druid
收藏资源简介:
DRUID数据集包含真实世界的(查询,上下文)对,旨在促进对真实世界RAG(检索增强生成)场景中上下文使用和失败的研究。数据集基于自动化声明验证的原型任务,其中自动化检索真实世界的证据至关重要。因此,有时也将“查询”称为“声明”,将“上下文”称为“证据”。数据集包含两个版本:DRUID和DRUID+,其中DRUID是DRUID+的一个高质量子集,手动标注了证据的相关性和立场。数据集的结构包括多个字段,如唯一标识符、声明、证据、证据来源等。数据集的创建过程包括声明收集、证据收集以及相关性和立场标注。
The DRUID dataset comprises real-world (query, context) pairs, developed to advance research on context utilization and failure patterns in real-world Retrieval-Augmented Generation (RAG) scenarios. The dataset is grounded on a prototypical task of automated claim verification, where automated retrieval of real-world evidence is critically important. Accordingly, the terms "query" and "context" are sometimes referred to as "claim" and "evidence", respectively. The dataset offers two variants: DRUID and DRUID+. DRUID is a high-quality subset of DRUID+, which has been manually annotated for evidence relevance and stance. The dataset structure includes multiple fields such as unique identifier, claim, evidence, evidence source, and others. The dataset creation process encompasses claim collection, evidence collection, as well as relevance and stance annotation.
DRUID 数据集概述
数据集基本信息
- 许可证: MIT
- 语言: 英语 (en)
- 数据集名称: DRUID (Dataset of Retrieved Unreliable, Insufficient and Difficult-to-understand context)
- 数据集配置:
- DRUID: 包含高质量的子集,手动标注了证据相关性和立场。
- DRUID+: 包含更多的证据片段,未手动标注。
数据集描述
DRUID 数据集包含真实世界的 (查询, 上下文) 对,旨在促进对真实世界 RAG 场景中上下文使用和失败的研究。数据集基于自动声明验证的原型任务,自动检索真实世界的证据至关重要。因此,有时也将“查询”称为“声明”,将“上下文”称为“证据”。
数据集用途
- 评估模型对上下文的使用。
- 测试自动声明验证方法。
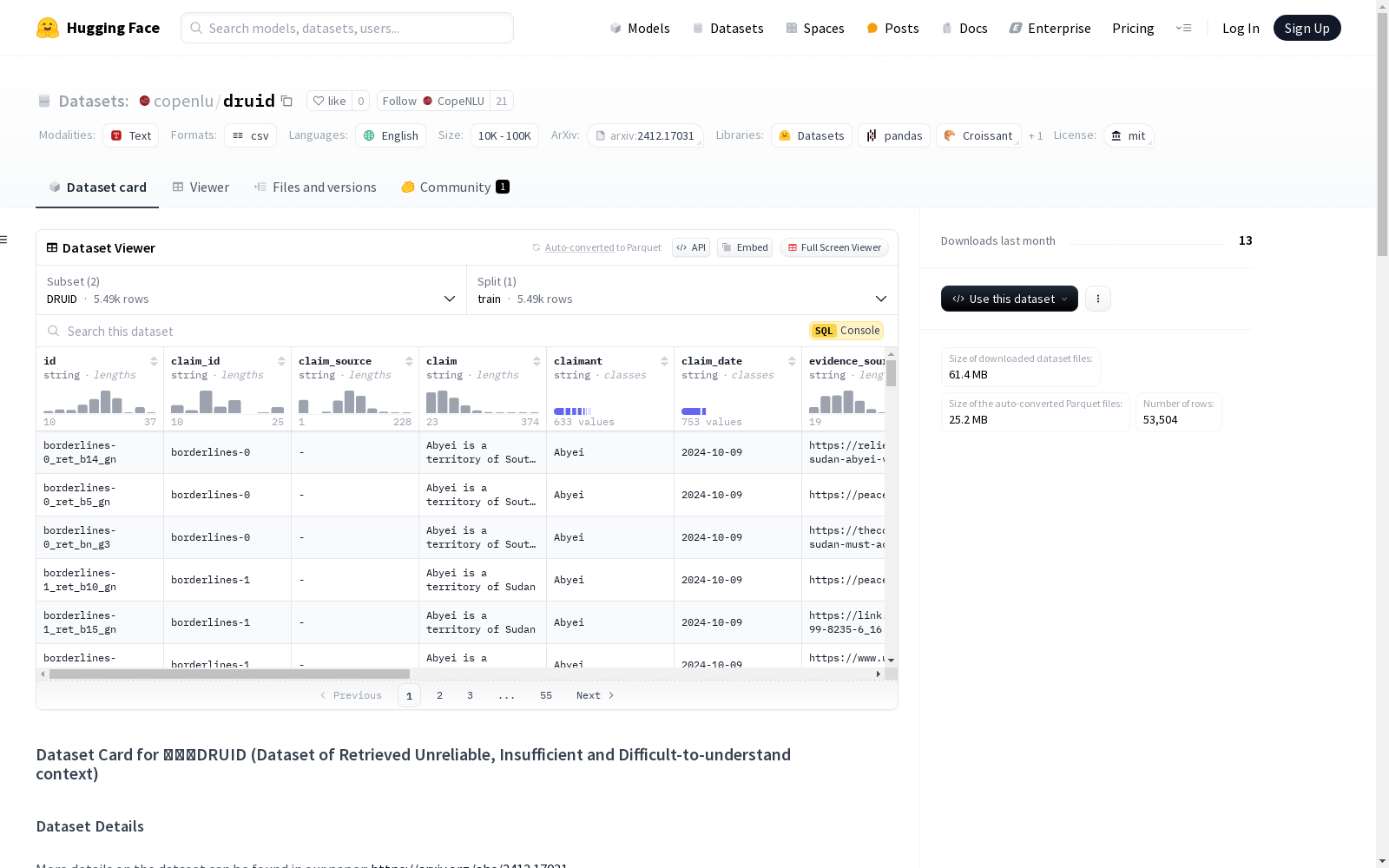
数据集结构
数据集包含以下列:
- id: 每个数据样本的唯一标识符,也表示声明来源。
- claim_id: 每个声明的唯一标识符,一个声明可能对应多个样本。
- claim_source: 从中检索到样本声明的事实检查站点文章。
- claim: 关于世界的声明/查询。
- claimant: 声明背后的人/组织。
- claim_date: 声明在事实检查站点发布的日期。
- evidence_source: 从中检索到证据的网页。
- evidence: 用于评估给定声明真实性的证据/上下文。
- evidence_data: 检索到证据的网页发布日期。
- factcheck_verdict: 关于声明的事实检查结论,不一定与证据立场一致。
- is_gold: 证据是否从相应的事实检查站点检索或“从野外检索”。
- relevant: 证据是否与给定声明相关,已在 DRUID 样本中手动标注。
- evidence_stance: 证据的立场,即是否支持声明、不足支持、不足中立、不足矛盾、不足反驳或反驳,已在 DRUID 样本中手动标注。
数据集创建
声明收集
使用 Googles Factcheck API 收集由事实检查员验证的声明,仅收集英语声明。声明来自 7 个不同的事实检查来源,涵盖科学、政治、北爱尔兰、斯里兰卡、美国、印度、法国等。
证据收集
对于 DRUID 和 DRUID+ 中的每个声明,分别检索最多 5 和 40 个证据片段。首先从原始事实检查站点检索黄金标准证据文档,然后使用自动检索方法检索其余证据片段。
相关性和立场标注
使用 Prolific 和 Potato 进行众包证据级标注,每个证据片段在 DRUID 中都被双重标注为相关或不相关,并标注其立场。
引用
@misc{druid, title={A Reality Check on Context Utilisation for Retrieval-Augmented Generation}, author={Lovisa Hagström and Sara Vera Marjanović and Haeun Yu and Arnav Arora and Christina Lioma and Maria Maistro and Pepa Atanasova and Isabelle Augenstein}, year={2024}, eprint={2412.17031}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2412.17031}, }