TinyStoriesAdv-zh
收藏Hugging Face2024-08-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/fzmnm/TinyStoriesAdv-zh
下载链接
链接失效反馈官方服务:
资源简介:
TinyStoriesAdv是一个针对小学知识水平的大语言模型训练语料库,包含多种子数据集,旨在提升模型的不同能力,如事实性知识、元认知、思维链、阅读理解、逻辑推理等。数据集通过创新的提示词生成,涵盖了小学生的日常常识、小学百科全书以及小学语文课程内容,支持多种交互模态。
TinyStoriesAdv is a training corpus for large language models (LLMs) tailored to primary school knowledge levels. It comprises multiple sub-datasets, aiming to enhance various capabilities of models, including factual knowledge, metacognition, chain-of-thought, reading comprehension, logical reasoning, and more. The corpus is generated through innovative prompt engineering, covering daily common sense for primary school students, primary school encyclopedic content, and Chinese language curriculum materials for primary grades, and supports multiple interaction modalities.
创建时间:
2024-08-01
原始信息汇总
TinyStoriesAdv 数据集概述
数据集描述
- 关键词: 小学生知识水平, 大语言模型, 小语言模型, 迷你语言模型, 超小语言模型, llm, slm
- 数据集类型: 大语言模型训练语料库
- 数据集规模: 约1B tokens
- 知识水平: 小学知识水平
- 数据集组成: 多个子数据集的集合,旨在提升模型的不同能力(事实性知识、元认知、思维链、阅读理解RAG、逻辑推理等)
数据集用途
- 替代品: 可作为TinyStories数据集的替代品
- 目标用户: 对人工智能感兴趣的爱好者和学生
- 模型参数: 支持100M参数规模下的大语言模型训练
- 训练时间:
- 100M参数模型:7小时A100 GPU时间
- 2080显卡:不到一周时间
合成训练数据的构建方法论
- encyclopedias: 使用GPT4o生成的适合幼儿园、小学生理解能力的百科全书
- tinystories_adv:
- 以encyclopedias的主题列表作为关键词,使用GPT4o-mini生成的小故事
- 插入了GPT4o生成的百科词条,以弥补GPT4o-mini的不足
- 生成不同文体(散文、议论文、记叙文等)和不同要求(负面结局、对话、冲突等)
- tinystories_adv/association_generation: 使用词条和联想词生成小故事,避免不相关概念的组合
- tinystories_adv/cot_problem_solving: 使用思维链解释行动逻辑,提高模型的Chain of Thought能力
- tinystories_adv/story_merge: 融合多个参考文本生成新故事,提高生成故事的复杂度和语境多样性
- tinystories_adv/style_reference_generation: 使用语文课本中的高质量语料进行仿写,提高模型的文采
- tinystories_adv/tuple_generation: 使用主谓宾随机组合生成小故事,提供基本常识覆盖
- chinese_class: 模拟小学语文课,提升模型的多模态能力和元认知能力
- math: 模拟小学数学课,包括四则运算练习题
- tinygames: 模拟小朋友玩游戏的过程,强化模型的认知能力
- quizs: 生成选择题,对模型进行“应试教育”
- tinybooks: 将经典名著转述成适合小学生阅读的白话版本
注意事项
- 数据集使用ChatGPT4o和ChatGPT4o-mini合成,应遵守OpenAI的规则
- 数据集未进行人工和机器的安全、幻觉、事实性知识错误、逻辑错误的审核
搜集汇总
数据集介绍
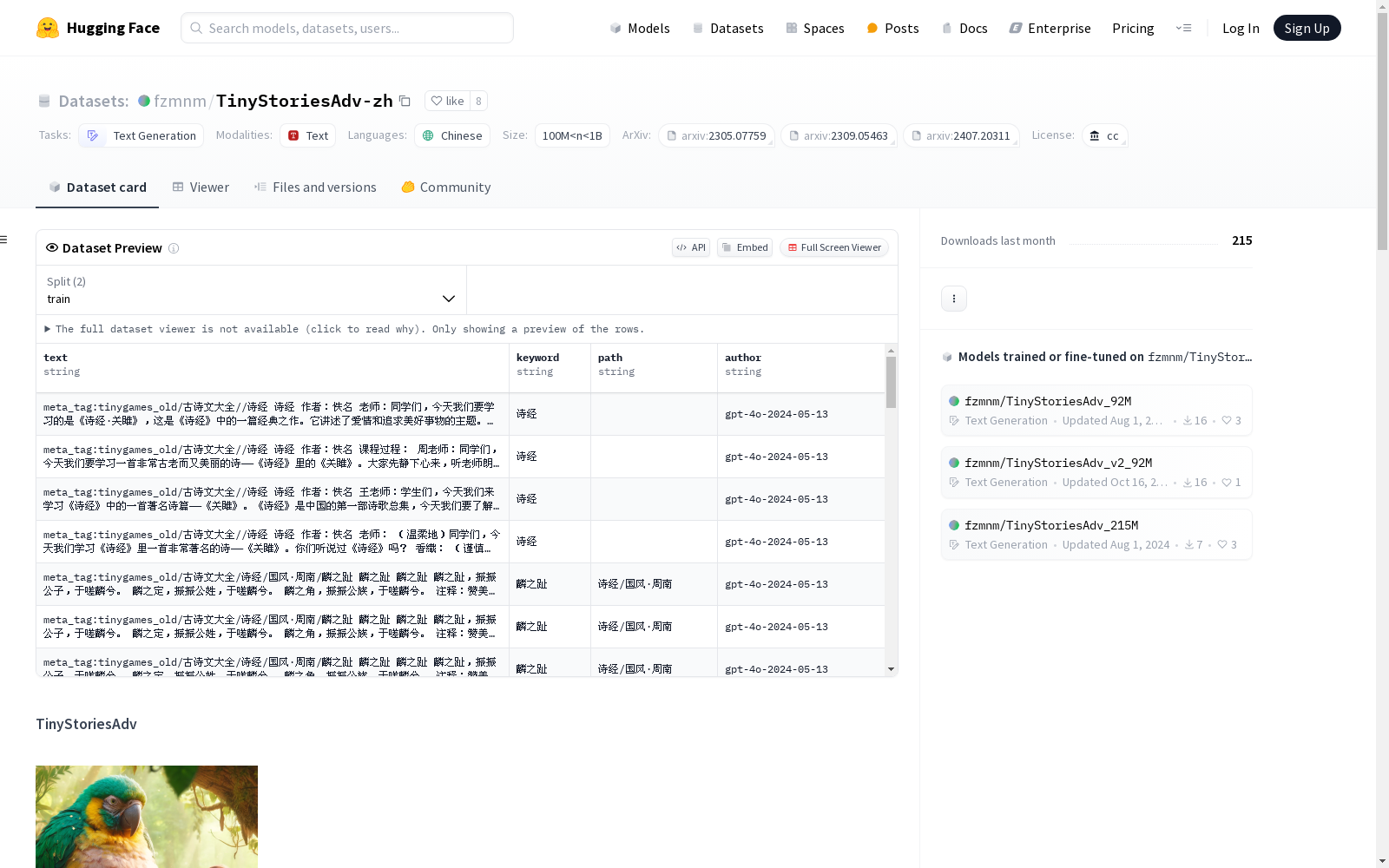
构建方式
TinyStoriesAdv-zh数据集的构建方法基于多样化的子数据集生成策略。通过使用GPT-4o和GPT-4o-mini模型,结合创新的提示词生成技术,创建了涵盖百科全书、故事生成、问题解答、数学练习和游戏模拟等多个领域的子数据集。每个子数据集都经过精心设计,以增强模型在事实性知识、元认知、思维链、阅读理解及逻辑推理等方面的能力。此外,数据集中还引入了meta_tag机制,以帮助模型区分和优先处理高质量数据。
特点
TinyStoriesAdv-zh数据集的特点在于其广泛覆盖小学生知识水平的内容,包括日常常识、百科全书和语文课程等。数据集通过多样化的文体和语境设计,如散文、议论文、记叙文等,增强了文本的多模态性。此外,数据集特别强调了对模型认知能力的强化,如对象持久性、理论思维、上下文学习和自我指导等,使其在小型语言模型训练中表现出色。
使用方法
TinyStoriesAdv-zh数据集适用于训练和评估小型至中型语言模型,特别是在小学生知识水平上的应用。用户可以通过Huggingface平台获取数据集,并利用提供的模型(如92M和215M参数模型)进行训练。数据集支持多种交互模态,包括阅读理解、问题回答和故事补全等,适合用于教育技术、语言模型研究和人工智能入门教学。训练过程对计算资源的需求相对较低,使得个人研究者和教育机构都能轻松接入。
背景与挑战
背景概述
TinyStoriesAdv-zh数据集是一个专为小学生知识水平设计的大语言模型训练语料库,由研究人员fzmnm于2024年创建。该数据集受到TinyStories和Phi2等论文的启发,旨在通过多样化的子数据集提升模型在事实性知识、元认知、思维链、阅读理解及逻辑推理等方面的能力。数据集涵盖了小学生的日常常识、百科全书内容及语文课程,支持多种交互模态,如阅读理解与问题回答。其目标是为人工智能爱好者和学生提供一个入门级的大模型训练资源,展示即便在100M参数规模下,也能实现基本的小学生常识问答。
当前挑战
TinyStoriesAdv-zh数据集在构建过程中面临多重挑战。首先,生成高质量且多样化的训练数据需要克服模型幻觉问题,尤其是在使用较小规模的GPT4o-mini生成文本时,需通过插入百科词条等方式增强事实性知识。其次,数据集的多样性和针对性要求生成不同文体和语境的故事,增加了数据生成的复杂性。此外,数据集未进行人工和机器的安全、幻觉及逻辑错误审核,可能导致模型训练时引入噪声。最后,如何在有限的计算资源下高效训练模型,尤其是在游戏显卡等非专业硬件上实现快速训练,也是该数据集面临的重要技术挑战。
常用场景
经典使用场景
TinyStoriesAdv-zh数据集主要用于训练和评估小型语言模型,特别是在小学生知识水平范围内的文本生成任务。该数据集通过多样化的子数据集,如百科全书、故事生成、数学问题和语文课程等,为模型提供了丰富的训练素材,使其能够在100M参数规模下实现基本的小学生常识问答和阅读理解任务。
衍生相关工作
TinyStoriesAdv-zh数据集的衍生工作包括基于该数据集训练的小型语言模型,如92M和215M参数的模型。这些模型在HuggingFace平台上公开,供研究者和开发者使用。此外,该数据集还启发了更多关于小型语言模型在教育领域应用的研究,推动了AI在教育科技中的创新应用。
数据集最近研究
最新研究方向
近年来,随着大语言模型(LLM)和小语言模型(SLM)的快速发展,TinyStoriesAdv-zh数据集在自然语言处理领域引起了广泛关注。该数据集通过整合多种子数据集,如百科全书、故事生成、数学问题等,旨在提升模型在事实性知识、元认知、思维链、阅读理解等方面的能力。特别是在小学知识水平的语言模型训练中,TinyStoriesAdv-zh通过创新的提示词生成方法,增强了文本的多样性和针对性。这一研究方向不仅推动了迷你语言模型在基础教育领域的应用,还为模型的多模态能力和逻辑推理能力提供了新的训练范式。此外,该数据集在模型训练效率和可玩性上的优势,使其成为研究者和爱好者探索大语言模型潜力的重要工具。
以上内容由遇见数据集搜集并总结生成


