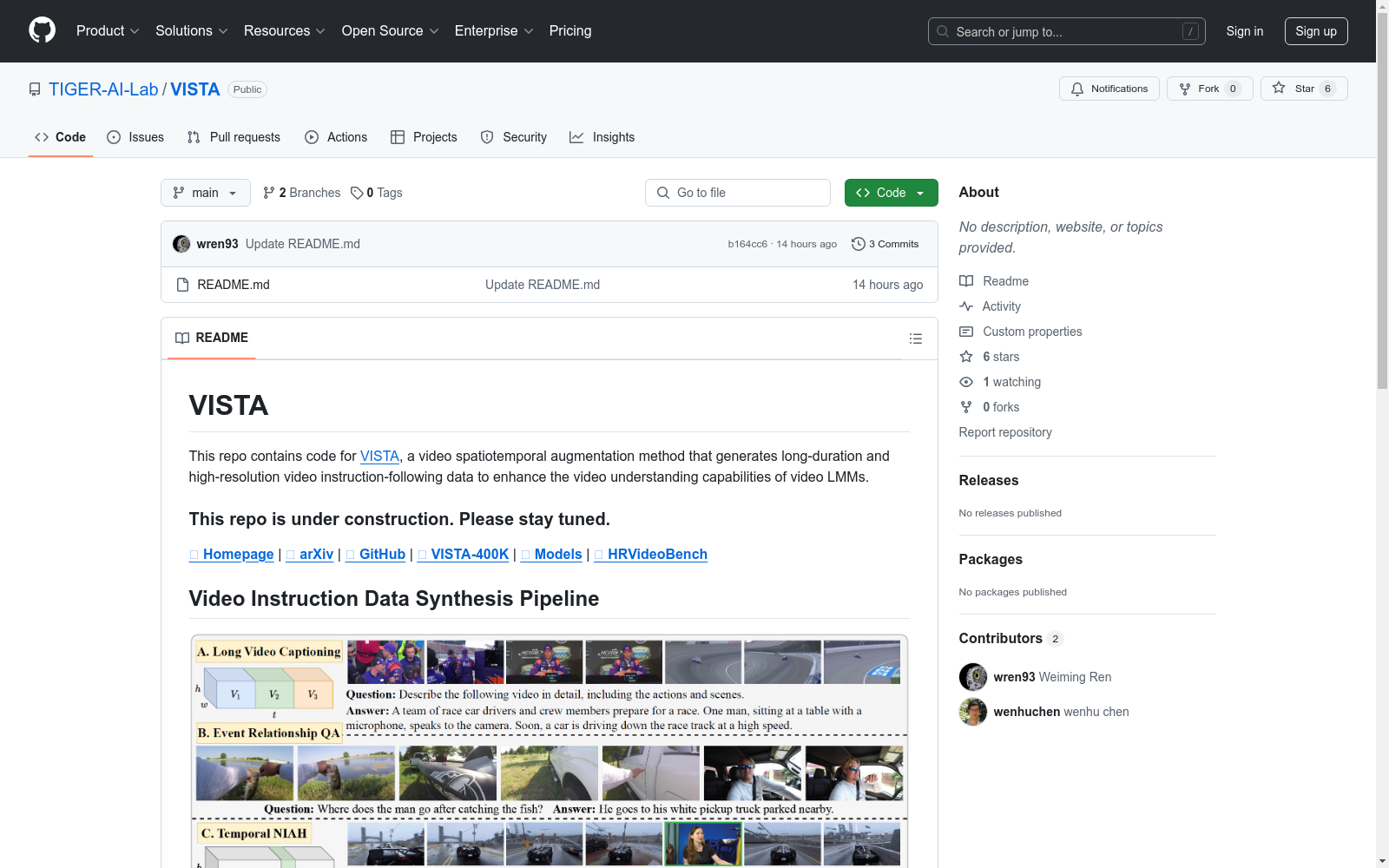
构建方式
VISTA-400K数据集的构建基于视频时空增强技术,通过融合图像和视频分类数据增强方法,如CutMix、MixUp和VideoMix,生成具有更长时长和更高分辨率的人工增强视频样本。随后,基于这些新视频合成指令数据。该数据集的构建利用了现有的公开视频字幕数据集,确保了其开源性和可扩展性,从而构建出高质量的视频指令跟随数据集,旨在提升视频语言模型对长时和高分辨率视频的理解能力。
使用方法
VISTA-400K数据集适用于提升视频语言模型对长时和高分辨率视频的理解能力。研究者和开发者可以通过访问Hugging Face平台获取该数据集,并将其应用于视频理解模型的训练和评估。使用时,建议结合VISTA提供的代码和方法,以最大化数据集的效用。
背景与挑战
背景概述
VISTA-400K数据集由TIGER-AI实验室开发,旨在通过视频时空增强方法生成长时间和高分辨率的视频指令跟随数据,以提升视频语言模型(LMMs)的视频理解能力。该数据集的核心研究问题是如何通过合成数据增强技术,如CutMix、MixUp和VideoMix,来创建更鲁棒的视频分类器。VISTA-400K的构建基于现有的公开视频字幕数据集,确保了其开放性和可扩展性。该数据集的发布预计将对视频理解和视频指令跟随领域产生深远影响。
当前挑战
VISTA-400K数据集在构建过程中面临的主要挑战包括:1) 如何有效地将多种视频增强技术结合,以生成高质量的合成视频数据;2) 确保合成数据在长时间和高分辨率条件下的语义一致性和视觉质量;3) 在利用现有公开数据集的同时,保持数据集的多样性和代表性。此外,该数据集的应用还面临如何有效训练和验证视频语言模型,以充分利用其增强的视频理解能力的挑战。
常用场景
经典使用场景
在视频理解领域,VISTA-400K数据集的经典使用场景主要集中在提升视频长时程和高分辨率理解能力。通过利用图像和视频分类数据增强技术,如CutMix、MixUp和VideoMix,VISTA-400K生成了一系列合成视频样本,这些样本具有更长的持续时间和更高的分辨率。随后,基于这些新视频,数据集进一步合成了指令数据,从而为视频语言模型(LMMs)提供了丰富的训练资源,以增强其在复杂视频内容理解中的表现。
解决学术问题
VISTA-400K数据集解决了视频理解领域中长期存在的学术研究问题,即如何有效提升视频语言模型对长时程和高分辨率视频的理解能力。传统的视频数据集往往受限于视频长度和分辨率,难以全面覆盖复杂场景。VISTA-400K通过合成高质视频样本,填补了这一空白,为研究者提供了一个强大的工具,推动了视频理解技术的进步,具有重要的学术意义和广泛的影响。
实际应用
在实际应用中,VISTA-400K数据集显著提升了视频监控、自动驾驶和智能视频分析等领域的性能。例如,在视频监控系统中,该数据集使得系统能够更准确地识别和跟踪长时间和高分辨率视频中的目标,从而提高了监控的效率和安全性。在自动驾驶领域,VISTA-400K帮助车辆更好地理解复杂路况,提升了驾驶决策的准确性和安全性。
数据集最近研究
最新研究方向
在视频理解和长时程高分辨率视频处理领域,VISTA-400K数据集的最新研究方向主要集中在通过视频时空增强技术来提升视频语言模型(LMMs)的能力。该数据集利用图像和视频分类数据增强技术,如CutMix、MixUp和VideoMix,通过空间和时间上的视频组合生成具有更长时长和更高分辨率的人工增强视频样本。随后,基于这些新视频合成指令数据,从而构建出高质量的视频指令跟随数据集。这一研究不仅推动了视频理解技术的发展,还为长时程和高分辨率视频处理提供了新的数据资源,具有重要的学术和应用价值。
以上内容由遇见数据集搜集并总结生成


