Swag
收藏arXiv2018-08-16 更新2024-06-21 收录
下载链接:
https://rowanzellers.com/swag
下载链接
链接失效反馈官方服务:
资源简介:
Swag是一个大规模的对抗性数据集,用于基于常识的推理任务。该数据集由华盛顿大学和艾伦人工智能研究所创建,包含113,000个多选题,覆盖了广泛的基于情境的问题。数据集通过新颖的对抗性过滤(AF)方法构建,旨在减少注释工件和人类偏见,确保数据集的质量和多样性。Swag数据集的应用领域包括自然语言推理和常识推理,旨在解决模型在理解日常物理情境中的挑战,如对象的可用性和框架语义。
Swag is a large-scale adversarial dataset for commonsense-based reasoning tasks. It was created by the University of Washington and the Allen Institute for Artificial Intelligence, and contains 113,000 multiple-choice questions covering a wide range of situation-based problems. The dataset is constructed via a novel adversarial filtering (AF) method, which aims to reduce annotation artifacts and human biases to ensure the quality and diversity of the dataset. The Swag dataset has applications in natural language reasoning and commonsense reasoning, and is designed to address the challenges that models face when understanding everyday physical scenarios, such as object affordances and frame semantics.
提供机构:
保罗·G·艾伦计算机科学与工程学院,华盛顿大学 艾伦人工智能研究所
创建时间:
2018-08-16
搜集汇总
数据集介绍
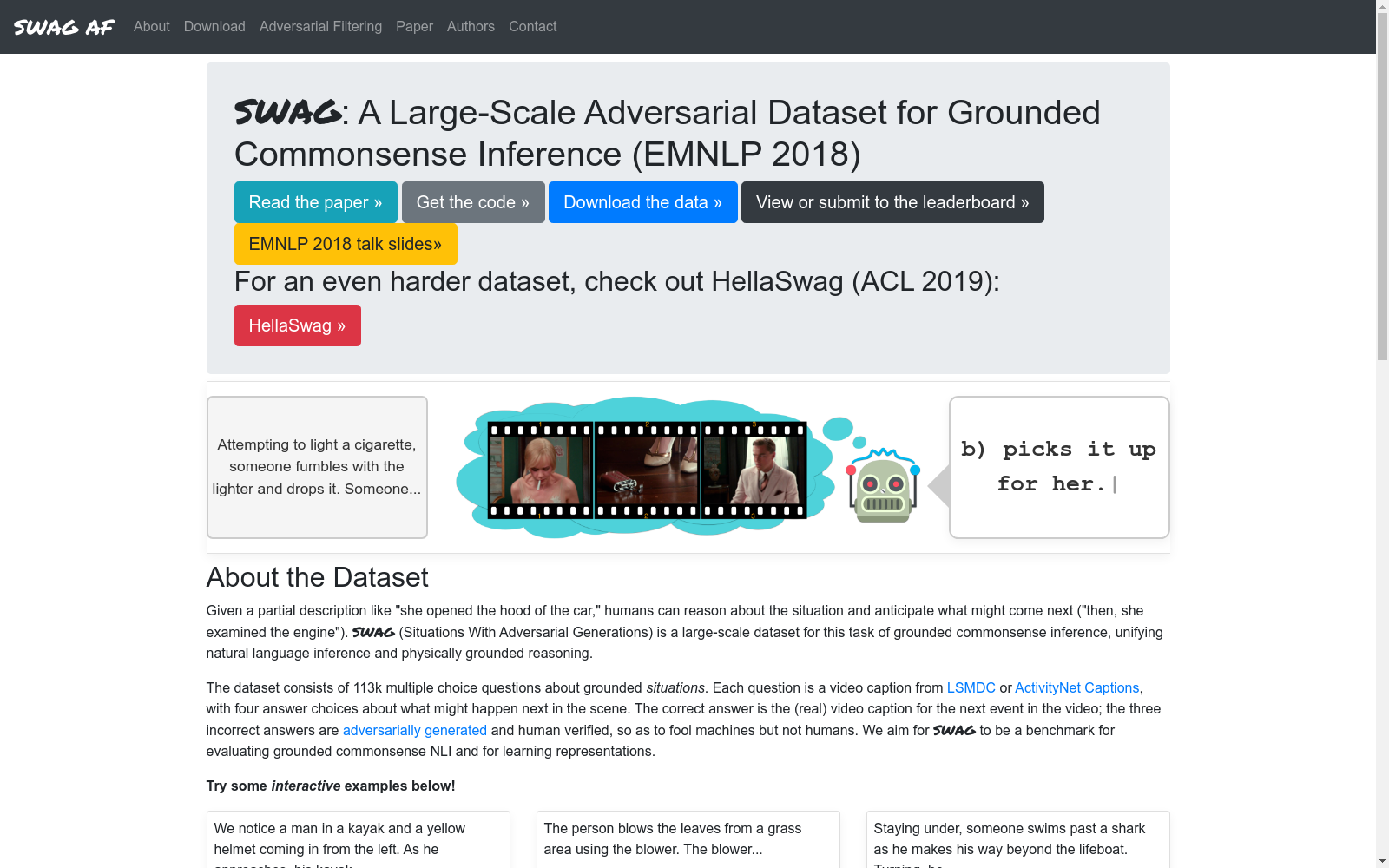
构建方式
Swag数据集通过从ActivityNet Captions和Large Scale Movie Description Challenge (LSMDC)中提取连续视频字幕对来构建。每个字幕对被分割为名词短语和动词短语,并使用预训练的语言模型生成大量可能的负例(即不符合常识的句子结尾)。这些负例通过对抗过滤(Adversarial Filtering, AF)进行筛选,以确保它们在风格上与真实结尾相似,从而减少注释偏差。最终,这些筛选后的负例由众包工作者进行验证,以确保数据质量。
特点
Swag数据集包含113k个多选题,涵盖了广泛的物理情境,要求模型进行基于常识的推理。其特点在于通过对抗过滤技术减少了注释偏差,使得数据集更具挑战性。此外,Swag数据集的多样性和大规模使其成为自然语言推理和常识推理研究的重要资源。
使用方法
Swag数据集适用于训练和评估自然语言推理(NLI)和常识推理模型。模型需要根据给定的上下文和名词短语,从四个可能的动词短语中选择最合适的结尾。研究者可以使用该数据集来开发和测试能够处理复杂物理情境和常识推理的模型,并评估其在人类水平上的表现。
背景与挑战
背景概述
Swag数据集由华盛顿大学和艾伦人工智能研究所的研究团队于2018年创建,旨在解决基于常识推理的自然语言推理任务。该数据集的核心研究问题是如何从给定的上下文中推断出最可能的后续事件,结合了自然语言推理与常识推理的双重挑战。Swag数据集包含了113,000个多选题,涵盖了丰富的情境,主要来源于视频字幕数据。通过引入对抗性过滤(Adversarial Filtering, AF)方法,Swag数据集有效减少了传统数据集中常见的标注偏差和风格化模式,提升了数据集的多样性和鲁棒性,为自然语言推理和常识推理领域的研究提供了新的基准。
当前挑战
Swag数据集面临的挑战主要集中在两个方面:一是如何构建一个能够有效减少标注偏差和风格化模式的数据集。传统的数据集往往存在标注偏差,导致模型在训练时过度依赖这些偏差,从而在实际应用中表现不佳。Swag通过对抗性过滤方法,迭代训练风格分类器,并使用它们来过滤数据,从而构建了一个去偏的数据集。二是如何设计一个能够应对复杂情境推理的模型。Swag数据集要求模型不仅能够进行简单的语言推理,还需要具备对物理世界和日常情境的深刻理解,这对现有的自然语言推理模型提出了更高的要求。实验表明,尽管人类能够以高准确率(88%)解决这些问题,但现有的竞争模型在这一任务上仍表现不佳,显示出该数据集在推动模型发展方面的巨大潜力。
常用场景
经典使用场景
Swag数据集的经典使用场景主要集中在基于常识推理的自然语言推理任务中。该数据集通过提供大量多选题,要求模型根据给定的上下文预测最可能的后续事件。例如,给定一个描述如“她打开了汽车的引擎盖”,模型需要从多个选项中选择最合理的下一步动作,如“她检查了引擎”。这种任务不仅需要语言理解能力,还需要对日常物理情境的常识推理。
实际应用
Swag数据集的实际应用场景广泛,特别是在需要常识推理的智能系统中。例如,在智能对话系统中,模型可以根据用户的当前行为预测其下一步可能的动作,从而提供更自然的交互体验。此外,Swag还可以用于视频内容理解,帮助系统预测视频中事件的后续发展,提升视频摘要和推荐的准确性。在教育领域,Swag也可以用于开发智能辅导系统,帮助学生理解复杂的情境推理问题。
衍生相关工作
Swag数据集的提出激发了许多相关研究工作,特别是在自然语言推理和常识推理领域。例如,基于Swag的对抗性过滤方法被应用于其他数据集的构建,以减少标注偏差。此外,Swag的成功也推动了对更复杂常识推理任务的研究,如基于多模态数据的推理(结合图像和文本)。许多研究者还尝试改进现有的NLI模型,使其能够更好地处理Swag中的复杂情境推理问题,从而提升模型在实际应用中的表现。
以上内容由遇见数据集搜集并总结生成


