DIWALI -Diversity and Inclusivity aWare cuLture specific Items for India
收藏arXiv2025-09-22 更新2025-09-24 收录
下载链接:
https://huggingface.co/datasets/nlip/DIWALI
下载链接
链接失效反馈官方服务:
资源简介:
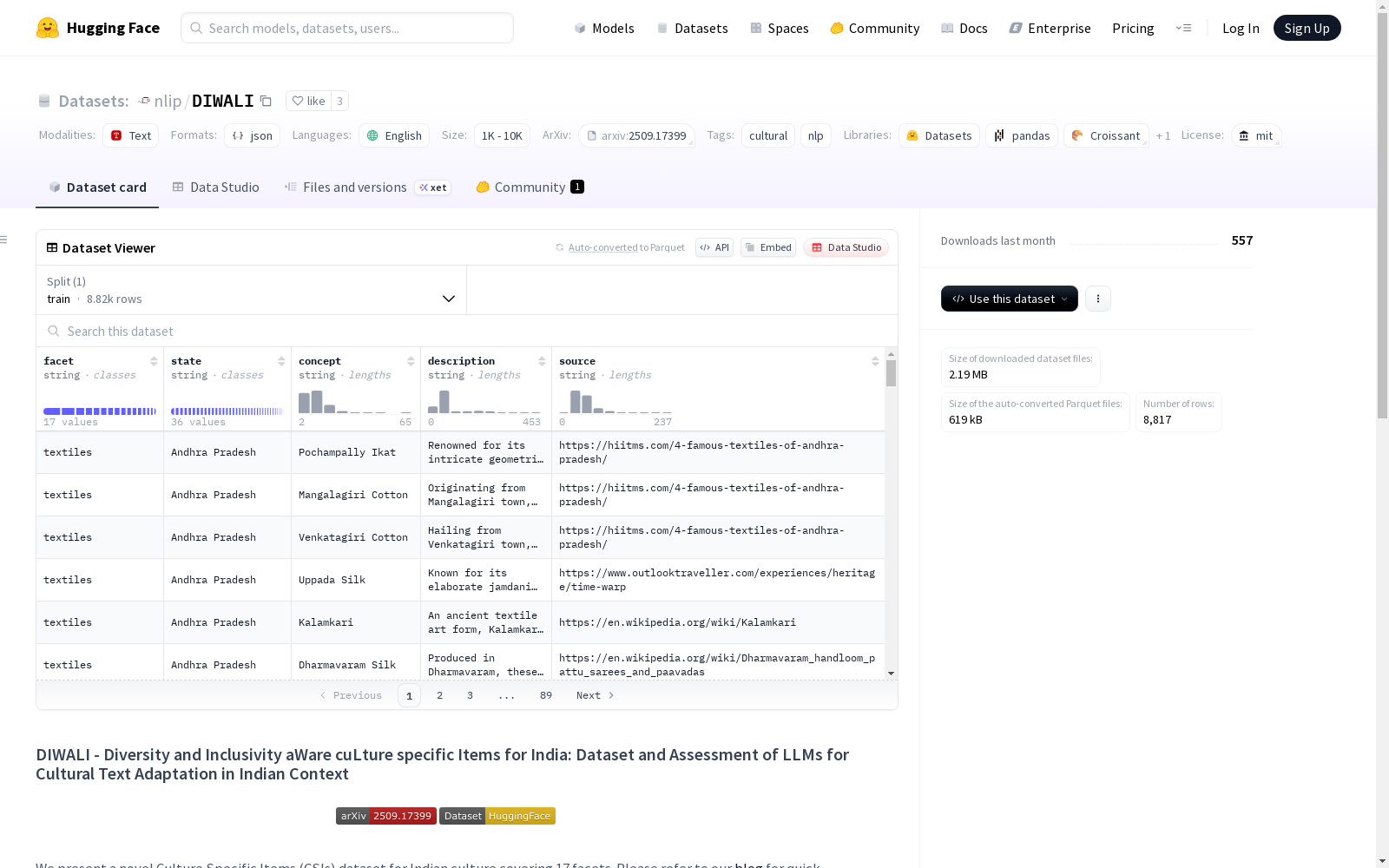
DIWALI是一个涵盖印度文化多样性的高质量数据集,包含了来自印度36个子地区的约8k个文化概念,涵盖了17个文化层面。该数据集的创建旨在为文化文本适应任务提供评估指标,并解决现有数据集在文化概念表示上的不足。数据集的内容包括从GPT-4和网页搜索中提取的文化概念,并经过两阶段的验证过程确保其可靠性和文化有效性。DIWALI数据集为文化文本适应任务提供了宝贵的资源,有助于评估大型语言模型的文化适应能力,并促进跨文化交际领域的进一步研究。
DIWALI is a high-quality dataset encompassing the cultural diversity of India. It contains approximately 8,000 cultural concepts sourced from 36 sub-regions across the country, covering 17 cultural dimensions. Developed to provide evaluation metrics for cultural text adaptation tasks and address the shortcomings of existing datasets in representing cultural concepts, the dataset consists of cultural concepts extracted from GPT-4 and web searches, and has undergone a two-stage verification process to ensure its reliability and cultural validity. As a valuable resource for cultural text adaptation tasks, the DIWALI dataset aids in evaluating the cultural adaptation capabilities of large language models and promotes further research in the field of cross-cultural communication.
提供机构:
印度理工学院海得拉巴分校自然语言与信息处理实验室 (NLIP)
创建时间:
2025-09-22
原始信息汇总
DIWALI 数据集概述
数据集简介
DIWALI(Diversity and Inclusivity aWare cuLture specific Items for India)是一个针对印度文化的文化特定项目(CSIs)数据集,专注于文化文本适应在印度语境中的应用。
核心特征
- 文化概念数量:8817个
- 文化国家:印度
- 覆盖子区域:36个(印度境内)
- 文化背景:区域和国家特定
文化维度覆盖
数据集涵盖17个文化维度:食物、舞蹈、节日、姓名、珠宝、地点、传统、语言、服装、游戏、仪式、建筑、饮料、艺术、纺织品、宗教和邦。
引用信息
bibtex @misc{sahoo2025diwalidiversityinclusivity, title={DIWALI - Diversity and Inclusivity aWare cuLture specific Items for India: Dataset and Assessment of LLMs for Cultural Text Adaptation in Indian Context}, author={Pramit Sahoo and Maharaj Brahma and Maunendra Sankar Desarkar}, year={2025}, eprint={2509.17399}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2509.17399}, }
联系方式
- Maharaj Brahma:cs23resch01004@iith.ac.in
- Pramit Sahoo:pramitsahoo.gnipst@gmail.com
相关资源
- 论文地址:https://arxiv.org/abs/2509.17399
- 数据集地址:https://huggingface.co/datasets/nlip/DIWALI
- 博客地址:https://nlip-lab.github.io/nlip/publications/diwali/
搜集汇总
数据集介绍
构建方式
DIWALI数据集的构建采用了多源验证的混合方法,首先通过GPT-4o生成初始文化概念,并辅以维基百科作为基础来源。为克服单一来源的局限性,研究团队进一步整合了GPT-4o-plus与网络搜索技术,系统性地采集印度各邦及中央直辖区的官方文化与旅游网站信息,确保数据覆盖的广度与真实性。每个文化概念均经过两阶段质量验证:链接有效性检查确保来源可追溯,概念描述则通过印度政府门户、考古调查局等权威渠道进行交叉验证,最终形成包含8,817个文化概念的精细化数据集。
特点
该数据集以印度文化的深层多样性为核心特征,涵盖服饰、饮食、仪式、语言等17个文化维度,精准映射36个行政区域的独特文化元素。其显著优势在于对次区域层级的细致划分,例如将阿萨姆邦的博多族、拉巴族等社群文化纳入统一框架,避免了过度碎片化。数据分布呈现高度均衡性,食品类概念达1,419项,舞蹈形式类1,105项,其余维度均保持合理覆盖。相较于现有资源,DIWALI在文化颗粒度与地域代表性方面实现突破,为文化计算研究提供了立体化的知识基底。
使用方法
该数据集专为文化文本适应任务设计,使用者可通过结构化提示词引导大语言模型完成文化概念替换。具体流程包括:将源文本中的文化实体(如人名、地名、节日)映射至DIWALI中的对应印度文化概念,同时保持原始语义逻辑与数学完整性。评估阶段可采用适配度评分机制,通过精确匹配与模糊匹配策略量化文化替换的准确性。此外,数据集支持跨语言应用,其孟加拉语版本经零样本翻译与人工校验,适用于多语种文化适应研究。使用者还可结合LLM-as-Judge框架与人工评估,从文化相关性、语言流畅度等维度进行综合评测。
背景与挑战
背景概述
DIWALI数据集由印度理工学院海得拉巴分校自然语言与信息处理实验室于2025年提出,旨在构建一个覆盖印度次区域文化多样性的文化特定项目资源。该数据集聚焦于评估大型语言模型在文化文本适应任务中的表现,核心研究问题涉及模型对印度多元文化语境的理解与生成能力。DIWALI包含8,817个文化概念,涵盖服饰、饮食、仪式等17个文化维度,跨越36个行政区域,为文化感知计算提供了细粒度标注基础。其创建填补了现有资源如CANDLE和DOSA在印度文化覆盖广度与深度上的不足,推动了跨文化自然语言处理研究的发展。
当前挑战
在文化文本适应领域,DIWALI需解决模型对非西方文化语境适应能力不足的挑战,具体表现为概念替换的浅层化与次区域覆盖偏差。构建过程中的挑战包括文化概念验证的复杂性,需通过多源人工校验确保概念的真实性与代表性;其次,数据收集需平衡Wikipedia的广度与官方文化资源的深度,避免西方中心主义导致的标注噪声。此外,评估体系需兼顾自动指标如CSI适应分数与人类标注的主观文化共鸣,克服LLM作为评判者时对表面替换的过拟合问题。
常用场景
经典使用场景
DIWALI数据集在文化文本适应任务中展现出其核心价值,通过将源文化背景的文本转化为符合印度目标文化语境的表达。该数据集在评估大型语言模型的文化适应能力时,通常被用于替换文本中的文化特定项目,例如将西方人名转换为印度常见姓名,将外来食品替换为本土特色美食。这种适应性转换不仅涉及表层词汇的替换,更要求模型深入理解印度各子区域的文化习俗与社会规范,从而生成具有文化共鸣的文本内容。
实际应用
在实际应用层面,DIWALI数据集为跨文化教育内容本地化、多语言客户服务系统优化提供了技术基础。例如在在线教育平台中,基于该数据集开发的适应系统能够将数学应用题中的西方文化元素自动转换为印度学生熟悉的场景,如将“感恩节火鸡”替换为“排灯节甜点”。在旅游业领域,该数据集支持生成符合地方文化习惯的导游解说词,避免因文化误读引发的沟通障碍,显著提升跨文化服务的用户体验。
衍生相关工作
该数据集的发布催生了多项文化计算领域的创新研究。部分学者基于DIWALI构建了文化适应质量自动评估框架,通过结合模糊匹配算法与语义相似度计算,实现了对模型生成文本文化相关性的量化评分。另有研究团队利用该数据集训练文化感知的机器翻译模型,在保持原文语义的同时动态调整文化指称项。这些衍生工作共同推动形成了以细粒度文化知识库为核心的新型研究范式,为后续开展文化多样性保护的数字技术研究奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


