文本关键词识别训练数据
收藏浙江省数据知识产权登记平台2023-12-01 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/15967
下载链接
链接失效反馈官方服务:
资源简介:
应用概述
关键词识别任务指的是从给定的文本中识别和提取关键词或短语。这些关键词或短语可以反映文本的主题、意图或重要内容。这种技术在搜索引擎、内容推荐、广告定向、语音助手等领域中都有应用。
数据适用条件:对于特定的语言和领域,可能需要专门的模型或适应性训练。
应用范围
1、搜索引擎优化:提取网页或文章中的关键词,优化搜索排名。
2、内容推荐系统:根据用户阅读、观看或听取的内容中的关键词为用户推荐相关内容。
3、广告定向:根据用户浏览内容的关键词来展示相关的广告。
4、语音助手和智能对话:从用户的语音指令中提取关键词,执行相关操作或返回相关信息。
5、文档管理和归档:通过关键词识别和标签,帮助用户分类和检索文档。
6、市场和社交媒体分析:从大量的评论或帖子中提取关键词,了解公众的关注点和情感倾向。
使用对象
1、网站和应用开发者
2、内容创作者和出版商
3、广告商和市场营销人员
4、企业和研究机构
5、社交媒体平台和分析师基本定义:
关键词识别算法是一种特定的信息检索技术,旨在从文本或音频数据中自动识别和提取关键词或关键短语。这些关键词提供了对内容主题或核心观点的快速理解,常常作为内容的元数据进行存储和使用。
核心组件:
1. 预处理:包括去除停用词、标点符号、数字,进行词干提取或词形还原,等等。
2. 特征提取:利用技术如TF-IDF、词频统计、Word2Vec等,将文本转换为机器可识别的特征形式。
3. 权重评估:为识别到的潜在关键词分配权重,常常基于其在文档中的出现频率、在整个语料库中的稀有度等。
4. 关键词选择:根据权重选择最具代表性的词汇或短语作为关键词。
优势
高效性:可以快速地从大量文本或音频中提取关键信息。
客观性:基于统计和计算,提供相对客观的关键词。
自动化:减少了手动标记或分类的工作量。
应用建议:
使用关键词识别算法时,建议:
1. 根据实际应用的领域和目的,调整或优化关键词提取的参数和方法。
2. 定期使用新的数据对模型进行更新和优化,以适应语言和表达方式的变化。
3. 在可能的情况下,结合其他文本分析技术(如情感分析、主题建模等)以提供更深入、全面的分析结果。
Application Overview
The keyword recognition task refers to identifying and extracting keywords or phrases from a given text. These keywords or phrases can reflect the topic, intent or important content of the text. This technology is applied in fields such as search engines, content recommendation, advertising targeting, voice assistants, etc.
Data Application Conditions: For specific languages and domains, specialized models or adaptive training may be required.
Scope of Application
1. Search Engine Optimization: Extract keywords from web pages or articles to optimize search rankings.
2. Content Recommendation Systems: Recommend relevant content to users based on keywords in the content they have read, watched or listened to.
3. Advertising Targeting: Display relevant advertisements based on the keywords from users' browsing content.
4. Voice Assistants and Intelligent Dialogue: Extract keywords from users' voice commands to perform relevant operations or return relevant information.
5. Document Management and Archiving: Help users classify and retrieve documents through keyword recognition and tagging.
6. Market and Social Media Analysis: Extract keywords from a large number of comments or posts to understand public concerns and emotional tendencies.
Target Users
1. Website and application developers
2. Content creators and publishers
3. Advertisers and marketing professionals
4. Enterprises and research institutions
5. Social media platforms and analysts
Basic Definition:
Keyword recognition algorithm is a specific information retrieval technology that aims to automatically identify and extract keywords or key phrases from text or audio data. These keywords provide a quick understanding of the content's theme or core viewpoints, and are often stored and used as content metadata.
Core Components:
1. Preprocessing: Including removing stop words, punctuation, numbers, stemming or lemmatization, etc.
2. Feature Extraction: Utilize technologies such as TF-IDF, word frequency statistics, Word2Vec, etc., to convert text into machine-recognizable feature forms.
3. Weight Evaluation: Assign weights to identified potential keywords, often based on their occurrence frequency in the document, their rarity in the entire corpus, etc.
4. Keyword Selection: Select the most representative words or phrases as keywords based on their weights.
Advantages
Efficiency: Can quickly extract key information from a large amount of text or audio.
Objectivity: Based on statistics and calculations, provide relatively objective keywords.
Automation: Reduce the workload of manual labeling or classification.
Application Recommendations:
When using keyword recognition algorithms, it is recommended to:
1. Adjust or optimize the parameters and methods of keyword extraction according to the actual application field and purpose.
2. Regularly update and optimize the model with new data to adapt to changes in language and expression styles.
3. Combine other text analysis technologies (such as sentiment analysis, topic modeling, etc.) when possible to provide more in-depth and comprehensive analysis results.
提供机构:
杭州谦贞数字科技有限公司
创建时间:
2023-10-26
搜集汇总
数据集介绍
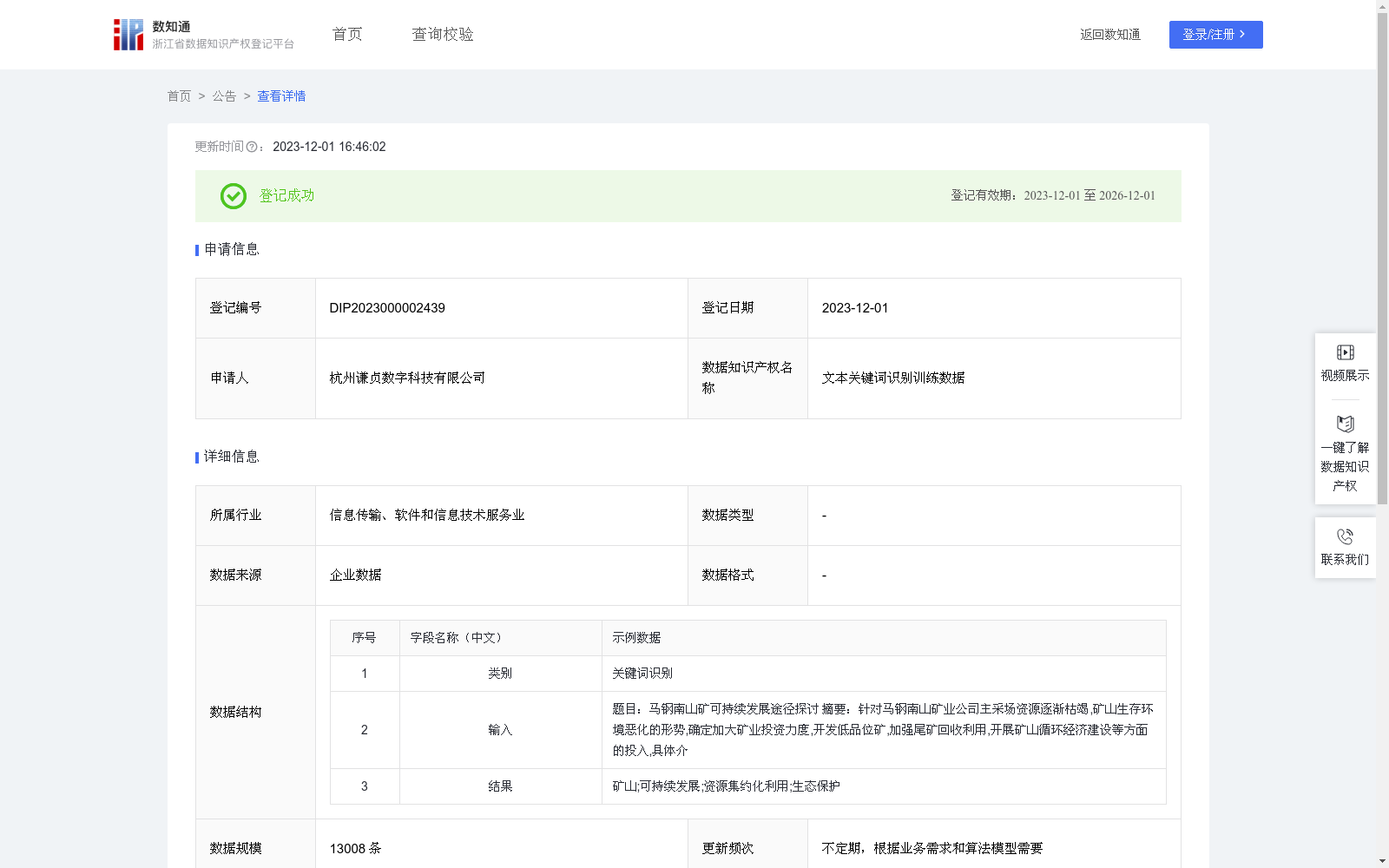
特点
该数据集主要用于文本关键词识别,包含13008条数据,适用于多个应用场景如搜索引擎优化和内容推荐系统。数据由企业提供,更新频次不定,适用于需要关键词提取的多种业务需求。
以上内容由遇见数据集搜集并总结生成


