GenMath-0
收藏Hugging Face2024-12-26 更新2024-12-27 收录
下载链接:
https://huggingface.co/datasets/Gusarich/GenMath-0
下载链接
链接失效反馈官方服务:
资源简介:
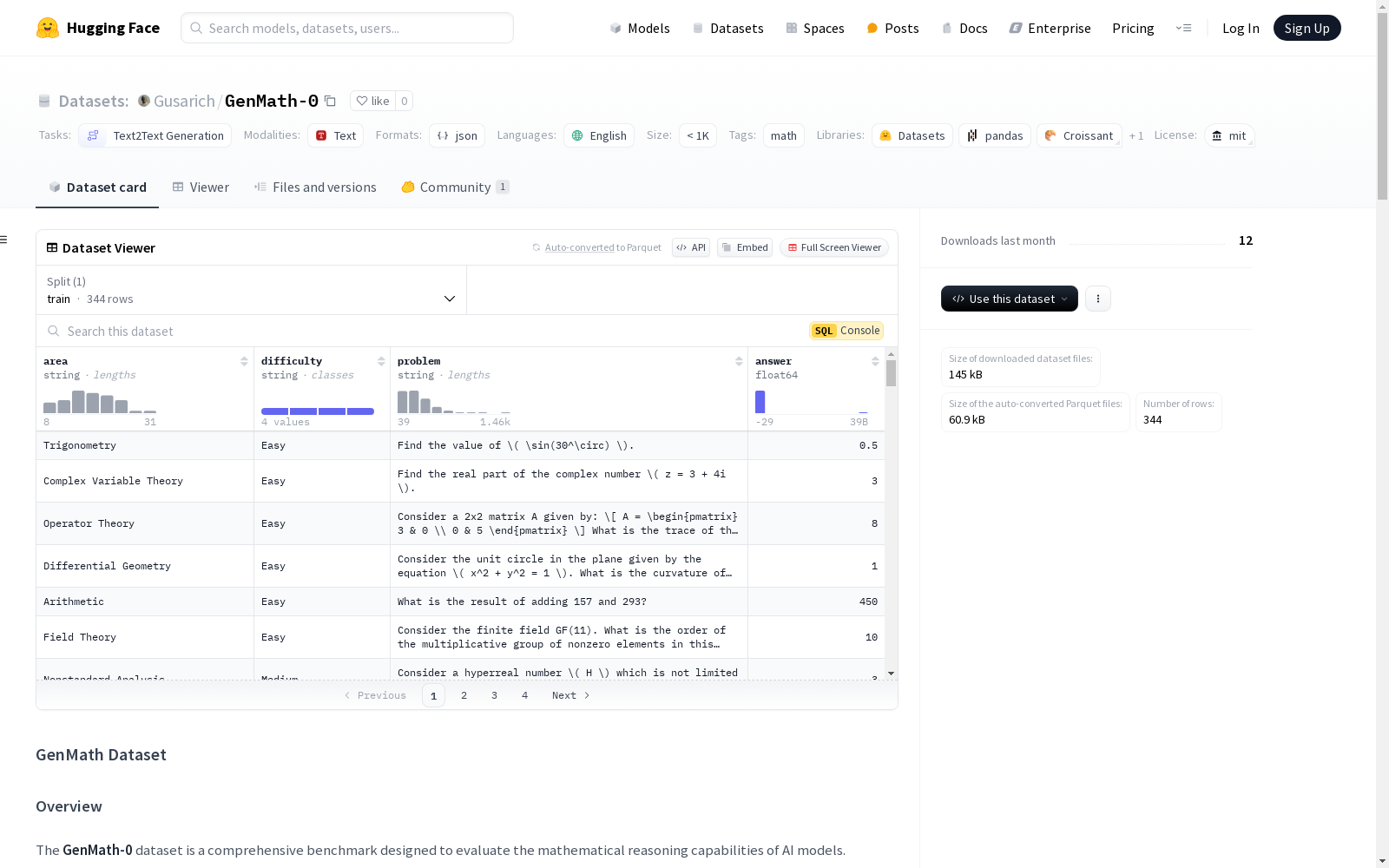
GenMath数据集是一个全面的基准测试集,旨在评估AI模型的数学推理能力。数据集包含344个问题,涵盖86个不同的数学领域,并按难度分为四个等级:简单、中等、困难和极端。每个问题都有经过验证的数值答案,确保其准确性和可靠性。数据集以JSON格式存储,每个问题包含数学领域、难度、问题描述和答案等字段。该数据集的设计目标是测试模型在从基础到高级数学主题的广泛范围内的推理能力。
The GenMath dataset is a comprehensive benchmark set designed to evaluate the mathematical reasoning capabilities of AI models. It contains 344 questions spanning 86 distinct mathematical domains, and is categorized into four difficulty levels: Easy, Medium, Hard, and Extreme. Each question is equipped with a validated numerical answer to ensure its accuracy and reliability. The dataset is stored in JSON format, with each question including fields such as mathematical domain, difficulty level, problem description and answer. The primary design goal of this dataset is to test the reasoning abilities of models across a broad spectrum of mathematical topics ranging from basic to advanced levels.
创建时间:
2024-12-26
搜集汇总
数据集介绍
构建方式
GenMath-0数据集通过先进的AI模型合成生成,确保了问题的多样性和挑战性。该数据集涵盖了86个不同的数学领域,每个领域包含4个问题,分别对应4个难度级别:简单、中等、困难和极端。每个问题的答案通过o1-mini模型的四次独立运行进行验证,确保了答案的准确性。这种构建方式不仅保证了数据集的广泛覆盖,还通过难度分级和验证机制提升了其科学性和可靠性。
使用方法
GenMath-0数据集可通过Hugging Face的Datasets库轻松加载。用户只需使用`load_dataset`函数即可加载数据集,并访问其中的问题及其对应的答案。每个问题以JSON格式存储,包含数学领域、难度级别、LaTeX格式的问题描述和数值答案。这种便捷的加载方式和清晰的数据结构使得GenMath-0数据集能够广泛应用于AI模型的数学推理能力评估和研究中。
背景与挑战
背景概述
GenMath-0数据集由Daniil Sedov于2024年发布,旨在评估人工智能模型在数学推理方面的能力。该数据集通过先进的AI模型生成,涵盖了86个不同的数学领域,确保问题的多样性和挑战性。GenMath-0的创建标志着数学推理评估领域的一个重要里程碑,其广泛的应用范围从基础数学到高级数学问题,为研究者提供了一个全面的基准测试工具。该数据集的结构化设计,包括四个难度级别,使得它能够系统地揭示模型在处理复杂数学问题时的表现。
当前挑战
GenMath-0数据集在构建和应用过程中面临多重挑战。首先,生成涵盖86个数学领域的多样化问题集,需要确保每个问题的准确性和代表性,这对数据集的构建提出了高要求。其次,验证每个问题的答案需要依赖多个独立运行的AI模型,这一过程不仅耗时,还需确保结果的一致性。此外,尽管数据集已经涵盖了广泛的数学领域,但随着数学研究的不断进展,如何持续更新和扩展数据集以保持其相关性和挑战性,也是一个亟待解决的问题。最后,尽管数据集已经展示了不同模型在解决数学问题上的表现差异,但如何进一步提升模型的数学推理能力,仍是一个重要的研究方向。
常用场景
经典使用场景
GenMath-0数据集在数学推理领域具有广泛的应用,尤其是在评估AI模型的数学问题解决能力方面。该数据集通过涵盖86个不同的数学领域,提供了从基础到高级的多样化问题,使得研究者能够全面测试模型在不同难度和主题下的表现。其经典使用场景包括数学推理模型的训练与评估,特别是在非交换几何、解析数论等复杂数学领域中的应用。
解决学术问题
GenMath-0数据集解决了AI模型在数学推理能力评估中的关键问题。通过提供344个经过验证的数学问题,该数据集能够有效测试模型在不同难度和数学领域中的表现。其系统化的难度分级和广泛的数学主题覆盖,使得研究者能够深入分析模型在处理复杂数学问题时的能力,从而推动数学推理AI技术的发展。
实际应用
在实际应用中,GenMath-0数据集被广泛用于教育和研究领域。教育机构可以利用该数据集开发智能辅导系统,帮助学生提升数学问题解决能力。研究机构则可以通过该数据集评估和改进AI模型的数学推理能力,推动智能系统在数学相关领域的应用,如自动化数学证明和复杂数学问题的求解。
数据集最近研究
最新研究方向
在数学推理领域,GenMath-0数据集作为一项综合性基准,正引领着AI模型在数学问题解决能力评估的前沿研究。该数据集通过涵盖86个不同数学领域的344个问题,系统地测试了模型从基础到高级数学推理的能力。近期研究聚焦于如何利用生成式AI技术进一步提升问题的多样性和复杂性,同时探索更先进的验证机制以确保答案的准确性。此外,研究者们正致力于扩展数据集,纳入更多数学领域和问题类型,以应对不断变化的数学挑战。这些努力不仅推动了AI模型在数学推理方面的性能提升,也为跨学科研究提供了新的视角和工具。
以上内容由遇见数据集搜集并总结生成


