DRAGON
收藏arXiv2025-05-16 更新2025-05-20 收录
下载链接:
https://huggingface.co/datasets/lesc-unifi/dragon
下载链接
链接失效反馈官方服务:
资源简介:
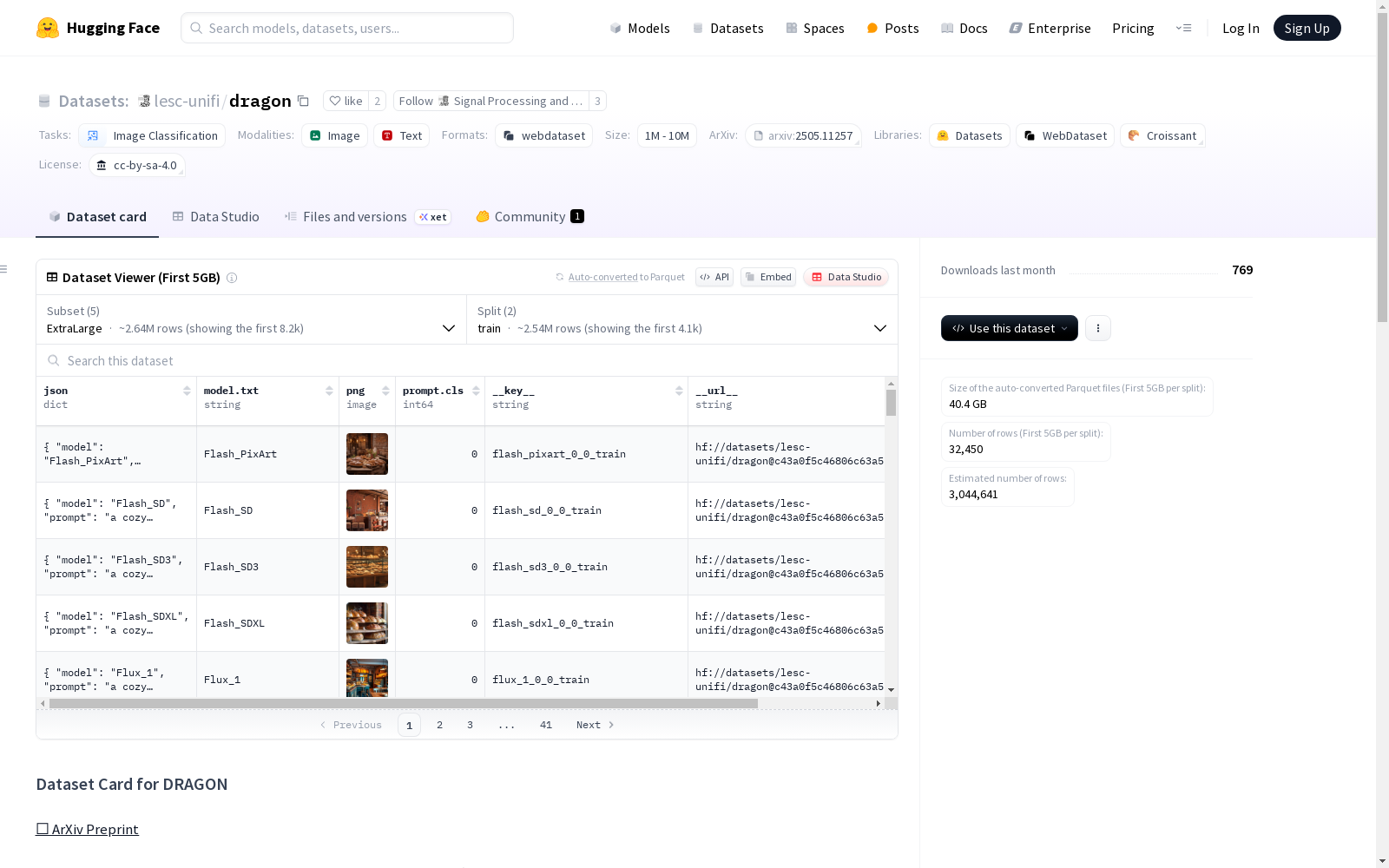
DRAGON数据集是迄今为止规模最大、最多样化的扩散模型检测和归因任务数据集,包含由25个不同的扩散模型生成的260万个合成图像,以及从ImageNet获取的133万个真实图像。数据集已预分为训练集和测试集,并组织为五个子集,每个子集包含不同数量的图像,以满足各种研究场景的需求。数据集的创建旨在支持研究人员开发用于分析可能由扩散模型生成的图像的方法,并解决数字取证社区近年来出现的重大挑战。此外,数据集还包含一个专门的测试集,旨在作为评估新开发方法的基准。
The DRAGON dataset is the largest and most diverse dataset to date for diffusion model detection and attribution tasks, containing 2.6 million synthetic images generated by 25 distinct diffusion models and 1.3 million real images sourced from ImageNet. The dataset is pre-split into training and test sets, and organized into five subsets with varying numbers of images to meet the needs of diverse research scenarios. It was developed to support researchers in developing methods for analyzing images potentially generated by diffusion models, and to address major challenges that have emerged in the digital forensics community in recent years. Additionally, the dataset includes a dedicated test set intended as a benchmark for evaluating newly developed methods.
提供机构:
佛罗伦萨大学信息工程系
创建时间:
2025-05-16
原始信息汇总
DRAGON 数据集概述
基本信息
- 名称: DRAGON (Dataset of Realistic imAges Generated by diffusiON models)
- 许可证: Creative Commons Attribution Share Alike 4.0 International (cc-by-sa-4.0)
- 任务类别: 图像分类 (image-classification)
- 数据规模: 1M < n < 10M
- 数据集大小: 250万训练图像 + 10万测试图像
- 生成模型数量: 25种扩散模型
数据集描述
- 目的: 支持开发多媒体取证工具,专注于合成图像检测和模型归属任务
- 特点:
- 包含多样化主题的合成图像
- 提供多种规模子集(从XS到XL)
- 包含专门设计的测试集作为标准化基准
数据集结构
- 标注信息: 每张图像标注了生成模型和输入提示
- 生成方式:
- 基于1,000个ImageNet类别生成提示
- 每个模型每个提示生成100张训练图像和4张测试图像
子集规模
| 子集名称 | 训练图像数量 | 测试图像数量 | 提示数量 |
|---|---|---|---|
| ExtraSmall (XS) | 250 | 1,000 | 10 |
| Small (S) | 2,500 | 10,000 | 100 |
| Regular (R) | 25,000 | 10,000 | 100 |
| Large (L) | 250,000 | 100,000 | 1,000 |
| ExtraLarge (XL) | 2,500,000 | 100,000 | 1,000 |
文件配置
- ExtraSmall:
- 训练: train/xs/dragon_train_xs.tar
- 测试: test/dragon_test_00.tar
- Small:
- 训练: train/dragon_train_000.tar
- 测试: test/dragon_test_0?.tar
- Regular:
- 训练: train/dragon_train_00?.tar
- 测试: test/dragon_test_0?.tar
- Large:
- 训练: train/dragon_train_0??.tar
- 测试: test/dragon_test_??.tar
- ExtraLarge:
- 训练: train/dragon_train_???.tar
- 测试: test/dragon_test_??.tar
引用信息
bibtex @misc{bertazzini2025dragon, title={DRAGON: A Large-Scale Dataset of Realistic Images Generated by Diffusion Models}, author={Giulia Bertazzini and Daniele Baracchi and Dasara Shullani and Isao Echizen and Alessandro Piva}, year={2025}, eprint={2505.11257}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2505.11257}, }
联系方式
- Giulia Bertazzini: giulia.bertazzini@unifi.it
- Daniele Baracchi: daniele.baracchi@unifi.it
搜集汇总
数据集介绍
构建方式
DRAGON数据集的构建采用了多模态生成模型与大规模语言模型协同工作的创新方法。研究团队精选了25种扩散模型,涵盖从经典架构到最新技术的完整谱系。通过基于ImageNet的1000个类别标签,利用Phi-3大型语言模型进行提示词扩展,显著提升了生成图像的语义丰富度和视觉真实感。数据生成过程采用HuggingFace的diffusers库,在NVIDIA A100集群上耗费约5,300 GPU小时完成全量生成,确保所有图像均标注完整的生成参数和随机种子。
特点
该数据集最显著的特点是实现了规模性与多样性的双重突破:包含260万张合成图像及133万张真实图像,覆盖25种扩散模型的最新变体。通过创新的提示词扩展技术,其图像质量在MPS指标上达到14.02分,远超现有基准数据集。数据组织采用五级分层结构(XS-XL),支持从少样本学习到大规模训练的各类研究场景。特别设计的专用测试集包含10万张图像,为检测算法提供标准化评估基准。
使用方法
研究者可通过HuggingFace平台直接访问该数据集,按需选择不同规模的分层子集。训练集与测试集的预设分割简化了实验流程,而配套的元数据(生成模型、提示词、随机种子)支持细粒度的归因分析。建议使用场景包括:开发跨模型泛化的检测算法、研究不同架构的指纹特征、评估方法在压缩/缩放等退化条件下的鲁棒性。数据集特别适用于探究高真实感合成图像的鉴别特征。
背景与挑战
背景概述
DRAGON数据集由佛罗伦萨大学信息工程系的研究团队于2025年提出,旨在应对扩散模型生成图像检测领域的关键挑战。作为目前规模最大、模型覆盖最全面的合成图像数据集,它整合了25种扩散模型生成的260万张图像,涵盖从经典架构到最新技术的完整谱系。该数据集创新性地采用基于大语言模型的提示扩展技术,显著提升了生成图像的视觉真实感,其多维偏好评分(MPS)达到14.02,远超同类数据集。DRAGON的建立为多媒体取证领域提供了至关重要的基准测试平台,特别是在虚假信息检测和模型溯源等研究方向具有里程碑意义。
当前挑战
DRAGON数据集面临的核心挑战体现在两个维度:在技术层面,现有检测方法对快速迭代的扩散模型泛化能力不足,传统基于生成对抗网络的检测技术在面对扩散模型生成的细微痕迹时性能显著下降;在数据集构建层面,保持数据时效性与模型覆盖广度存在固有矛盾,早期收集的样本在新模型出现后迅速过时。此外,提升图像真实感与保留可检测特征之间存在张力,过度优化的生成质量可能削弱取证线索,而低质量样本又无法反映真实攻击场景。数据多样性方面,如何平衡开放权重模型与商业模型的比例,以及处理ImageNet标签的语义局限性,都是构建过程中需要持续优化的难题。
常用场景
经典使用场景
DRAGON数据集作为当前规模最大、覆盖模型最广的扩散模型生成图像数据集,其经典使用场景主要集中在多媒体取证领域的研究与开发。该数据集通过整合25种主流及新兴扩散模型生成的260万张高质量合成图像,为检测算法提供了丰富的训练样本和基准测试环境。研究人员可利用其预分割的训练集和测试集,系统评估检测模型在跨模型泛化性、鲁棒性等方面的表现,特别是在应对快速迭代的生成模型时展现出的适应性。
实际应用
在实际应用层面,DRAGON数据集为构建新一代数字内容认证系统提供了核心支撑。网络安全机构可基于该数据集开发的检测模型,有效识别社交媒体传播的AI生成虚假信息;司法鉴定领域可利用其丰富的模型指纹特征,追踪特定政治谣言或商业欺诈内容的生成源头;互联网平台则可通过集成相关技术,实现用户上传内容的自动筛查。特别值得注意的是,数据集包含的JPEG压缩版本和降分辨率测试集,使开发的检测工具能适应网络传输带来的图像质量损失。
衍生相关工作
该数据集已催生多个具有影响力的衍生研究方向:基于频谱特征分析的模型溯源方法通过挖掘不同扩散模型在傅里叶域的独特指纹;提示词工程与图像质量关联研究揭示了语言模型优化对生成内容真实性的提升机制;DE-FAKE等检测框架在DRAGON上重训练后准确率提升11.8%,推动了多模态取证技术的发展。后续研究进一步扩展了其在生成模型安全评估、数字水印等交叉领域的应用。
以上内容由遇见数据集搜集并总结生成


