Alaska
收藏arXiv2021-02-03 更新2024-06-21 收录
下载链接:
https://github.com/merialdo/research.alaska
下载链接
链接失效反馈官方服务:
资源简介:
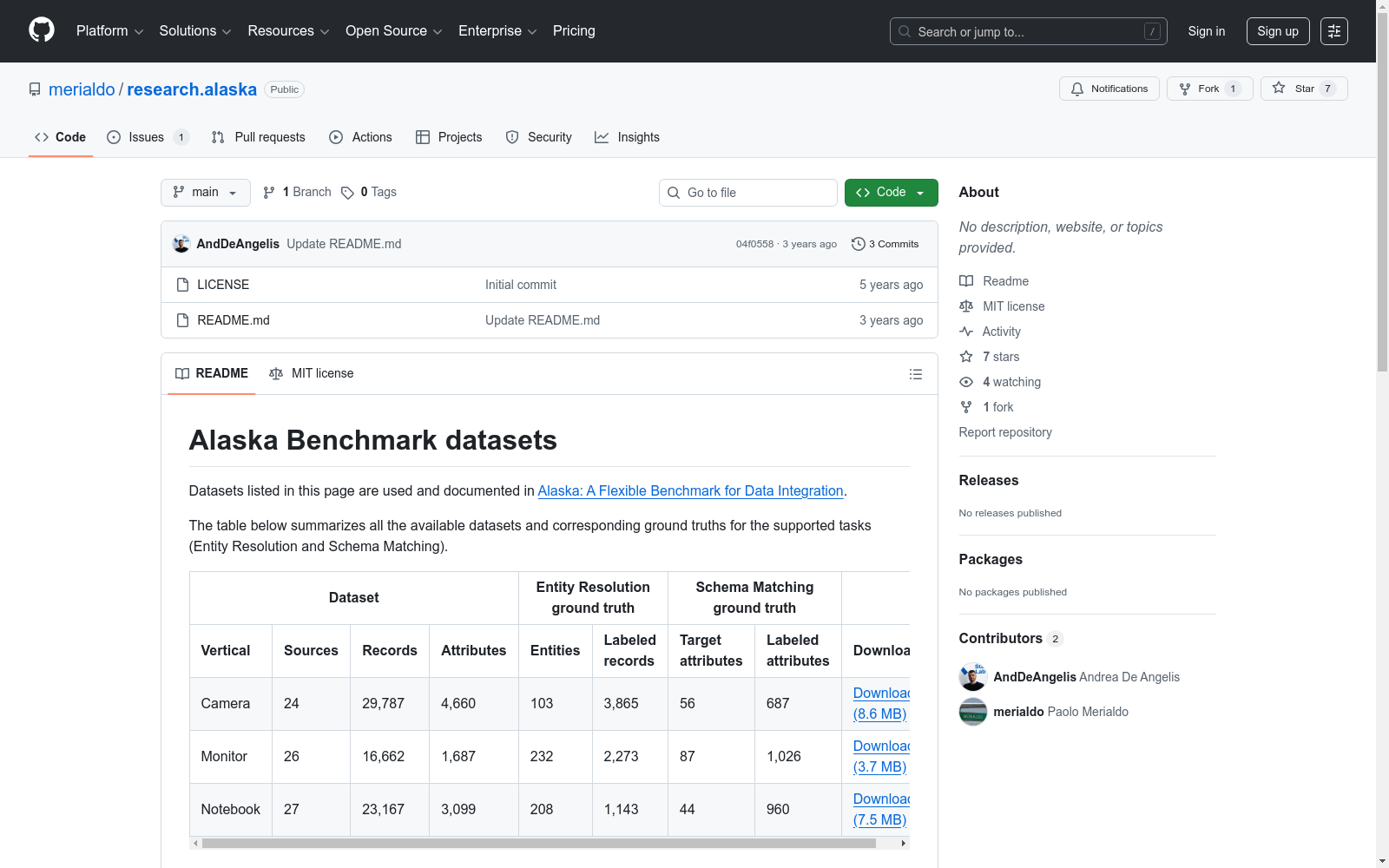
Alaska数据集是由罗马第三大学的研究团队创建,包含近70,000个产品规格,这些数据从71个不同的网络数据源中提取,覆盖相机、显示器和笔记本电脑三个领域。数据集通过三个步骤构建:首先使用Dexter聚焦爬虫发现和爬取网络数据源;其次,通过定制方法从网页中提取产品规格;最后,由领域专家手动策划基准任务的地面真相。Alaska数据集支持多种数据集成任务,特别关注模式匹配和实体解析,旨在评估和促进更全面的数据集成解决方案的设计。
The Alaska dataset was created by a research team from Roma Tre University. It contains nearly 70,000 product specifications extracted from 71 distinct web data sources, covering three domains: cameras, displays, and laptops. The dataset is constructed via three sequential steps: first, the Dexter focused crawler is used to discover and crawl web data sources; second, customized methods are applied to extract product specifications from web pages; finally, domain experts manually curate the ground truth for benchmark tasks. The Alaska dataset supports multiple data integration tasks, with a particular focus on schema matching and entity resolution, aiming to evaluate and facilitate the development of more comprehensive data integration solutions.
提供机构:
罗马第三大学
创建时间:
2021-01-27
搜集汇总
数据集介绍
构建方式
在数据集成领域,构建具有现实世界复杂性的基准数据集对评估端到端流程至关重要。Alaska数据集通过系统化的三层流程构建:首先利用DEXTER聚焦爬虫从71个电子商务网站发现并爬取产品页面;随后采用专门开发的Carbonara提取工具,通过基于DOM特征和领域关键词的分类器从HTML页面中抽取产品规格,形成扁平化的JSON记录;最终由领域专家团队对模式匹配和实体解析任务进行人工标注,构建大规模且经过验证的黄金标准数据。该过程严格遵循3-3-100启发式规则进行数据过滤,确保数据质量与代表性。
使用方法
Alaska数据集为数据集成研究提供了模块化的评估框架。研究者可针对模式匹配和实体解析两大核心任务及其变体(如基于目录的模式匹配、中介模式匹配、自连接实体解析、相似性连接实体解析及模式无关实体解析)进行方法评估。使用前需通过数据集提供的剖析指标选择符合目标场景的数据源子集,例如选择低属性稀疏度的源用于评估对完整信息依赖较强的实体解析方法。数据集附带的黄金标准数据可用于监督学习方法的训练与测试,其大规模人工标注确保了评估结果的可靠性。通过灵活组合不同垂直领域和数据源特性,研究者能够系统评估方法在不同数据分布和挑战下的鲁棒性与泛化能力。
背景与挑战
背景概述
数据集成作为数据管理领域的核心议题,长期受到学术界与工业界的广泛关注。Alaska数据集由罗马第三大学与AT&T首席数据办公室的研究团队于2021年联合发布,旨在构建一个基于真实世界数据的灵活基准测试平台。该数据集聚焦于解决数据集成流程中的核心挑战,特别是模式匹配与实体解析两大关键任务。其数据来源于71个电子商务网站,涵盖相机、显示器和笔记本三大垂直领域,包含近7万条异构产品规格数据,涉及超过1.5万个不同的产品属性。Alaska的推出填补了现有基准测试在支持端到端数据集成流程评估方面的空白,通过提供丰富的元数据描述、预定义用例及人工标注的真实基准,为复杂数据集成管线的系统化评测奠定了坚实基础,显著推动了数据集成方法的研究与比较。
当前挑战
Alaska数据集所应对的核心领域挑战在于数据集成流程中模式匹配与实体解析任务的复杂性与异构性。在模式匹配任务中,数据集呈现了同义词(如不同属性名指向相同属性)、同形异义词(如相同属性名指向不同属性)以及属性粒度差异所引发的一对多、多对多映射关系。实体解析任务则面临数据表示多样性、噪声干扰以及实体分布高度偏斜等难题,例如同一实体在不同数据源中可能采用完全不同的格式或命名约定,而部分实体在数据集中存在过度表示。在构建过程中,研究团队需克服从真实网络源中高质量提取产品规格、处理高度稀疏与异构的数据结构,以及通过人工专家标注大规模真实基准所带来的巨大成本与一致性维护等工程挑战。
常用场景
经典使用场景
在数据集成研究领域,Alaska数据集被广泛用于评估和比较模式匹配与实体解析算法的性能。该数据集汇集了来自71个电子商务网站的7万条异构产品规格数据,覆盖相机、显示器和笔记本三大垂直领域,其真实世界的复杂性和丰富的元数据为研究者提供了模拟实际集成场景的理想环境。通过灵活配置不同数据源组合,研究人员能够针对特定任务变体(如基于目录的模式匹配或自连接的实体解析)设计实验,从而系统性地考察算法在应对属性稀疏性、词汇重叠度变化等挑战时的鲁棒性。
解决学术问题
Alaska数据集有效解决了数据集成研究中长期存在的基准测试碎片化问题。传统基准往往局限于单一任务定义,难以支持端到端集成流程的评估。该数据集通过提供统一且可扩展的真实数据源,使得研究者能够系统考察模式匹配中的同义词与多粒度对应关系,以及实体解析中的表示多样性与噪声干扰等核心学术难题。其手工标注的大规模基准真值不仅提升了评估结果的可靠性,更促进了跨任务方法的对比与融合,为构建更完整的数据集成理论框架奠定了实证基础。
实际应用
在电子商务数据治理与知识图谱构建等实际场景中,Alaska数据集发挥着重要的桥梁作用。企业可利用其多源异构的产品规格数据,训练自动化系统实现跨平台商品信息的归一化整合,从而提升供应链管理效率与客户体验。例如,零售企业可借鉴该数据集的实体解析方法,解决不同电商平台间商品重复列表的识别问题;数据服务商则可基于其模式匹配基准优化属性对齐算法,为跨域数据融合提供标准化解决方案。这些应用显著降低了多源数据协同的成本与复杂度。
数据集最近研究
最新研究方向
在数据集成领域,Alaska数据集作为首个基于真实世界数据的多任务基准,正推动着端到端集成流程的评估方法革新。当前研究聚焦于利用其异构性强的产品规格数据,探索模式匹配与实体解析任务的复杂变体,特别是在处理属性稀疏性、词汇重叠度及集群分布偏斜等挑战时的算法鲁棒性。该数据集已成功应用于SIGMOD编程竞赛和DI2KG挑战赛,促进了基于深度学习与自然语言处理的集成技术发展,并为构建更全面的数据集成管线提供了关键实验平台。
相关研究论文
- 1Alaska: A Flexible Benchmark for Data Integration Tasks罗马第三大学 · 2021年
以上内容由遇见数据集搜集并总结生成


