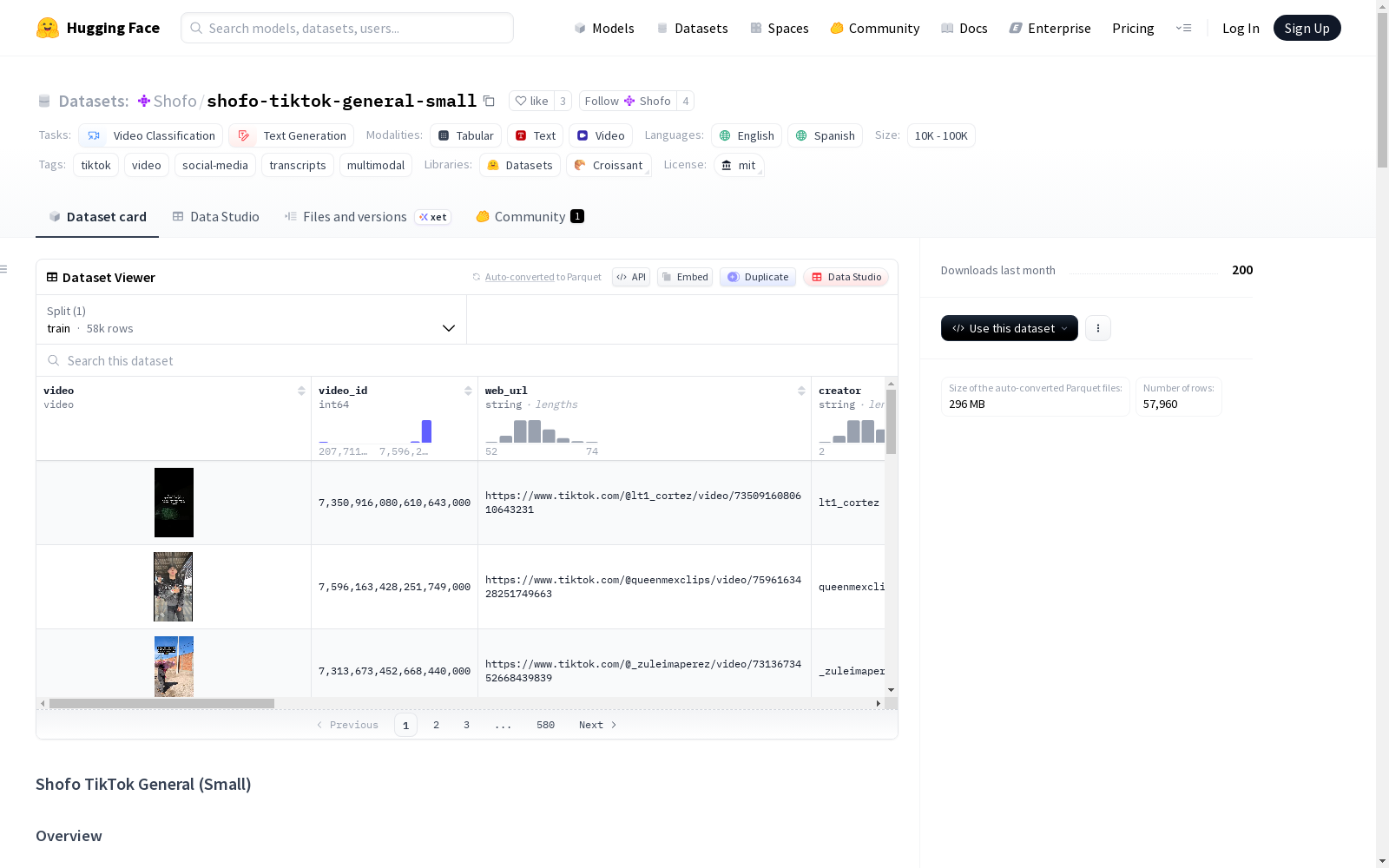
shofo-tiktok-general-small
收藏Shofo TikTok General (Small) 数据集概述
数据集基本信息
- 数据集名称:Shofo TikTok General (Small)
- 许可证:MIT
- 数据规模:包含约50,000个TikTok视频,数据量约500GB
- 模态:多模态(视频 + 文本)
- 语言:英语、西班牙语
- 来源:TikTok
- 任务类别:视频分类、文本生成
- 标签:tiktok, video, social-media, transcripts, multimodal
- 规模类别:10K<n<100K
数据内容与结构
数据集包含TikTok视频及其全面的元数据、转录文本、评论和互动指标。
数据模式
| 列名 | 类型 | 描述 |
|---|---|---|
file_name |
字符串 | 视频文件的相对路径(例如:videos/123.mp4) |
video_id |
字符串 | 唯一的TikTok视频标识符 |
web_url |
字符串 | 视频的TikTok网页URL |
creator |
字符串 | 创作者用户名 |
transcript |
字符串 | 音频转录文本(由自动语音识别生成,可能为空) |
description |
字符串 | 视频标题/描述 |
hashtags |
JSON数组 | 使用的主题标签列表 |
sticker_text |
JSON数组 | 视频中可见的文本叠加/贴纸 |
comments |
JSON数组 | 热门评论及其元数据 |
engagement_metrics |
JSON对象 | 观看次数、点赞数、分享数等互动指标 |
date_posted |
时间戳 | 视频最初发布时间 |
language |
JSON对象 | 语言检测信息 |
fps |
整数 | 每秒帧数 |
resolution |
字符串 | 视频分辨率(例如:1080x1920) |
duration_ms |
整数 | 视频时长(毫秒) |
is_ai_generated |
布尔值 | 视频是否被标记为AI生成 |
is_ad |
布尔值 | 视频是否为广告 |
互动指标结构
json { "play_count": 8948070, "like_count": 789584, "comment_count": 1451, "share_count": 38604, "collect_count": 126905, "repost_count": 0, "download_count": 235172, "whatsapp_share_count": 15737 }
评论结构
comments数组中的每条评论包含:
json
{
"cid": "7352452026457342726",
"text": "Comment text here",
"create_time": 1711876158,
"like_count": 885,
"reply_count": 9,
"username": "commenter_username",
"user_region": "MX",
"language": "es"
}
语言结构
json { "desc_language": "es", "sticker_language": "en", "region": "US", "author_region": "US", "original_audio_language": null }
数据收集方法
视频通过Shofo的TikTok索引流程收集:
- 发现:通过探索/利用策略从种子账户滚雪球式地发现创作者和主题标签。
- 索引:通过TikTok API获取视频元数据。
- 转录:使用自动语音识别(ASR)转录音频。
- 去重:使用基于Redis的ID跟踪对视频进行去重。 该子集是从更大索引中精心挑选的样本,注重数据质量和多样性。
使用方式
使用HuggingFace Datasets库
python from datasets import load_dataset ds = load_dataset("Shofo/shofo-tiktok-general-small", split="train") sample = ds[0] print(sample["transcript"]) print(sample["description"]) print(sample["engagement_metrics"])
使用Pandas
python import pandas as pd df = pd.read_parquet("hf://datasets/Shofo/shofo-tiktok-general-small/metadata.parquet") popular = df[df[engagement_metrics].apply(lambda x: x[play_count] > 1000000)]
访问视频
视频存储在videos/目录中,通过file_name列链接:
python
from datasets import load_dataset
ds = load_dataset("Shofo/shofo-tiktok-general-small", split="train")
video_path = ds[0]["file_name"] # 例如:"videos/7350916080610643231.mp4"
重要说明
- 压缩:TikTok自动对其视频使用H264压缩,实现约50倍的轻微有损压缩。
- 互动指标:数值为索引时的数据。
- 评论:索引时的前50条评论。
- 空值:某些字段可能为空(例如:无语音时
transcript为空,无叠加文本时sticker_text为空)。
更大版本
此数据集为Shofo TikTok数据集的“小型”版本。提供更大版本:
- Shofo TikTok General (Medium):1000万+视频
- Shofo TikTok General (Large):1亿+视频
引用
bibtex @dataset{shofo_tiktok_general_small_2025, title={Shofo TikTok General (Small)}, author={Shofo}, year={2025}, url={https://huggingface.co/datasets/Shofo/shofo-tiktok-general-small} }