有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
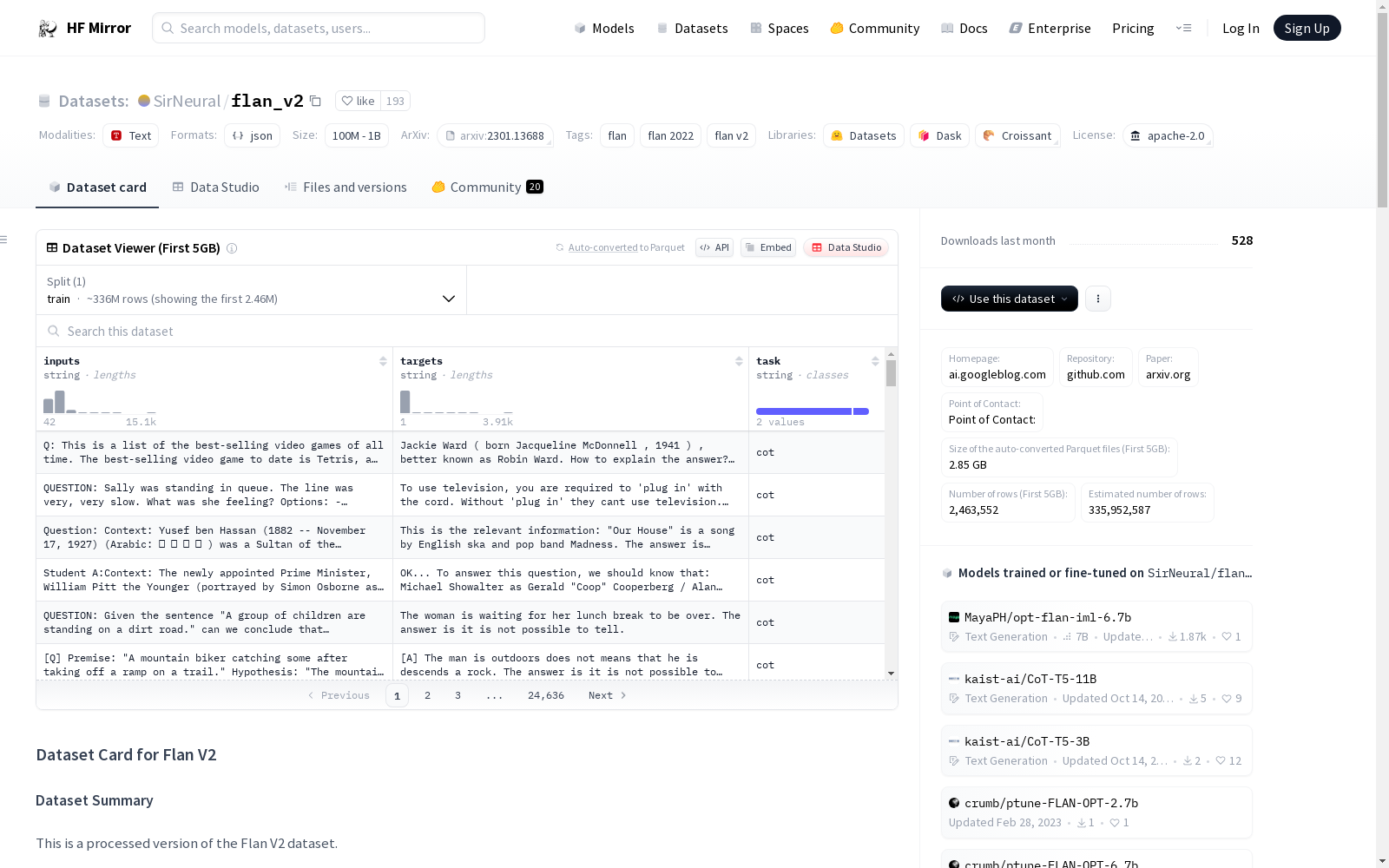
数据集名称: Flan v2
许可证: Apache-2.0
标签:
美观名称: Flan v2
数据集总结:
数据结构:
cat flan_fs_opt_train_*.gz | gunzip -c > flan_fs_opt_train.jsonl。数据集格式: 每个任务+格式的组合保存为JSONL格式,具有以下架构:{"input": ..., "target": ..., "task": ...}。
Paper III (Walker et al. 2024)
Data products used in 3-D CMZ Paper III, Walker et al. (2024). The full cloud catalogue is provided in tabular format, along with a full CMZ map showing the clouds and their assigned IDs. For each cloud ID in the published catalogue there are: - Individual cube cutouts from the MOPRA 3mm CMZ survey (HC3N, HCN, and HNCO). - Individual cube cutouts from the APEX 1mm CMZ survey (13CO, C18O, and H2CO). - Cloud-averaged spectra of the ATCA H2CO 4.83 GHz line. - PV slices of the ATCA H2CO 4.83 GHz line, taken across the major axis of the source. - Where applicable, there are mask files which correspond to the different velocity components of the cloud. In these cases, there are two mask files per velocity component, corresponding to the different masking approaches described in the paper.
DataCite Commons 收录
Breast Cancer Dataset
该项目专注于清理和转换一个乳腺癌数据集,该数据集最初由卢布尔雅那大学医学中心肿瘤研究所获得。目标是通过应用各种数据转换技术(如分类、编码和二值化)来创建一个可以由数据科学团队用于未来分析的精炼数据集。
github 收录
PDT Dataset
PDT数据集是由山东计算机科学中心(国家超级计算济南中心)和齐鲁工业大学(山东省科学院)联合开发的无人机目标检测数据集,专门用于检测树木病虫害。该数据集包含高分辨率和低分辨率两种版本,共计5775张图像,涵盖了健康和受病虫害影响的松树图像。数据集的创建过程包括实地采集、数据预处理和人工标注,旨在为无人机在农业中的精准喷洒提供高精度的目标检测支持。PDT数据集的应用领域主要集中在农业无人机技术,旨在提高无人机在植物保护中的目标识别精度,解决传统检测模型在实际应用中的不足。
arXiv 收录
双色球开奖号码数据集
双色球开奖号码数据集从2003001-2025011
魔搭社区 收录
🌧️ Digital Typhoon Dataset WP (GIFs| 57GB)
🌧️ Digital Typhoon Dataset Western Pacific (Animated GIFs)
kaggle 收录