D-ExpTracker__TEST_L8B__v1
收藏Hugging Face2025-11-21 更新2025-11-22 收录
下载链接:
https://huggingface.co/datasets/TAUR-dev/D-ExpTracker__TEST_L8B__v1
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是用于Skill Factory工作流的简单测试实验,包含了问题、答案、任务配置、任务来源、提示、模型响应等特征,以及对应的训练和测试数据分割。
创建时间:
2025-11-21
原始信息汇总
数据集概述
基本信息
- 数据集名称: Experiment Tracker: TEST_L8B
- 数据集地址: https://huggingface.co/datasets/TAUR-dev/D-ExpTracker__TEST_L8B__v1
- 实验描述: Simple test experiment for Skill Factory workflows
- 开始时间: 2025-11-20T22:57:50.089863
- 总阶段数: 1
配置信息
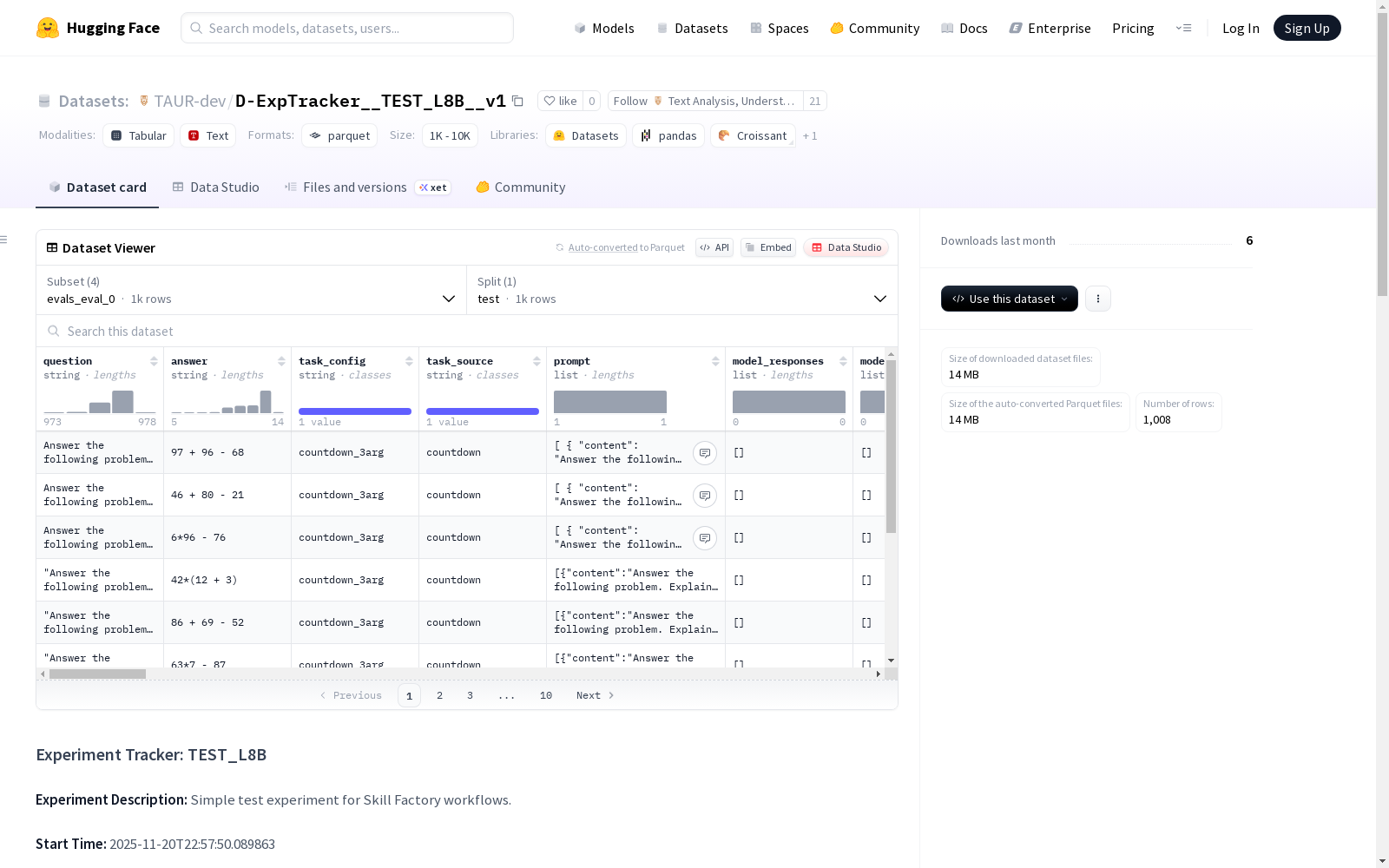
evals_eval_0配置
- 特征字段:
- question: 字符串类型
- answer: 字符串类型
- task_config: 字符串类型
- task_source: 字符串类型
- prompt: 列表类型,包含content和role字段
- model_responses: 空列表
- model_responses__eval_is_correct: 空列表
- all_other_columns: 字符串类型
- original_split: 字符串类型
- metadata: 字符串类型
- model_responses__best_of_n_atags: 字符串列表
- model_responses__best_of_n_atags__finish_reason_length_flags: 布尔列表
- model_responses__best_of_n_atags__length_partial_responses: 字符串列表
- prompt__best_of_n_atags__metadata: 结构体类型,包含api_url、backend、chat_template_applied、generation_params、model_name、prompt等字段
- model_responses__best_of_n_atags__metadata: 结构体类型,包含backend、model_name、n_responses字段
- model_responses__best_of_n_atags__eval_is_correct: 布尔列表
- model_responses__best_of_n_atags__eval_extracted_answers: 字符串列表
- model_responses__best_of_n_atags__eval_extraction_metadata: 字符串类型
- model_responses__best_of_n_atags__eval_evaluation_metadata: 字符串类型
- model_responses__best_of_n_atags__internal_answers__eval_is_correct: 布尔列表的列表
- model_responses__best_of_n_atags__internal_answers__eval_extracted_answers: 字符串列表的列表
- model_responses__best_of_n_atags__internal_answers__eval_extraction_metadata: 字符串类型
- model_responses__best_of_n_atags__internal_answers__eval_evaluation_metadata: 字符串类型
- model_responses__best_of_n_atags__metrics: 结构体类型,包含flips_by、flips_total、num_correct、pass_at_n、percent_correct、total_responses字段
- eval_date: 字符串类型
- split: 字符串类型
- revision_name: 字符串类型
- model_path: 字符串类型
- checkpoint_step: 整型
- stage_name: 字符串类型
- stage_number: 整型
- timestamp: 字符串类型
- eval_repo_id: 字符串类型
- 数据分割:
- test分割: 1000个样本,74,915,934字节
- 下载大小: 13,482,689字节
- 数据集大小: 74,915,934字节
logs__evaluation_eval_0配置
- 特征字段:
- timestamp: 字符串类型
- end_timestamp: 字符串类型
- stage_name: 字符串类型
- stage_number: 整型
- level: 字符串类型
- message: 字符串类型
- stdout_content: 字符串类型
- stderr_content: 字符串类型
- experiment_name: 字符串类型
- elapsed_time_seconds: 浮点型
- stage_complete: 布尔型
- 数据分割:
- train分割: 1个样本,7,316,410字节
- 下载大小: 518,938字节
- 数据集大小: 7,316,410字节
logs__evaluation_eval_rl配置
- 特征字段: 与logs__evaluation_eval_0相同
- 数据分割:
- train分割: 1个样本,3,425字节
- 下载大小: 19,467字节
- 数据集大小: 3,425字节
metadata配置
- 特征字段:
- experiment_name: 字符串类型
- start_time: 字符串类型
- description: 字符串类型
- base_org: 字符串类型
- stage_number: 字符串类型
- stage_type: 字符串类型
- status: 字符串类型
- 数据分割:
- train分割: 6个样本,10,550字节
- 下载大小: 9,452字节
- 数据集大小: 10,550字节
使用方式
可通过datasets库加载特定配置: python from datasets import load_dataset metadata = load_dataset(TAUR-dev/D-ExpTracker__TEST_L8B__v1, experiment_metadata)
搜集汇总
数据集介绍
构建方式
在机器学习实验管理领域,D-ExpTracker__TEST_L8B__v1数据集通过结构化流水线实现全周期追踪。该数据集采用多配置架构,分别记录评估结果、实验日志与元数据,其中评估模块通过标准问答对形式采集模型响应,并集成参数配置、时间戳等实验环境信息。构建过程中采用即时上传机制,确保每个实验阶段完成后自动生成带标注的数据切片,形成完整的实验数据谱系。
特点
该数据集具备多维度的实验追踪特性,其评估配置包含问题-答案对、任务来源及模型生成内容等丰富字段,同时通过嵌套结构保存生成参数与评估指标。实验日志模块完整记录执行时间轴与错误流,元数据配置则提供实验阶段拓扑关系。所有数据均采用标准化字段命名,支持对模型训练、强化学习等不同阶段的横向对比分析,形成自解释的实验数据生态系统。
使用方法
研究者可通过HuggingFace数据集库按需加载特定配置,例如调用evals_eval_0配置获取带标注的评估结果,或访问metadata配置追溯实验演进过程。数据集支持分阶段数据提取,用户可独立获取训练超参数、模型响应质量指标或实验日志等模块。这种模块化设计便于进行实验复现、效果归因分析,以及跨实验的元研究,为机器学习工作流提供可验证的数据支撑。
背景与挑战
背景概述
在人工智能研究领域,实验追踪系统对于确保研究过程的可复现性与透明度具有关键意义。D-ExpTracker__TEST_L8B__v1数据集由TAUR开发团队于2025年创建,作为SkillFactory工作流的测试实验记录载体,其核心使命在于结构化存储机器学习实验全周期数据。该数据集通过整合训练配置、评估结果与元数据,构建了完整的实验溯源链条,为研究社区提供了标准化实验管理范式,显著提升了模型训练过程的可观测性与方法论传承效率。
当前挑战
该数据集致力于解决实验管理领域的数据离散化难题,其核心挑战在于如何实现多模态实验数据(如超参数、评估指标、生成式回答)的统一表征与动态关联。构建过程中需攻克实时数据流同步、异构结构嵌套(如对话提示序列与模型响应评估的层级映射)、以及大规模生成内容的质量标注等关键技术瓶颈,同时需确保实验元数据与具体训练阶段的全链路一致性。
常用场景
经典使用场景
在机器学习实验管理领域,D-ExpTracker__TEST_L8B__v1数据集作为SkillFactory工作流的测试实验载体,其核心应用场景聚焦于记录和监督模型训练全过程。通过结构化存储训练配置、超参数、评估结果及实验日志,该数据集为研究者提供了完整的实验复现框架,特别是在监督微调(SFT)与强化学习(RL)等关键阶段,能够系统追踪模型性能演变轨迹。
解决学术问题
该数据集有效应对了机器学习实验可复现性不足的学术难题。通过标准化记录实验元数据、模型响应评估指标及生成参数配置,解决了传统研究中因实验记录缺失导致的结果验证困难。其内置的评估标注体系(如eval_is_correct字段)为模型能力量化提供基准,显著提升了对比实验的严谨性与结论可靠性。
衍生相关工作
基于该数据集的实验范式,催生了系列标准化评估框架的演进。其提出的最佳响应筛选机制(best_of_n_atags)启发了多轮对话系统的评估标准制定,而结构化元数据记录方式则被后续研究拓展为跨平台实验管理工具。相关方法在模型注册表构建、实验血缘追踪等领域持续产生深远影响。
以上内容由遇见数据集搜集并总结生成


