crypto-education-en-golden-set
收藏Hugging Face2026-02-15 更新2026-02-16 收录
下载链接:
https://huggingface.co/datasets/kskada/crypto-education-en-golden-set
下载链接
链接失效反馈官方服务:
资源简介:
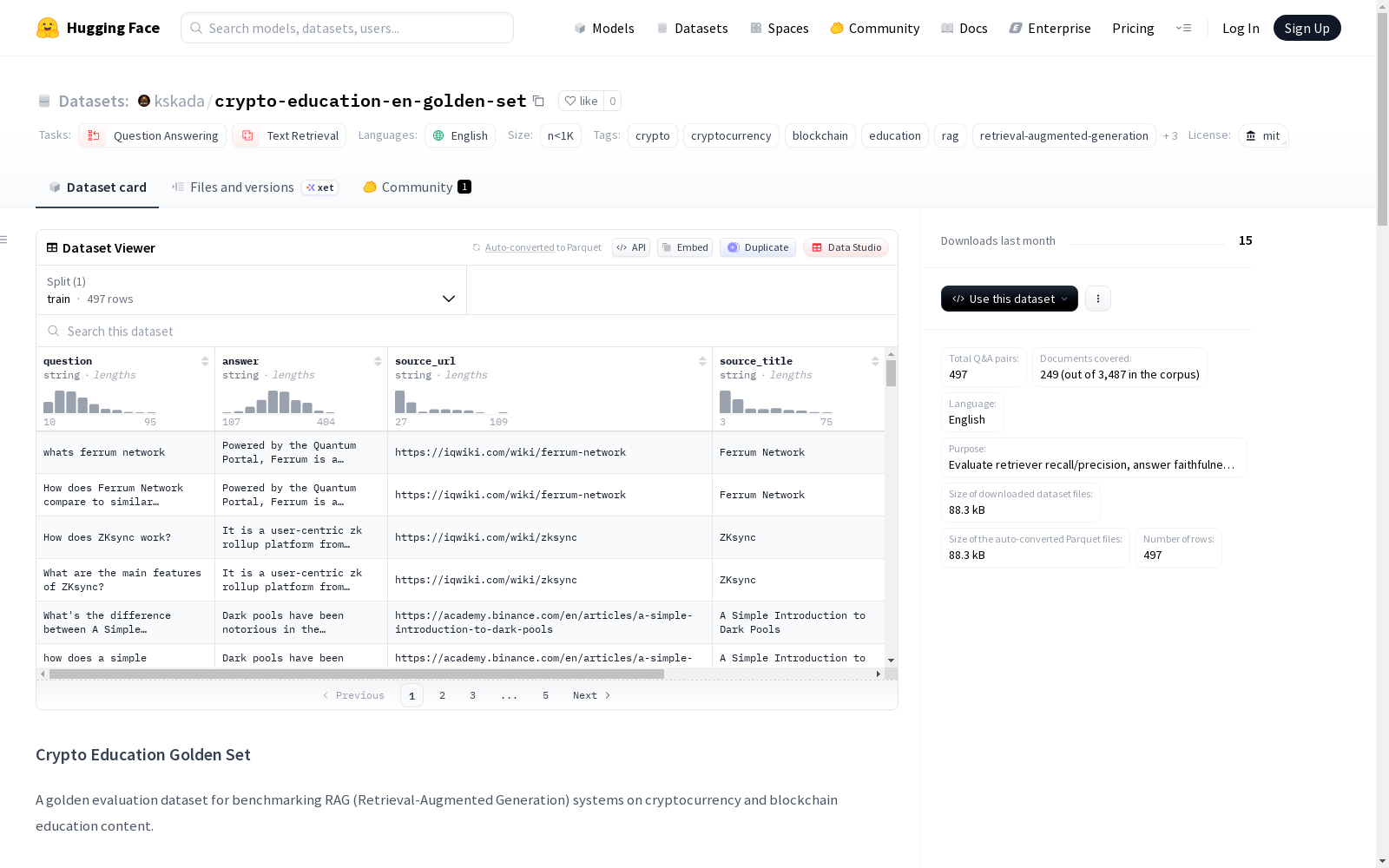
Crypto Education Golden Set 是一个用于评估检索增强生成(RAG)系统在加密货币和区块链教育内容上表现的黄金标准数据集。该数据集包含497个问答对,覆盖了249个文档(总语料库包含3,487个文档)。数据语言为英语,旨在评估检索器的召回率/精确度、答案的忠实度以及端到端RAG系统的质量。数据集包含以下字段:问题(question)、参考答案(answer)、源文档URL(source_url)、源文档标题(source_title)、主题类别(topic)和问题类型(question_type)。问题类型分布包括事实性(44.9%)、程序性(15.3%)、关键词搜索(13.5%)、非正式(13.1%)、比较(9.9%)和拼写错误(3.4%)等,以模拟真实用户查询。主题分布涵盖DeFi/NFT/Web3(37.8%)、钱包/安全(17.5%)、挖矿/质押/共识(10.9%)等。数据集采用分层抽样方法生成,并通过LLM(Claude)基于文档内容生成问答对,确保语言多样性和内容相关性。
创建时间:
2026-02-15
原始信息汇总
Crypto Education Golden Set 数据集概述
数据集基本信息
- 数据集名称: Crypto Education Golden Set
- 主要用途: 用于在加密货币和区块链教育内容上对检索增强生成(RAG)系统进行基准测试的金标准评估数据集。
- 语言: 英语
- 许可证: MIT
- 数据规模: 小于1K(n<1K)
- 任务类别: 问答、文本检索
数据内容
- 问答对总数: 497
- 覆盖的文档数: 249(源自总语料库的3,487个文档)
- 数据列:
question: 用户提出的英文问题。answer: 参考答案(2-3句话)。source_url: 语料库中源文档的URL。source_title: 源文档的标题。topic: 主题类别。question_type: 问题的语言风格类型。
问题类型分布
数据集旨在模拟真实的用户查询,分布如下:
- factual (事实性): 223个,占44.9%。例如:“What is X?”, “How does X work?”
- procedural (程序性): 76个,占15.3%。例如:“How do I X?”, “What steps are needed?”
- keyword (关键词): 67个,占13.5%。例如:搜索风格的“bitcoin mining energy”。
- informal (非正式): 65个,占13.1%。例如:口语化的“is defi safe to use”。
- comparison (比较): 49个,占9.9%。例如:“Whats the difference between X and Y?”
- typo (拼写错误): 17个,占3.4%。例如:“whats the differnce betwen...”
主题分布
- defi_nft_web3: 188个,占37.8%
- wallets_security: 87个,占17.5%
- mining_staking_consensus: 54个,占10.9%
- tokens_stablecoins: 39个,占7.8%
- exchanges_trading: 36个,占7.2%
- blockchain_projects: 35个,占7.0%
- core_concepts: 26个,占5.2%
- smart_contracts: 25个,占5.0%
- taxes_regulation: 7个,占1.4%
生成方法
- 分层抽样: 按源分布比例抽样249份文档,并根据字数(短/中/长)进行分层。
- 大语言模型生成: 使用Claude为每份抽样文档生成2个基于文档内容的问答对。
- 语言多样性: 分配不同问题类型以模拟真实用户行为。
- 去重: 移除重复的问题。
评估目的
用于评估检索器的召回率/精确度、答案忠实度以及端到端RAG系统的质量。
相关数据集
- 语料库:
kskada/crypto-education-en-corpus— 包含3,487个教育文档。 - 语料库链接: https://huggingface.co/datasets/kskada/crypto-education-en-corpus
引用格式
@dataset{konovalov2026crypto_golden, title={Crypto Education Golden Set for RAG Evaluation}, author={Konovalov, Kirill}, year={2026}, publisher={HuggingFace}, url={https://huggingface.co/datasets/kskada/crypto-education-en-golden-set} }
搜集汇总
数据集介绍
构建方式
在加密货币与区块链教育领域,高质量评估数据集的构建对于衡量检索增强生成系统的性能至关重要。该数据集通过分层抽样策略,从包含3487份文档的语料库中选取249份代表性文档,确保覆盖不同篇幅与主题分布。随后利用大型语言模型基于每份文档内容生成两个问答对,并精心设计问题类型以模拟真实用户查询行为,涵盖事实性、程序性及包含拼写错误的非正式提问等多种语言风格。最后经过去重处理,形成包含497个高质量问答对的评估集合。
特点
该数据集的核心特征在于其高度仿真的问题设计,能够全面检验检索增强生成系统在加密货币教育场景下的实际表现。问题类型分布经过精心规划,44.9%为事实性问题,同时包含15.3%的程序性询问、13.5%的关键词搜索式提问以及13.1%的日常口语化表达,甚至模拟了3.4%的拼写错误情况。主题覆盖范围广泛,从去中心化金融与非同质化代币到钱包安全、共识机制等关键领域均有涉及,确保了评估内容的多样性与代表性。
使用方法
该数据集主要用于评估检索增强生成系统的综合性能,包括检索器的召回率与精确度、生成答案的忠实性以及端到端系统的整体质量。研究人员可通过加载数据集与对应语料库,针对每个问题验证系统检索到的文档是否包含预设的参考答案来源。典型使用流程包括将数据集转换为数据框结构,遍历每个问题并调用自定义检索器获取相关文档,进而通过比对预期来源网址与检索结果来量化系统表现,为优化区块链教育问答系统提供可靠的基准测试工具。
背景与挑战
背景概述
随着区块链与加密货币技术的迅猛发展,相关教育内容日益丰富,如何高效、准确地从海量信息中检索并生成可靠答案成为研究热点。在此背景下,由研究人员Kirill Konovalov于2026年构建的Crypto Education Golden Set数据集应运而生,旨在为检索增强生成系统在加密货币与区块链教育领域的性能评估提供黄金标准。该数据集聚焦于解决RAG系统在专业垂直领域中的检索准确性、答案忠实度及端到端生成质量等核心研究问题,通过精心设计的497对问答数据,覆盖去中心化金融、钱包安全、挖矿共识等多个主题,为推进金融科技与自然语言处理交叉领域的研究提供了关键基准。
当前挑战
该数据集致力于应对加密货币教育领域问答系统面临的独特挑战:首先,专业术语密集且概念迭代迅速,要求模型具备精准的领域知识理解与实时更新能力;其次,用户查询风格高度多样化,涵盖事实性、程序性乃至包含拼写错误的非正式提问,对系统的鲁棒性与泛化性构成严峻考验。在构建过程中,挑战同样显著:需从数千份文档中通过分层抽样确保内容代表性,同时利用大语言模型生成既忠实于原文又符合真实用户语言分布的问答对,并有效消除重复项,以维持数据集的平衡性与评估效度。
常用场景
经典使用场景
在加密货币与区块链教育领域,高质量问答系统的评估长期缺乏标准化基准。该数据集通过精心构建的497个问答对,为检索增强生成(RAG)系统提供了经典的评估场景。研究者利用其分层采样的文档与多样化的提问类型,能够系统性地测试检索器的召回率与精确度,以及生成答案的忠实性与整体系统性能,从而在受控环境中模拟真实用户的复杂查询行为。
衍生相关工作
围绕该数据集,已衍生出一系列专注于垂直领域RAG评估的经典研究工作。例如,基于其构建的评估框架被用于比较不同检索器与大型语言模型的组合效能。同时,它启发了针对其他专业领域(如法律、医疗)的类似黄金标准数据集的创建,推动了领域自适应评估方法的发展,并促进了关于如何处理用户非正式查询、拼写错误等现实挑战的算法研究。
数据集最近研究
最新研究方向
在加密货币与区块链教育领域,高质量评估数据集的构建正成为推动检索增强生成技术发展的关键。Crypto Education Golden Set作为专门针对该领域设计的黄金评估集,其前沿研究聚焦于优化RAG系统的多维度性能评测。当前热点探索方向包括利用该数据集对检索器的召回率与精确度进行细粒度分析,以应对去中心化金融、非同质化代币等复杂主题的查询需求。同时,研究也致力于通过模拟真实用户提问风格,如包含拼写错误或非正式表达的查询,来提升生成答案的忠实性与可靠性。这些进展不仅为区块链教育内容的智能化服务提供了基准工具,也促进了跨领域知识检索技术的标准化进程,具有显著的学术与实践意义。
以上内容由遇见数据集搜集并总结生成


