Piyush2512/Dataset_crema_audio
收藏Hugging Face2024-04-23 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/Piyush2512/Dataset_crema_audio
下载链接
链接失效反馈官方服务:
资源简介:
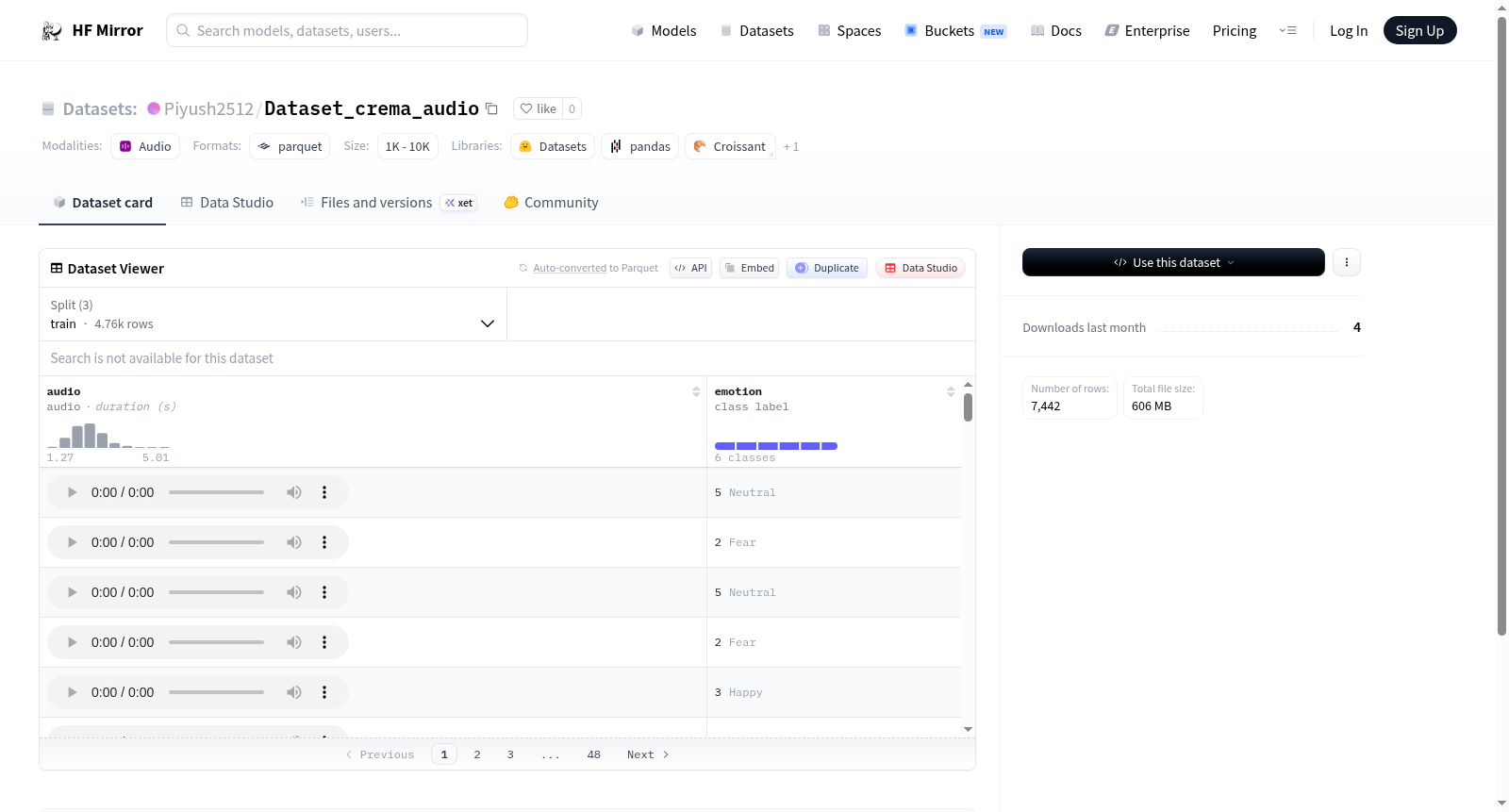
该数据集包含音频数据和对应的情感标签,情感标签包括愤怒、厌恶、恐惧、快乐、悲伤和中性。数据集分为训练集、验证集和测试集,分别包含4762、1191和1489个样本。音频数据的采样率为16000Hz。
该数据集包含音频数据和对应的情感标签,情感标签包括愤怒、厌恶、恐惧、快乐、悲伤和中性。数据集分为训练集、验证集和测试集,分别包含4762、1191和1489个样本。音频数据的采样率为16000Hz。
提供机构:
Piyush2512
原始信息汇总
数据集概述
数据集特征
- 音频特征 (audio)
- 采样率: 16000 Hz
- 情感标签 (emotion)
- 类别名称及编码:
- 0: Anger
- 1: Disgust
- 2: Fear
- 3: Happy
- 4: Sad
- 5: Neutral
- 类别名称及编码:
数据集分割
- 训练集 (train)
- 示例数量: 4762
- 数据大小: 387870723.76602954 字节
- 验证集 (validation)
- 示例数量: 1191
- 数据大小: 97017231.86299059 字节
- 测试集 (test)
- 示例数量: 1489
- 数据大小: 121833787.32297984 字节
数据集大小
- 下载大小: 2016579483 字节
- 数据集实际大小: 606721742.9519999 字节
数据文件配置
- 默认配置 (default)
- 训练集路径: data/train-*
- 测试集路径: data/test-*
- 验证集路径: data/validation-*
搜集汇总
数据集介绍
构建方式
在情感计算与语音分析领域,数据集的构建需兼顾多样性与真实性。该数据集通过精心设计的录音流程,采集了来自不同年龄、性别与文化背景的参与者朗读特定文本的语音样本。每个样本均经过专业标注,依据六种基本情感类别进行人工分类,确保了情感标签的准确性与一致性。数据集的划分遵循标准机器学习实践,将原始音频数据按比例分配为训练集、验证集与测试集,为模型训练与评估提供了结构化基础。
特点
该数据集的核心特征在于其高质量的音频数据与精细的情感标注。所有音频样本均以16kHz采样率存储,保证了语音信号的清晰度与可处理性。情感标签涵盖了愤怒、厌恶、恐惧、快乐、悲伤与中性六种基本情绪,反映了人类情感的广泛谱系。数据集的规模适中,包含七千余个样本,并在划分上保持了平衡,支持稳健的模型训练与验证。这种设计使得数据集适用于情感识别、语音合成及跨模态分析等前沿研究。
使用方法
使用该数据集时,研究者可直接通过HuggingFace平台加载音频与对应情感标签,无需额外预处理。数据集已预分为训练、验证与测试三部分,便于快速构建机器学习流水线。在模型开发中,可利用音频特征提取技术(如梅尔频谱)结合深度学习框架进行情感分类任务。验证集可用于超参数调优,而测试集则提供最终性能评估,确保研究结果的可靠性与可复现性。
背景与挑战
背景概述
在情感计算与人机交互领域,语音情感识别作为关键研究方向,旨在通过声学特征解析人类复杂的情感状态。CREMA-D数据集由美国加州大学圣地亚哥分校的研究团队于2013年创建,聚焦于多模态情感分析,其音频子集收录了91位演员演绎的六种基本情感(愤怒、厌恶、恐惧、快乐、悲伤及中性)的语音样本,采样率为16kHz。该数据集为情感识别模型提供了高质量的标注数据,推动了语音情感分析在心理健康监测、智能客服等场景的应用,成为该领域的重要基准资源之一。
当前挑战
语音情感识别面临的核心挑战在于情感表达的多样性与模糊性,同一情感在不同个体或文化背景下可能呈现迥异的声学特征,导致模型泛化能力受限。在数据集构建过程中,挑战主要源于情感标注的主观性,需要依赖人工标注者的一致性判断,易引入标注偏差;同时,音频样本需在受控环境中录制以降低背景噪声干扰,但这也可能削弱真实场景的适用性。此外,数据平衡性处理与跨文化情感差异的涵盖亦是构建过程中的难点。
常用场景
经典使用场景
在情感计算领域,音频情感识别是理解人类非语言交流的关键环节。CREMA-D数据集以其丰富的语音情感标注,为研究者提供了经典的实验平台。该数据集常用于训练和评估深度学习模型,如卷积神经网络和循环神经网络,以识别六种基本情感状态。通过高保真的音频样本和均衡的情感类别分布,它支持模型在跨说话人和跨语境下的泛化能力测试,成为音频情感分析任务中的基准数据集。
实际应用
在智能交互系统中,情感感知能力是提升用户体验的核心要素。基于CREMA-D数据集训练的模型已广泛应用于客服机器人、心理健康监测和车载语音系统。例如,在远程医疗场景中,系统可通过分析患者语音情感变化辅助诊断抑郁倾向;在教育领域,智能辅导工具能根据学生语音反馈调整教学策略。这些应用显著增强了人机交互的自然性与同理心。
衍生相关工作
围绕CREMA-D数据集,学术界涌现出多项标志性研究。早期工作如WAV2VEC2.0的微调实验验证了自监督学习在情感识别中的有效性;后续研究则探索了多模态融合方法,将音频特征与面部表情数据结合。近年来,基于注意力机制的Transformer架构在该数据集上取得了突破性进展,相关论文已成为情感计算领域的经典参考文献。
以上内容由遇见数据集搜集并总结生成


