万家数科数据罗盘
收藏上海数据交易所2024-06-13 更新2026-03-21 收录
下载链接:
https://nidts.chinadep.com/reg-hall/product-detail?id=3108
下载链接
链接失效反馈官方服务:
资源简介:
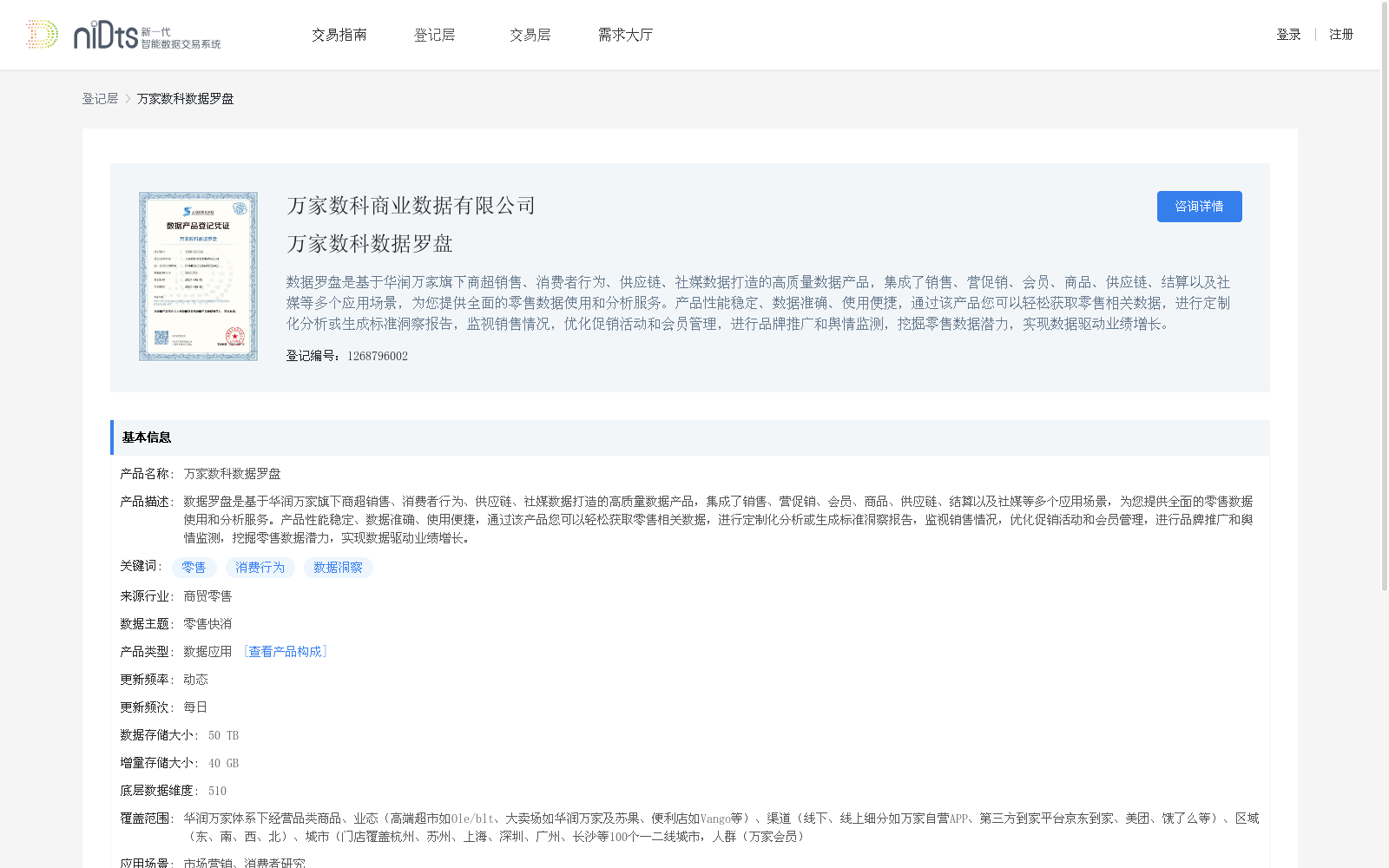
数据罗盘是基于华润万家旗下商超销售、消费者行为、供应链、社媒数据打造的高质量数据产品,集成了销售、营促销、会员、商品、供应链、结算以及社媒等多个应用场景,为您提供全面的零售数据使用和分析服务。产品性能稳定、数据准确、使用便捷,通过该产品您可以轻松获取零售相关数据,进行定制化分析或生成标准洞察报告,监视销售情况,优化促销活动和会员管理,进行品牌推广和舆情监测,挖掘零售数据潜力,实现数据驱动业绩增长。
Data Compass is a high-quality data product built upon the sales, consumer behavior, supply chain and social media data of CR Vanguard's supermarkets and hypermarkets. It integrates multiple application scenarios including sales, sales promotion, membership management, merchandise, supply chain, settlement and social media, providing users with comprehensive retail data utilization and analysis services. Featuring stable performance, accurate data and convenient operation, the product enables users to easily acquire retail-related data, carry out customized analysis or generate standard insight reports, monitor sales status, optimize promotional activities and membership management, conduct brand promotion and public opinion monitoring, tap the potential of retail data, and achieve data-driven business growth.
提供机构:
万家数科商业数据有限公司
创建时间:
2024-06-13
搜集汇总
数据集介绍
背景与挑战
背景概述
万家数科数据罗盘是一个基于华润万家商超数据的零售数据产品,集成了销售、消费者行为、供应链和社媒数据,覆盖多个应用场景,旨在通过数据驱动实现业绩增长。数据集每日更新,覆盖全国100个一二线城市,适用于市场营销和消费者研究。
以上内容由遇见数据集搜集并总结生成


