WideSeek-R1/WideSeek-R1-train-data
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/WideSeek-R1/WideSeek-R1-train-data
下载链接
链接失效反馈官方服务:
资源简介:
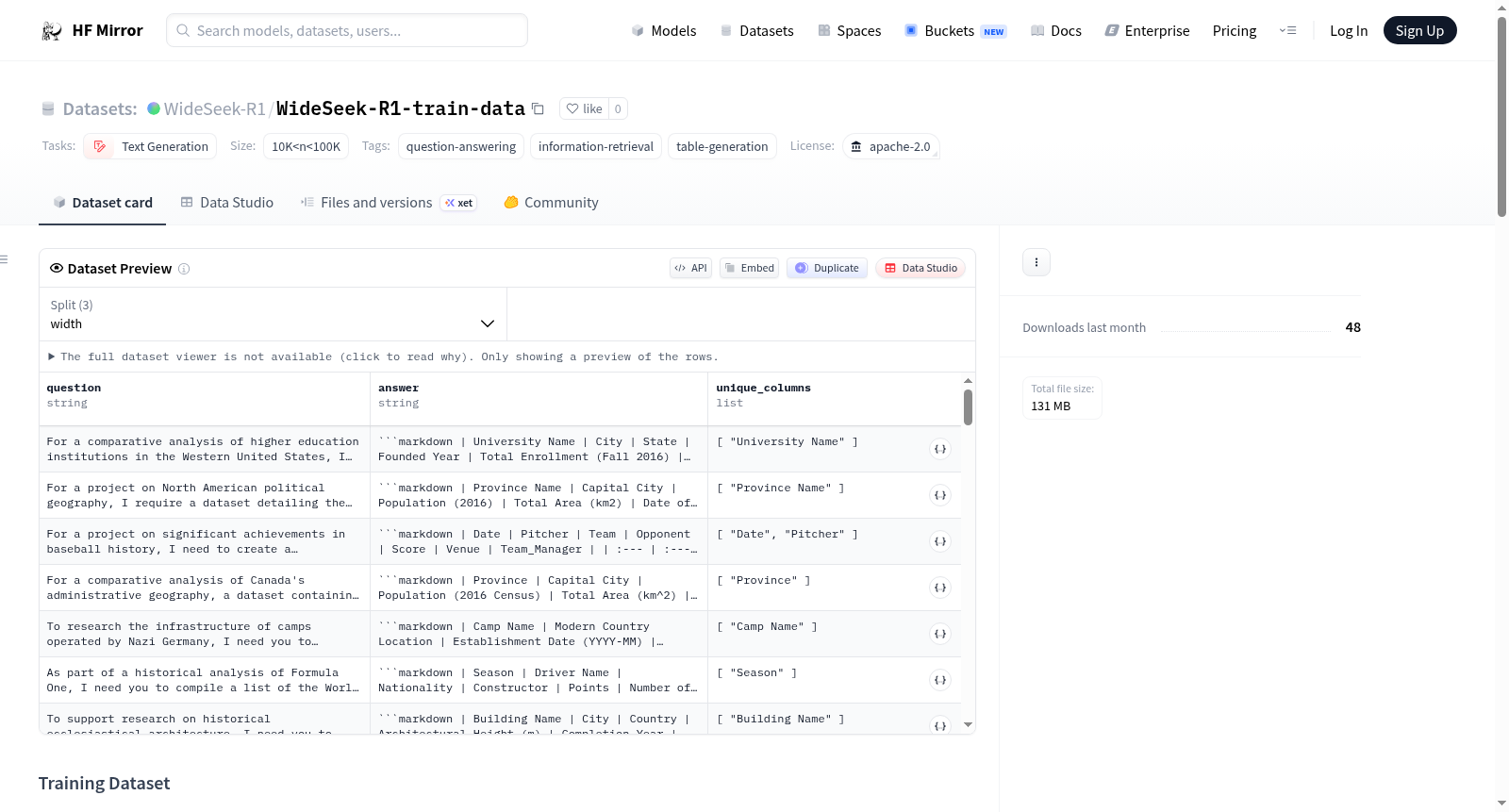
WideSeek-R1训练数据集包含三个子集:width_20k.jsonl、depth_20k.jsonl和hybrid_20k.jsonl,每个子集包含20,000个示例。width_20k.jsonl是专门为WideSearch-style任务设计的,包含20,000个合成的问答实例,旨在评估和增强大型语言模型(LLMs)处理复杂、多面查询的能力。这些查询要求模型将综合信息组织成结构化的Markdown表格。depth_20k.jsonl来源于ASearcher的训练数据,hybrid_20k.jsonl是前两者的平衡混合,作为核心训练集。数据集的结构包括问题、答案和唯一列名。
The WideSeek-R1 training dataset consists of three subsets: width_20k.jsonl, depth_20k.jsonl, and hybrid_20k.jsonl, each containing 20,000 examples. width_20k.jsonl is tailored for WideSearch-style tasks and comprises 20,000 synthetic QA instances designed to evaluate and enhance the capability of Large Language Models (LLMs) in handling complex, multi-faceted queries. These queries require the model to synthesize comprehensive information into structured Markdown tables. depth_20k.jsonl is sourced from ASearchers training data, and hybrid_20k.jsonl is a balanced mixture of the two, serving as the core training set. The dataset structure includes questions, answers, and unique column names.
提供机构:
WideSeek-R1
搜集汇总
数据集介绍
构建方式
WideSeek-R1-train-data数据集由三组各含两万条样本的子集构成,旨在提升大语言模型处理复杂多维度查询的能力。其中,width_20k.jsonl为完全由大语言模型自动合成的数据,通过模拟HybridQA中的广泛主题,生成了要求模型将多属性信息组织为结构化Markdown表格的复杂问答对,无需人工干预。depth_20k.jsonl则源自ASearcher训练数据,专注于深度检索场景。而hybrid_20k.jsonl作为核心训练集,对前两者进行了均衡混合,以兼顾广度与深度任务的学习。所有样本均包含问题、以Markdown表格呈现的标准答案以及用于评估的唯一列标识,确保数据规模与多样性。
特点
该数据集的核心特点在于其问答实例的复杂性与结构化要求。与传统事实型问答不同,WideSeek-R1-train-data的问题覆盖广泛主题,并明确要求模型将信息整合为指定格式的表格,答案表格通常包含10至50行和5至10列,模拟了真实世界中信息综合与检索的复杂性。数据集的统计分布显示,行数中位数约为30,列数中位数约为6,有效反映了不同难度的检索挑战。此外,所有数据均由大语言模型生成,保证了可扩展性与多样性,同时避免了人工标注的偏差,为评估模型在结构化输出与多属性组织方面的能力提供了独特的基准。
使用方法
使用WideSeek-R1-train-data数据集时,用户可根据任务需求选择不同子集:width_20k适合训练模型进行宽范围信息搜索与表格化综合,depth_20k适用于深度事实检索场景,而hybrid_20k则作为平衡后的核心训练集,推荐用于主要实验。数据以JSONL格式提供,每条记录包含question、answer及unique_columns字段,可直接用于大语言模型的监督微调。在训练或评估中,模型需根据问题生成对应的Markdown表格,并利用unique_columns作为主键进行精确匹配评估,以实现对模型结构化输出能力的检验。
背景与挑战
背景概述
WideSeek-R1-train-data数据集由研究团队于近期构建,旨在增强大语言模型处理复杂多维度查询的效能。其核心研究问题聚焦于突破传统问答基准对单一事实检索或短答案提取的依赖,推动模型向综合信息结构化呈现演进。该数据集通过完全由语言模型生成的合成数据,在规模与多样性上展现出显著优势,为信息检索与表格生成领域提供了新颖的评估基准,有望推动相关研究方向的发展。
当前挑战
该数据集所解决的领域问题在于,现有问答系统多局限于简单事实检索,难以应对需要多属性整合与结构化输出的复杂查询,如将分散信息综合为规范表格。构建过程中,挑战在于设计能够引导模型生成符合格式约束的Markdown表格的查询,并确保生成的表格在行数(中位数30行)与列数(中位数6列)上模拟真实检索场景的复杂性。此外,完全依赖语言模型生成数据,需平衡合成数据的准确性与多样性,避免引入偏差或噪声,这对数据质量控制提出了高要求。
常用场景
经典使用场景
WideSeek-R1-train-data数据集专为提升大语言模型在复杂多属性查询下的结构化信息整合能力而设计,其核心使用场景在于训练模型将分散的事实性知识系统地组织为Markdown格式的表格。与传统的简单问答任务不同,该数据集要求模型面对涵盖地理、历史、科学等多领域的综合性提问,能够准确识别并提取相关属性,进而生成包含10至50行、5至10列的规范表格,这一过程模拟了真实世界中信息检索与知识汇编的复杂需求。
解决学术问题
该数据集巧妙地解决了当前大语言模型在细粒度多跳推理与结构化输出对齐方面的学术难题。传统基准测试多聚焦于单轮事实抽取或短文本回答,而WideSeek-R1-train-data通过构造需要跨维度信息综合的查询,迫使模型从理解复杂指令、遵循严格格式约束到生成语义准确且结构完整的表格,全方位评估并强化了模型的语义解析、信息检索与序列生成能力的协同作用,推动了多属性知识组织与表格生成领域的研究进展。
衍生相关工作
该数据集的发布催生了多项富有影响力的后续研究,一方面激励了针对复杂表格生成任务的专用评估指标的开发,以更精准地度量表格的格式正确性与语义保真度。另一方面,促使研究者探索将宽度搜索(WideSearch)与深度推理(Deep Reasoning)相结合的混合模型架构,例如在数据集中提出的宽度(width)、深度(depth)及混合(hybrid)子集基础上构建的多阶段训练策略,有效平衡了信息覆盖广度与答案精确性,为下一代智能问答系统的范式演进提供了重要参考。
以上内容由遇见数据集搜集并总结生成


