DualAlign Benchmark
收藏arXiv2025-11-25 更新2025-11-26 收录
下载链接:
https://limuloo.github.io/BideDPO/
下载链接
链接失效反馈官方服务:
资源简介:
DualAlign基准是由浙江大学与华为技术有限公司联合构建的评估数据集,专门用于测试条件图像生成模型在文本提示与条件输入冲突时的对齐能力。该数据集包含多种条件模态下的冲突案例,通过自动化流水线生成解耦的偏好对数据,每个样本均经过视觉语言模型验证确保质量。数据集主要应用于多约束条件图像生成领域,旨在解决文本语义与条件先验之间的输入级冲突和模型偏差冲突,提升生成模型在复杂场景下的可控性。
提供机构:
浙江大学, 哈佛大学, 华为技术有限公司
创建时间:
2025-11-25
原始信息汇总
BideDPO 数据集概述
数据集名称
BideDPO
核心方法
- 构建双向解耦偏好对(文本偏好对和条件偏好对)
- 采用自适应损失平衡避免梯度纠缠
- 集成VLM检查的自驱动数据管道生成冲突感知数据对
- 采用迭代优化策略同步优化模型和数据
技术特点
- 解决输入级冲突(条件图像语义与文本提示矛盾)
- 解决模型偏置冲突(生成偏置阻碍对齐)
- 支持多约束对齐任务
- 在文本成功率和条件遵循度方面取得显著提升
评估基准
- DualAlign基准:专门评估文本与条件冲突解决能力
- COCO数据集验证:证明在多约束对齐下的鲁棒性
性能表现
- 文本成功率提升35%
- 在常见模态上实现条件遵循度的显著增益
- 在COCO数据集上验证了鲁棒性
资源状态
- 论文状态:预印本
- 代码仓库:https://github.com/limuloo/BideDPO
- 模型、代码和基准将发布
引用格式
bibtex @article{bidedpo2025, title = {BideDPO: Conditional Image Generation with Simultaneous Text and Condition Alignment}, author = {To be updated}, journal = {arXiv preprint arXiv:xxxx.xxxxx}, year = {2025} }
搜集汇总
数据集介绍
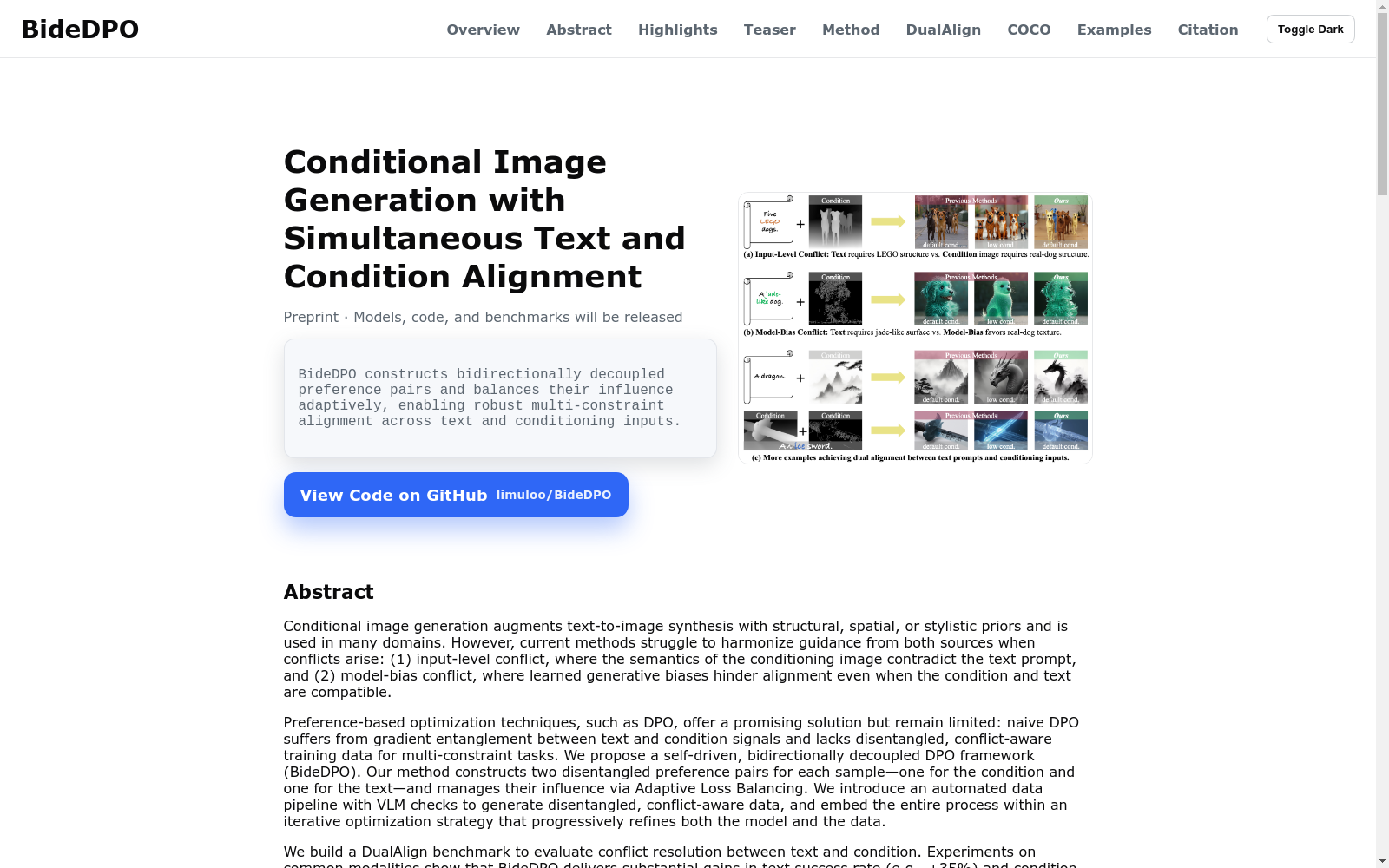
构建方式
在条件图像生成领域,DualAlign Benchmark的构建采用了自动化数据生成流程,通过大型语言模型生成基础源提示词与详细目标提示词,并利用条件提取器从初始图像中获取结构条件图。该流程通过视觉语言模型验证生成样本与文本描述的匹配度,构建解耦的偏好对数据,分别针对文本对齐和条件对齐进行优化。整个数据生成过程形成了自驱动的迭代优化循环,能够系统性地生成包含文本与条件冲突的高质量训练数据。
使用方法
研究者在应用该数据集时,首先利用其解耦的偏好对数据训练双向解耦的DPO模型。通过自适应损失平衡策略动态调整文本对齐和条件对齐的优化权重,确保模型在冲突场景下实现平衡的约束满足。数据集支持迭代优化流程,研究者可以交替进行数据生成和模型训练,形成自增强的优化循环,持续提升模型在复杂多约束条件下的生成能力。
背景与挑战
背景概述
DualAlign Benchmark由浙江大学、哈佛大学与华为技术有限公司的研究团队于2025年提出,聚焦于条件图像生成领域中的多约束对齐问题。该数据集旨在解决文本提示与条件输入(如深度图、边缘结构或风格参考)之间的语义冲突,通过构建双向解耦的偏好对数据,推动生成模型在复杂场景下的可控性研究。其创新性在于首次系统化定义了输入级冲突与模型偏置冲突两类核心问题,为多目标优化提供了标准化评估框架,显著提升了生成图像在语义一致性与结构保真度方面的性能。
当前挑战
DualAlign Benchmark面临双重挑战:在领域问题层面,需解决文本与条件信号冲突时的动态权衡问题,例如模型在‘乐高结构狗’与真实狗轮廓的对抗性输入中需保持双重对齐;在构建过程中,缺乏现成的解耦偏好数据,需通过自动化流水线迭代生成冲突感知样本,并克服视觉语言模型评分与生成器偏差的耦合干扰。此外,梯度纠缠问题使传统优化方法难以平衡文本成功率与条件约束强度,需设计自适应损失平衡机制以协调多目标学习。
常用场景
经典使用场景
在条件图像生成领域,DualAlign Benchmark作为评估模型在文本提示与条件输入冲突场景下性能的专业测试平台。该数据集通过构建文本语义与条件图像相互矛盾的样本对,系统评估生成模型在输入级冲突和模型偏置冲突两种典型场景中的表现。研究人员利用这一基准测试不同条件生成方法在深度图、Canny边缘和软边缘等多种模态下的双重对齐能力,为模型优化提供精确的性能度量。
解决学术问题
该数据集有效解决了条件图像生成中文本与条件信号难以协同优化的核心学术难题。通过构建冲突感知的评估框架,它帮助研究者突破传统监督微调在多重约束平衡上的局限性,为偏好优化算法在多目标对齐任务中的应用提供验证基础。其意义在于首次系统化定义了文本-条件对齐冲突的评估标准,推动生成模型从单一约束满足向多约束协同优化的范式转变,为可控图像生成的理论发展奠定重要基石。
实际应用
在实际应用层面,DualAlign Benchmark为数字艺术创作和工业设计软件提供了关键的评估工具。设计人员可利用该基准测试生成模型在复杂提示条件下的稳定性,确保设计稿在保持结构约束的同时准确呈现创意描述。游戏开发领域借助该数据集验证场景生成模型在风格迁移与空间布局双重需求下的可靠性,显著提升虚拟场景构建的效率与质量,推动AIGC技术在创意产业中的落地应用。
数据集最近研究
最新研究方向
在条件图像生成领域,DualAlign Benchmark的提出标志着对文本与条件输入间冲突问题的系统化探索。当前研究聚焦于解决输入级冲突与模型偏置冲突两大挑战,前者源于条件图像语义与文本提示的矛盾,后者则因生成模型的固有偏好导致文本对齐不足。前沿工作如BideDPO框架通过双向解耦的偏好优化机制,构建分离的文本与条件对齐目标,结合自适应损失平衡策略,显著提升了多约束场景下的生成质量。这一方向不仅推动了可控图像生成的技术边界,更在数字艺术与设计等实际应用中展现出深远影响,为处理复杂多模态约束提供了可扩展的解决方案。
相关研究论文
- 1BideDPO: Conditional Image Generation with Simultaneous Text and Condition Alignment浙江大学, 哈佛大学, 华为技术有限公司 · 2025年
以上内容由遇见数据集搜集并总结生成


