empathetic-dialogues
收藏Hugging Face2025-11-10 更新2025-11-10 收录
下载链接:
https://huggingface.co/datasets/anezatra/empathetic-dialogues
下载链接
链接失效反馈官方服务:
资源简介:
EmpatheticDialogues是一个大规模的开放领域对话数据集,旨在帮助AI系统更自然地识别、理解和响应人类情感。该数据集包含超过65,000条话语,跨越27,000多个对话,每个对话都基于情感丰富的情境,以支持AI模型发展类似人类的感知和表达同情的能力,进而促进情感感知对话AI的研究。
EmpatheticDialogues is a large-scale open-domain dialogue dataset aimed at helping AI systems naturally recognize, understand, and respond to human emotions. This dataset contains over 65,000 utterances spanning more than 27,000 dialogues, each of which is based on emotion-rich contexts. It is designed to enable AI models to develop human-like emotional perception and empathy-expressing capabilities, thereby advancing research on emotion-aware conversational AI.
创建时间:
2025-11-08
原始信息汇总
Empathetic Dialogues 数据集概述
数据集简介
EmpatheticDialogues是一个大规模开放领域对话数据集,旨在帮助AI系统更自然地识别、理解并回应人类情感。该数据集为共情对话生成提供了新的基准,包含超过27,000个对话中的65,000余条话语,所有对话均基于情感丰富的情境构建,捕捉真实的情感体验和反应。
数据特征
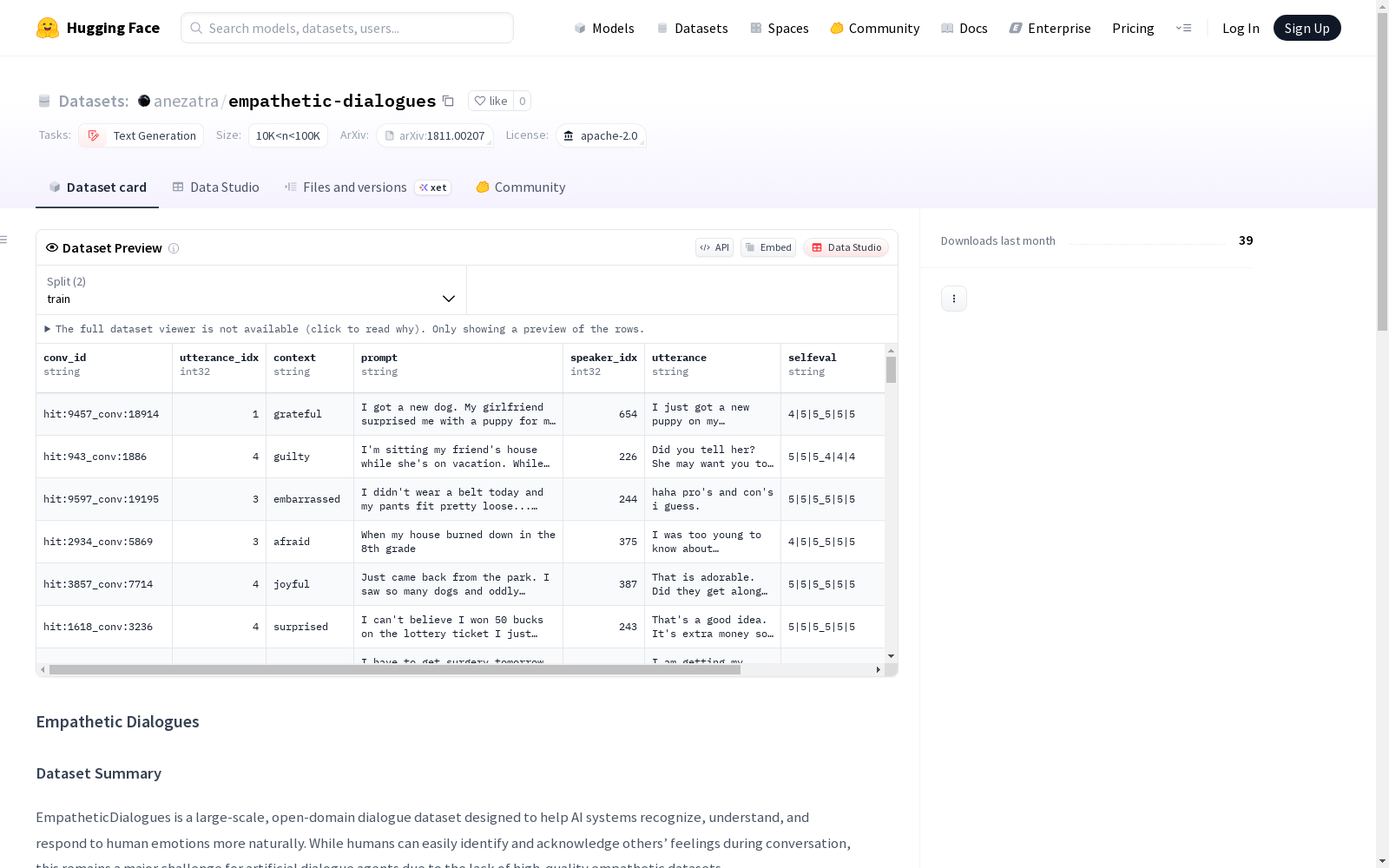
- 数据格式:包含8个字段的结构化数据
- 主要字段:
- conv_id:对话唯一标识符
- utterance_idx:话语在对话中的索引
- context:当前话语前的对话上下文
- prompt:可选的话语关联提示
- speaker_idx:说话者索引(0或1)
- utterance:当前话语文本
- selfeval:可选的自评或标注
- tags:额外标签或元数据
数据规模
- 总数据量:18,954,220字节
- 总话语数:76,673条
- 训练集:65,172个样本,16,044,549字节
- 验证集:11,501个样本,2,909,671字节
技术规格
- 许可证:Apache-2.0
- 任务类别:文本生成
- 规模分类:10K<n<100K
- 下载大小:10,081,359字节
使用方式
python from datasets import load_dataset ds = load_dataset("anezatra/empathetic-dialogues", split="train")
参考文献
Rashkin, H., Smith, E. M., Li, M., & Boureau, Y. L. (2018). Towards empathetic open-domain conversation models: A new benchmark and dataset. arXiv preprint arXiv:1811.00207. (https://arxiv.org/abs/1811.00207)
搜集汇总
数据集介绍
构建方式
在情感计算与人机交互领域,EmpatheticDialogues数据集通过精心设计的众包对话采集流程构建而成。参与者被要求基于特定情感情境展开自然对话,每个对话均围绕真实的情感体验展开,确保语料的情感真实性与多样性。数据收集过程中严格记录对话轮次、说话者身份及上下文信息,最终形成包含超过65,000条语句的大规模语料库,为情感对话研究提供了扎实的数据基础。
特点
该数据集最显著的特征在于其深度情感标注与结构化对话架构。每条对话记录均包含完整的情感上下文、说话者轮换信息及自评估标签,呈现多维度情感交互模式。数据覆盖27,000余个独立对话场景,涵盖广泛的情感类型与社交情境,其细粒度的情感标签体系为模型理解复杂情感动态提供了独特优势。这种精心设计的结构使得数据集成为训练具有共情能力对话系统的理想资源。
使用方法
研究者可通过HuggingFace数据集库直接加载该数据集,使用标准接口获取训练集与验证集分割。典型应用流程包括:基于对话历史预测情感回应、训练端到端的共情对话生成模型,或进行情感识别任务的迁移学习。数据集的标准化字段设计支持灵活的特征提取,例如结合context字段建模对话流,利用utterance字段训练生成模型,其清晰的数据结构为各类自然语言处理实验提供了便利条件。
背景与挑战
背景概述
在人工智能对话系统的发展历程中,情感理解一直是实现自然交流的核心瓶颈。Empathetic Dialogues数据集由Rashkin等人于2018年创建,旨在解决开放域对话中情感认知的缺失问题。该数据集通过收集超过2.7万组涵盖多元情感场景的对话,为情感对话生成研究建立了重要基准。其创新性地将心理学中的共情机制引入人工智能领域,推动了情感计算与对话系统的交叉研究,成为开发具有情感感知能力对话模型的关键基础设施。
当前挑战
情感对话建模面临双重挑战:在领域问题层面,模型需同时处理语义连贯性与情感适配性,既要准确识别复杂情感状态,又要生成符合特定情感语境的自然回应;在数据构建层面,标注者需要精准捕捉对话中隐含的情感维度,且需保持情感表达与对话逻辑的内在一致性。此外,数据采集过程中还需克服情感标签主观性强、多轮对话中情感状态动态演变等技术难点,这些因素共同构成了情感对话系统发展的核心障碍。
常用场景
经典使用场景
在情感智能对话系统研究中,EmpatheticDialogues数据集常被用于训练模型识别和生成具有共情能力的对话。该数据集通过超过2.7万组涵盖丰富情感情境的对话,为模型提供了学习人类情感表达模式的基准环境,尤其适用于评估对话系统在理解愤怒、喜悦或悲伤等情绪时的响应质量。
实际应用
基于该数据集开发的系统已应用于心理健康辅助对话机器人、智能客服情感交互等场景。例如在心理咨询平台中,模型通过学习数据集中共情表达模式,能够对用户的情绪困扰作出更人性化的回应,有效提升人机交互的情感连接质量。
衍生相关工作
该数据集启发了多项经典研究,如基于Transformer的情感对话生成框架、结合强化学习的共情响应优化方法等。后续工作进一步扩展了多模态情感对话数据集构建,推动了情绪感知对话系统在个性化服务与教育支持等方向的发展。
以上内容由遇见数据集搜集并总结生成


